NAVEX: Precise and scalable exploit generation for dynamic web applications Alhuzali et al., USENIX Security 2018
NAVEX (https://github.com/aalhuz/navex) is a very powerful tool for finding executable exploits in dynamic web applications. It combines static and dynamic analysis (to cope with dynamically generated web content) to find vulnerable points in web applications, determine whether inputs to those are appropriately sanitised, and then builds a navigation graph for the application and uses it to construct a series of HTTP requests that trigger the vulnerability.
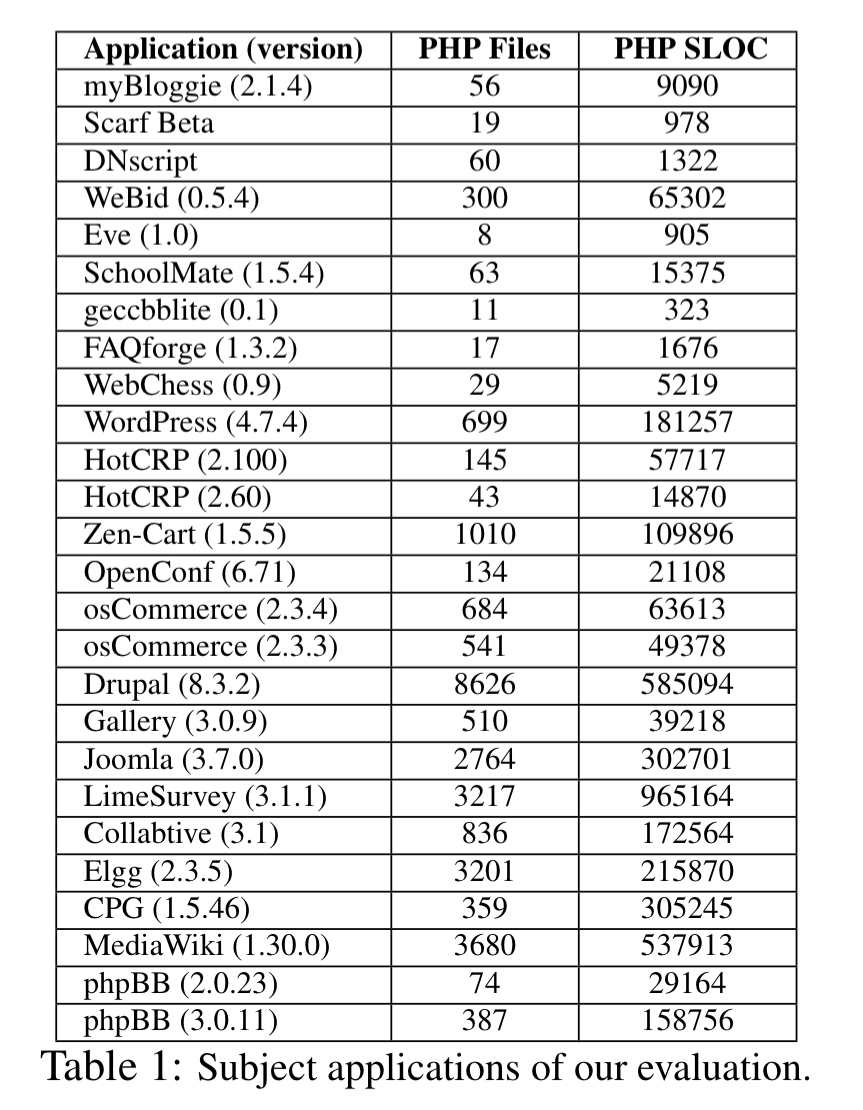
It also works at real-world scale: NAVEX was used on 26 PHP applications with a total of 3.2M SLOC and 22.7K PHP files. It generated 204 concrete exploits across these applications in a total of 6.5 hours. While the current implementation of NAVEX targets PHP applications, the approach could be generalised to other languages and frameworks.
In this paper, our main contribution is a precise approach for vulnerability analysis of multi-tier web applications with dynamic features… our approach combines dynamic analysis of web applications with static analysis to automatically identify vulnerabilities and generate concrete exploits as proof of those vulnerabilities.
