RapidChain: scaling blockchain via full sharding Zamani et al., CCS’18
RapidChain is a sharding-based public blockchain protocol along the lines of OmniLedger that we looked at earlier in the year. RapidChain is resilient to Byzantine faults from up to 1/3 of its participants, requires no trusted setup, and can achieve more than 7,300 tx/sec with an expected confirmation latency of roughly 8.7 seconds in a network of 4,000 nodes with a time-to-failure of more than 4,500 years. Those are pretty interesting numbers!

(Enlarge)
RapidChain partitions the set of nodes into multiple smaller groups of nodes called committees that operate in parallel on disjoint blocks of transactions and maintain disjoint ledgers.
With 


- A way to bootstrap the initial system
- A way of forming (and re-forming) committees, and allowing nodes to join and leave
- A way of reaching consensus within a committee (shard)
- A way of verifying transactions which cross-shards
Bootstrapping
The initial set of participants start RapidChain by running a committee election protocol which elects a group of 


You’ll find details of this in the (somewhat oddly placed!) section 5.1 of the paper (section 5 is ‘Evaluation’). The initial set of participants are known and all have the same hard-coded seed and knowledge of the network size. Each participant creates a a random ‘sampler graph’ containing a group of nodes. Within each group nodes compute the hash 




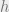
Committee reconfiguration
Partitioning the nodes into committees for scalability introduces a new challenge when dealing with churn. Corrupt nodes could strategically leave and rejoin the network, so that eventually they can take over one of the committees and break the security guarantees of the protocol. Moreover, the adversary can actively corrupt a constant number of uncorrupted nodes in every epoch even if no nodes join/rejoin.
The first defence is a ‘pay-to-play’ scheme. In each epoch, every node that wants to join or stay in the protocol must solve a PoW puzzle. A fresh puzzle is randomly generated every epoch (using a verifiable secret sharing distributed random generation protocol), and the reference committee checks the PoW solutions of all nodes. The result is a reference block created at the start of an epoch with the list of all active nodes and their assigned committees. This reference block is sent to all the other committees.
The second defence makes it hard for an adversary to target an given committee using selective random shuffling based on the Cuckoo rule. When nodes are mapped into committees, each is first assigned a random position in [0, 1) using a hash function. The range [0, 1) is then partitioned into k regions of size 


When a node joins a committee it needs to download only the set of unspent transactions (UTXOs) from a sufficient number of committee numbers, in order to be able to verify future transactions. (As compared to needing to download the full chain).
Consensus within committees
Committee consensus is built on a gossiping protocol to propagate messages among committee members, and a synchronous consensus protocol to agree on the header of the block.
The gossip protocol is inspired by information dispersal algorithms. A large message M is cut into n equal size chunks and an erasure coding scheme is used to obtain an additional parity chunk. Make a Merkle tree using these chunks as leaves, and then send a unique subset of the chunks to each neighbour together with their Merkle proofs. These neighbours gossip chunks received to their neighbours, and so-on. Once a node has received n valid chunks it reconstructs the message.
Our IDA-Gossip protocol is not a reliable broadcast protocol as it cannot prevent equivocation by the sender. Nevertheless, IDA-Gossip requires much less communication and is faster than reliable broadcast protocols to propagate large blocks of transactions (about 2MB in RapidChain). To achieve consistency, we will later run a consensus protocol only on the root of the Merkle tree after gossiping the block.
RapidChain uses a variant of Abraham et al.’s Efficient Synchronous Byzantine Consensus protocol. The protocol commits messages at a fixed rate, around 600ms in practice. The message rate is calibrated once a week. In each epoch a committee leader is randomly chosen using the epoch randomness. The leader gathers all the transactions it has received in a block and gossips it. Then it starts the consensus protocol by gossiping a message containing the block header (iteration number and Merkle root) with a propose tag. The other committee members echo this header upon receipt by gossiping it with an echo tag. Thus all honest nodes see all versions of the header received by all other honest nodes. If an honest node receives more than one version of the header for the same iteration it knows something is up and gossips a header with a null Merkle root and the tag pending. Otherwise if an honest node receives 
Inter-committee routing and cross-shard transactions
With a sharded blockchain, verification of transactions whose inputs and outputs span multiple shards (committees) require cross-shard coordination. A transaction is stored in the ledger of one committee, called the output committee, and that ledger (shard) is selected based on the hash of the transaction id. The inputs to the transaction (UTXOs) may be stored by other committees (input committees).
The user can communicate with any committee, who routes the transaction to the output committee via the inter-committee routing protocol (described next). The output committee creates one transaction for each input and sends it to the appropriate input committee. Each such transaction has one input 

Inter-committee routing is based on the Kademlia routing algorithm. Each committee node stores information about all members of its committee as well as about 