Here’s a example of what NAVEX can do. From the 64K SLOC in osCommerce 2.3.4, NAVEX is able to demonstrate a vulnerability in the code below:

Furthermore, it also generates a concrete exploit that successfully triggers the vulnerability:

Challenges
To work its magic, NAVEX has to overcome three main challenges: finding reachable sinks (points of vulnerability), coping with dynamically generated content, and scaling to large code bases.
Finding potentially vulnerable individual statements is not that hard, but figuring out whether those statements can be reached with unsanitised inputs is much more challenging. The analysis has to take into account the data flow paths through the application, as well as the strength of any sanitisation applied to inputs along those paths. We can’t solely use static analysis for this since many applications include significant portions of dynamically generated content. Searching for and generating executable exploits that may span multiple modules, and many execution paths within modules could easily cause a state-space explosion. NAVEX is designed to support aggressive pruning of the search space to maintain scalability.
Identifying vulnerable sinks
The first task is to identify vulnerable sinks in an application. Each module is analysed independently, and only those with potential vulnerabilities will be considered as sinks for further analysis.
NAVEX first builds a graph model of each module’s code, then it discovers the paths that contain data flows between sources and sinks. Finally, it uses symbolic execution to generate a model of the execution as a formula and constraint solving to determine which of those paths are potentially exploitable.
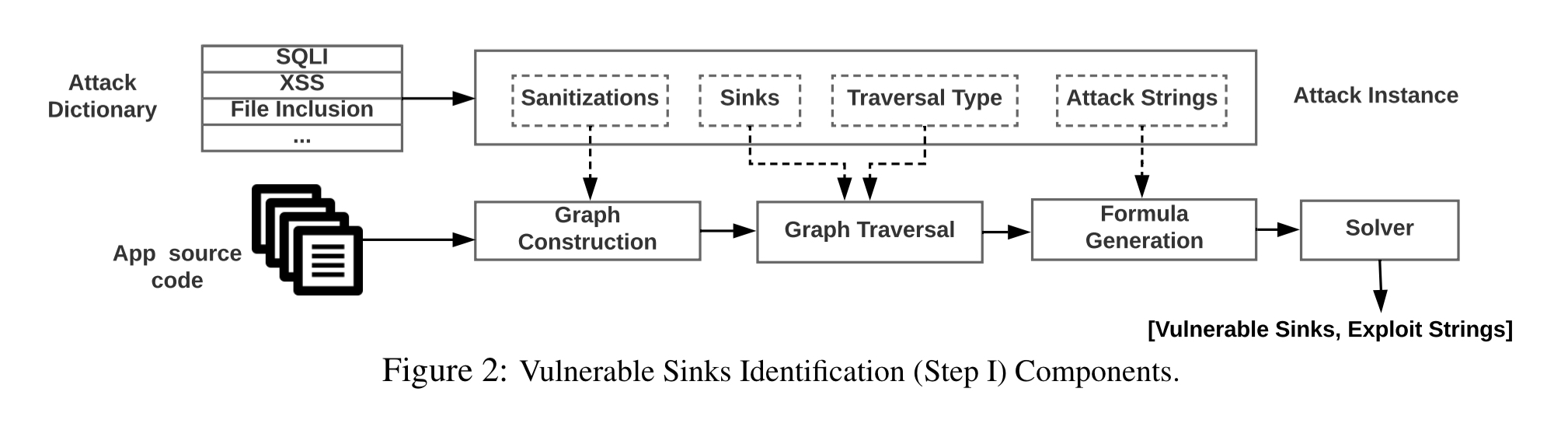
The process starts with an attack dictionary containing analysis templates for a wide range of vulnerabilities. The initial implementation contains templates for SQLI, XSS, file inclusion, command injection, code execution, and EAR (execution-after-redirect) attacks. The attack dictionary can be used to find candidate sinks within modules. The dictionary also includes sanitisation patterns and attack strings for each attack.
The next step is to build a graph model representing the possible execution paths through the application. This is based on Code Property Graphs, which combine ASTs, control-flow graphs, and data dependence graphs. Nodes in the CPG are augmented with sanitisation and database constraint tags. Santisation tags store information about the sanitisation status of each variable at a node. Attribute values are either unsan-X or san-X where X represents a particular vulnerability, e.g. san-sql. Database constraints (e.g. NOT NULL) are gathered from the schema and attached to the root node.
Given the graph and the candidate sink nodes, backwards traversal from a sink node can find vulnerable (unsanitised) paths leading back to a source node. For each node representing a sink, the data dependency edges are followed backwards for all variables used in that sink. If the path leads to a function, then all call sites leading to that function will be analysed. The full algorithm is given below:

In an EAR attack, execution continues after a redirect. To find EAR vulnerabilities NAVEX uses a forwards traversal from sources to sinks, where the sources are redirect instructions.
At this point we have a set of paths through the application that are potentially vulnerable. The final step in the static analysis is to generate exploit strings to use in an attack. Each vulnerable path is modelled as a logical formula together with any constraints derived from the database. This is augmented with information from the attack dictionary with constraints over variables at the sink representing values that can lead to an attack.
The augmented formula (i.e.
is next sent to a solver, which provides a solution (if it exists) over the values of the input variables, that is an exploit string. This solution contains the values of the input variables, which, after the path and sanitizations executions, cause the attack string to appear at the sink.
Generating concrete exploits
Even if the solver is able to spit out an exploit string, it doesn’t necessarily mean that the attack is feasible. The final hurdle is to discover a set of HTTP requests that can be sent to the application to trigger the path and execute the attack described by the exploit string(s).
NAVEX combines crawling with dynamic discovery of server-side constraints to build a navigation graph . From the navigation graph, NAVEX can produce a series of HTTP requests that constitute a concrete exploit for the vulnerable sink.
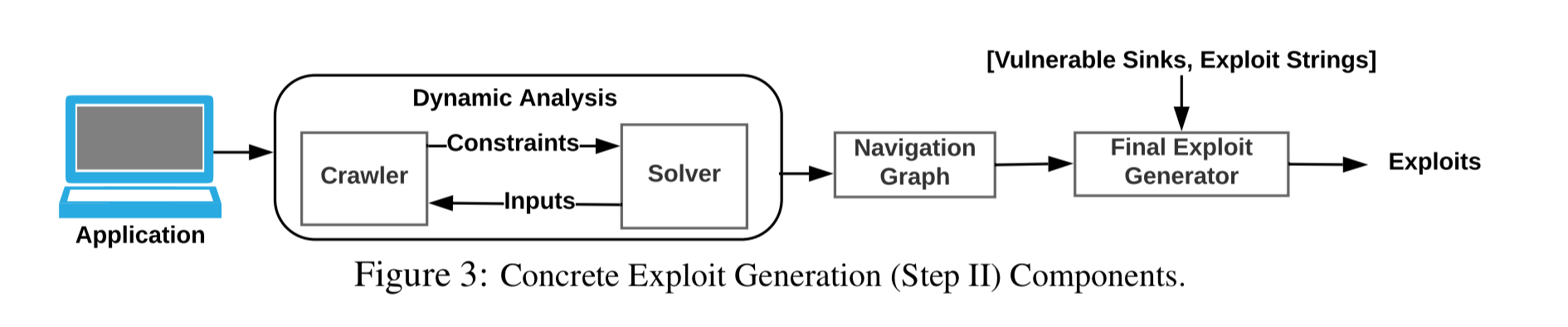
The crawler starts with a set of seed URLs and explores HTML links, forms, and JavaScript code. For valid form submission the crawler extracts the form input fields, buttons, and action and method attributes to generate a set of implied constraints over the form values. JavaScript code is extracted and analysed using concrete symbolic execution:
The code is first executed concretely and when the execution reaches a conditional statement that has symbolic variables, the execution forks. Then, the execution resumes concretely. After the execution stops for all forks, a set of constraints that represent each execution path that returns true is generated.
The resulting formula for the form is sent to the solver to find a solution.
Even with all of this analysis on the client-side, there may be additional server-side constraints not captured by the process as described so far. An example in the paper is a conditional check in the form processing code on the server side on the length of a submitted string (which is not tested for in the client-side validations). Without an understanding of these constraints, we can’t build form submissions that will be accepted. NAVEX uses execution tracing on the server side to see if a form submission was successful, as indicated by a change of state or performance of sensitive operations such as database queries. If a form submission is deemed to have failed, then NAVEX uses the trace to perform concolic execution:
In particular, it first retrieves the executed statements including the conditional statements. Then, the collected conditional statements are transformed automatically to solver specifications and negated to uncover new execution paths. The newly created specifications are then sent to the solver to generate new form inputs. This process is continuously repeated until the form submission is successful.