Each committee-to-committee message is implemented by having all nodes in the sender committee send the message to all nodes they know in the receiver committee. Each node who receives a message invokes the IDA-gossip protocol to send the message to all other members of its committee.
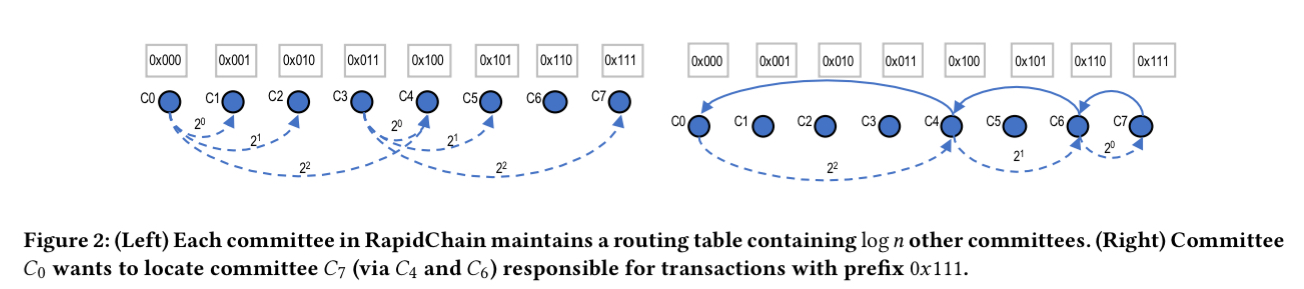
Evaluation
A RapidChain prototype is built in Go and networks of up to 4,000 nodes are simulated on a set of 32 machines. Through experimentation, a block size of 2MB is set, which gives a latency of less than 10 seconds, matching mainstream payment systems. At this block size throughput is more than 7,000 tx/second and latency is roughly 8.7 seconds.
The following chart shows throughput and latency achieved at varying numbers of nodes:
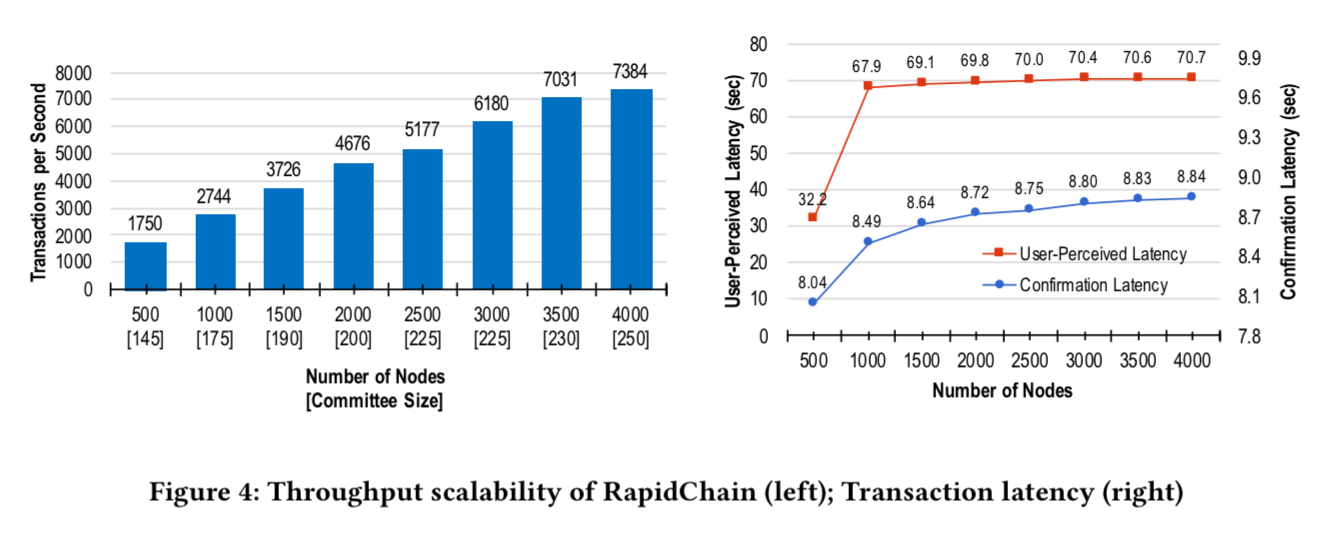
RapidChain’s user-perceived latency stays stable at around 70 seconds as the network scales.
Section 6 in the paper, which we haven’t had space to cover here, contains a security and performance analysis for the RapidChain protocols.
Rapid Chain is the first 1/3-resilient sharding-based blockchain protocol that is highly scalable to large networks… our empirical evaluation demonstrates that RapidChain scales smoothly to network sizes of up to 4,000 nodes showing better performance than previous work.

{kind=link}
Sharding is an amazing technology that can revolutionize the blockchain technology in terms of scalability and interoperability.
Thanks for sharing this informative guide. I hope Side chain will resolve the issue with scalability.