The end result is a navigation graph such as this:
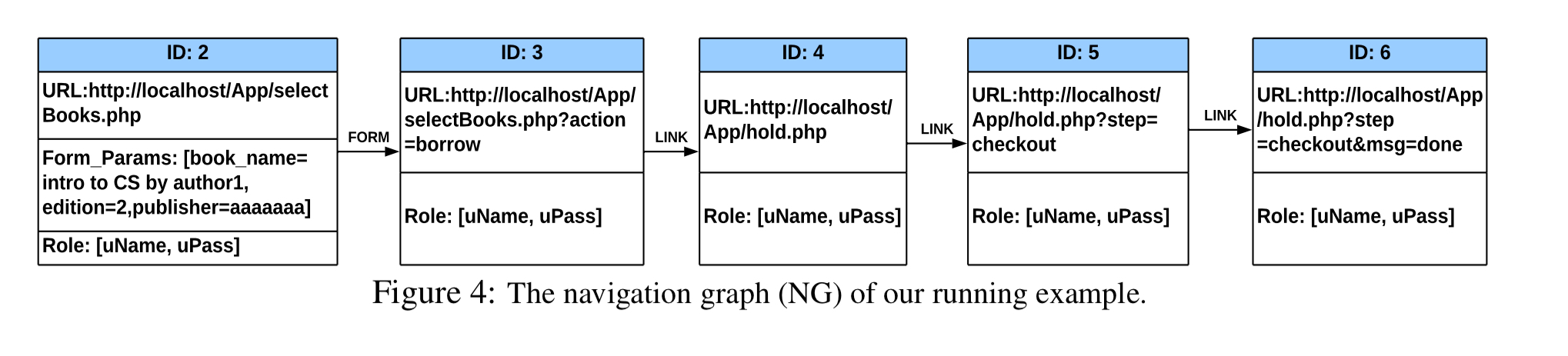
From the graph, NAVEX searches for paths from public endpoints to the exploitable modules. The search algorithm is as follows:

… the challenging problem of finding sequences of HTTP requests that execute an exploit is transformed into a simple graph search problem, which is efficient.
NAVEX in action
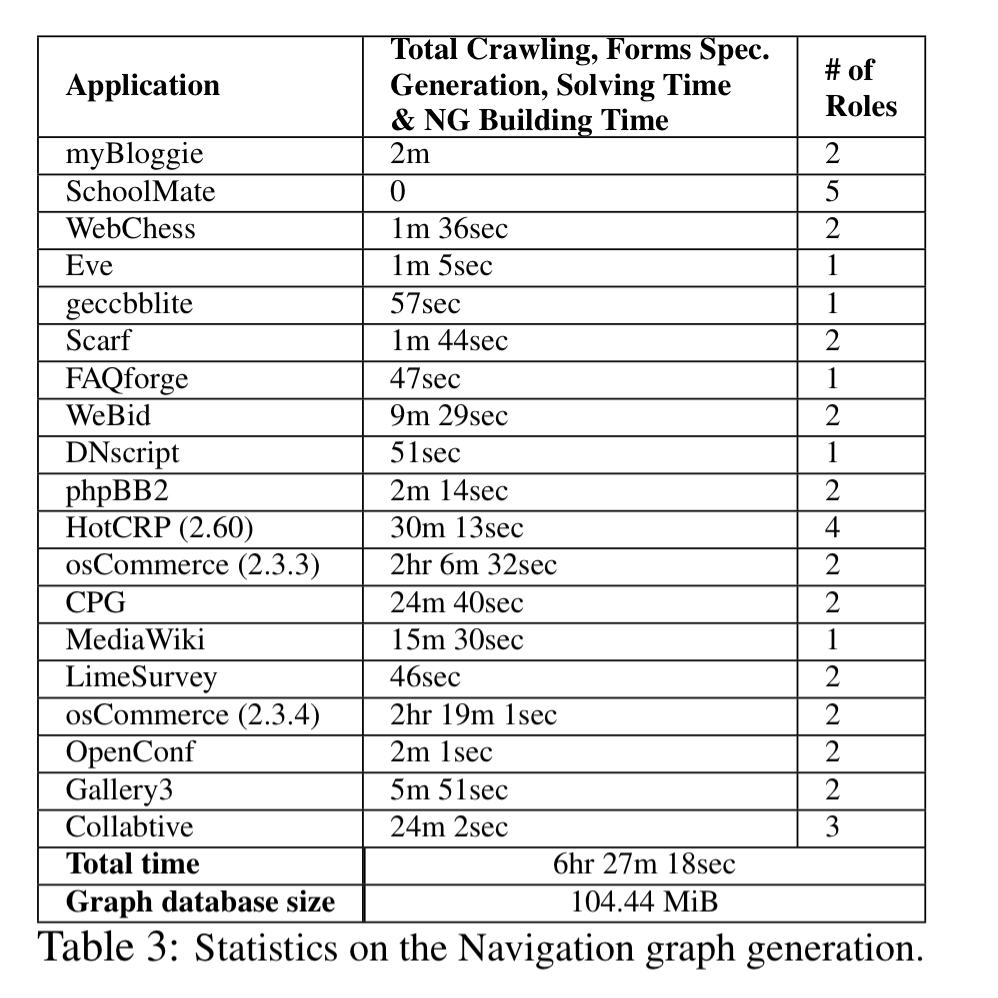
NAVEX is evaluated on 26 real-world PHP apps with a combined codebase of 3.2M SLOC and 22.7K PHP files. The list of apps and their respective sizes is given in the table below.
NAVEX was able to find 204 exploits. 195 of these are injection exploits, and 9 relate to logic vulnerabilities. The longest exploit paths contained 6 HTPP requests. It takes from a few seconds to a few hours to complete the analysis of an application and build the navigation graph:
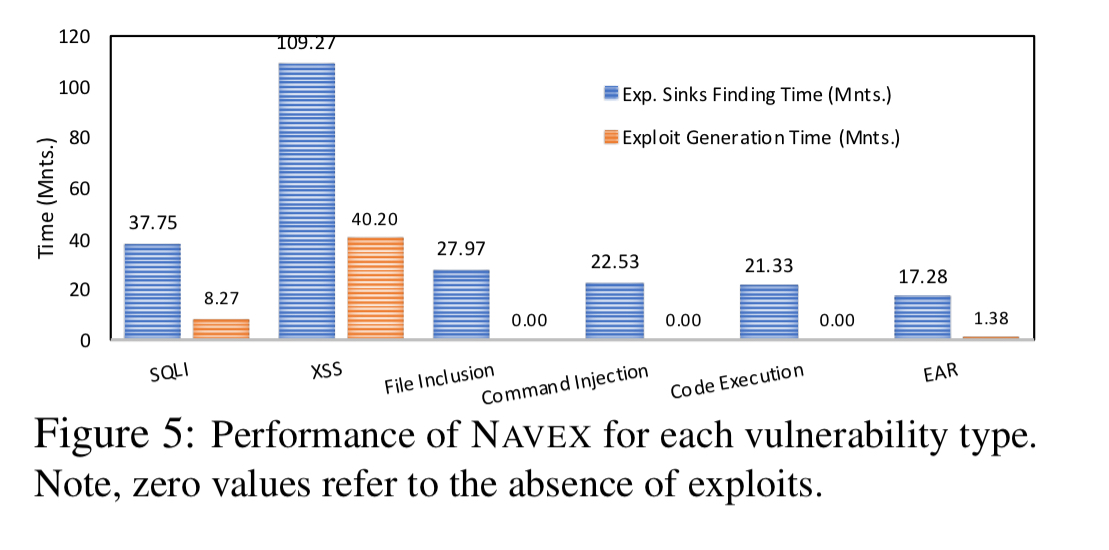
The following figure shows the total time to find exploitable sinks and generate concrete exploits, broken down by exploit type:
NAVEX compares very favourable to state-of-the-art vulnerability detection and exploit generation systems such as Chainsaw and RIPS (see section 5.3 in the paper for details).
We demonstrated that NAVEX significantly outperforms prior work on the precision, efficiency, and scalability of exploit generation.

The section on “identifying vulnerable sinks” brings to mind the paper “Chaff Bugs: Deterring Attackers by Making Software Buggier”, which introduces additional vulnerabilities into code and heavily relies on understanding the codepaths to access the faked bugs – see https://arxiv.org/pdf/1808.00659.pdf
Thanks for featuring our work. Glad to be a part of this work!