Automated localization for unreproducible builds Ren et al., ICSE’18
Reproducible builds are an important component of integrity in the software supply chain. Attacks against package repositories and build environments may compromise binaries and produce packages with backdoors (see this report for a recent prominent example of compromised packages on DockerHub). If the same source files always lead to the same binary packages, then an infected binary can be much more easily detected. Unfortunately, reproducible builds have not traditionally been the norm. Non-determinism creeping into build processes means that rebuilding an application from the exact same source, even within a secure build environment, can often lead to a different binary.
Due to the significant benefits, many open-source software repositories have initiated their validation processes. These repositories include GNU/Linux distributions such as Debian and Guix, as well as software systems like Bitcoin.
If you have a non-reproducible build, finding out why can be non-trivial. It takes time and a lot of effort to hunt down and eradicate the causes. For example, Debian unstable for AMD64 still had 2,342 packages with non-reproducible builds as of August 2017. (The number today as I’m writing this is 2,826). You can see a stubbornly persistent group of unreproducible builds in this screen grab from tests.reproducible-builds.org:
screenshot
RepLoc is a tool for highlighting the files within a package which are the likely root cause of non-reproducible builds. Tested against 671 unreproducible Debian packages, it achieves a Top-1 accuracy rate of 47.09%, and at Top-10 accuracy rate of 79.28%. That’s a significant aid to developers looking at cryptic messages from the builds of packages that may include many hundreds of files. With the help of RepLoc, the authors also identified and fixed non-reproducibility issues in 6 packages from Debian and Guix.
Detecting and diagnosing unreproducible builds
The Debian workflow for testing build reproducibility looks like this:
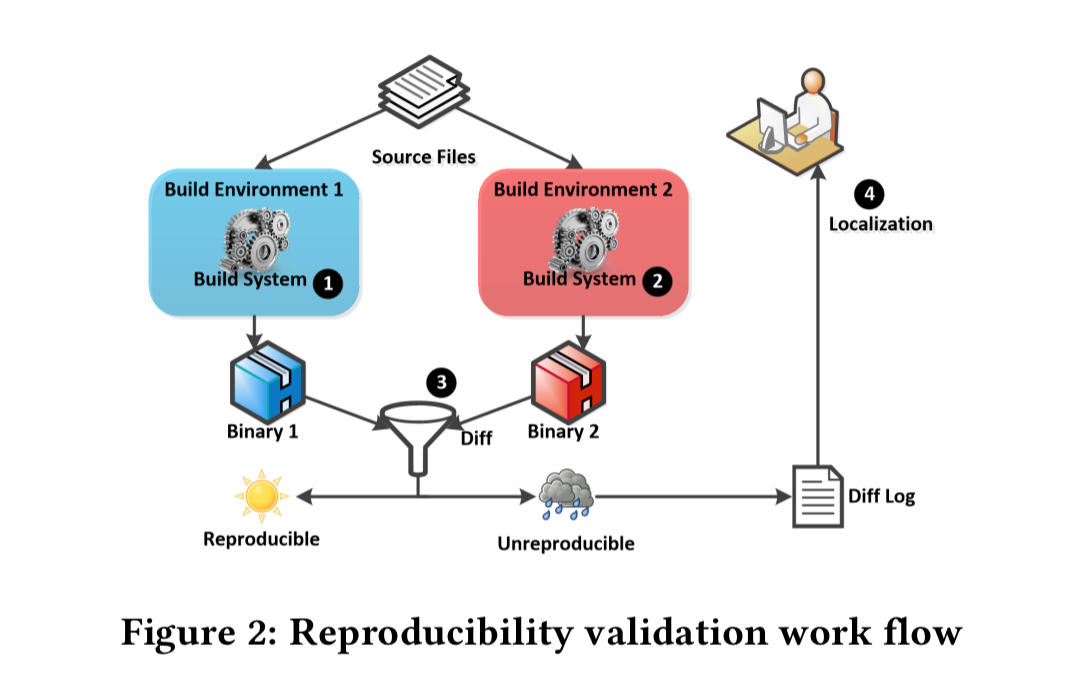
The source is built in two different environments, deliberately constructed with different environment variables and software configurations. If the two resulting binaries are not identical, the package is flagged for human inspection, a process called localization which seeks to localise the causes of unreproducible builds. One of the major inputs to this process is the diff logs, as generated by diffoscope.
Those logs produce output that looks like this:
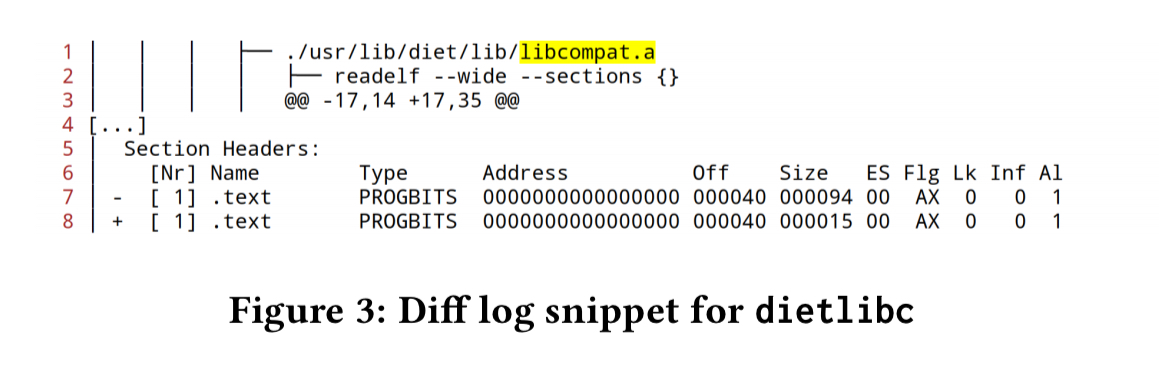
Here we can see diffoscope highlighting a difference in libcompat.a. In this case, the root cause is in the Makefile:

Can you spot it?
The root issue is the unstable ordering of files passed to the ar utility to generate libcompat.a (wildcard libcompat/*.c).
Here’s a patch that fixes the issue.

In general there are many possible causes of unreproducible builds including timezones (making e.g. anything that uses the __DATE__ macro to be unreproducible ) and locale settings (making e.g. capture of output text unreproducible).

Introducing RepLoc
RepLoc begins with the build logs and diff log created by diffoscope, and seeks to automatically highlight the most likely files in which the root cause can be found. RepLoc’s Query Augmentation (QA) component uses information from the logs to refine queries that help to pinpoint likely causes. The Heuristic Filtering component embodies 14 hand-coded heuristic rules that further help to highlight possible causes. The combined outputs are passed to ranking component to produce the list of ranked likely-culprit source files as the final output.
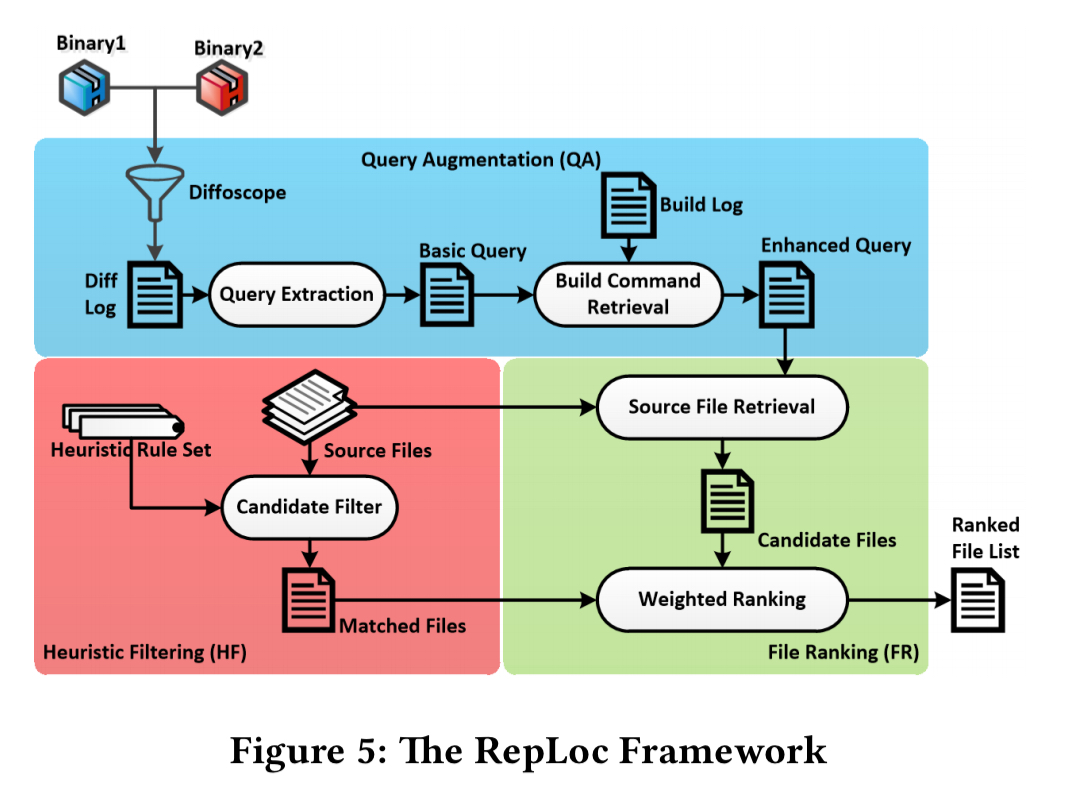
Query Augmentation
The files names highlighted in the diff log are used as the initial seed query set. The build logs contain additional information relating to these files, for example:
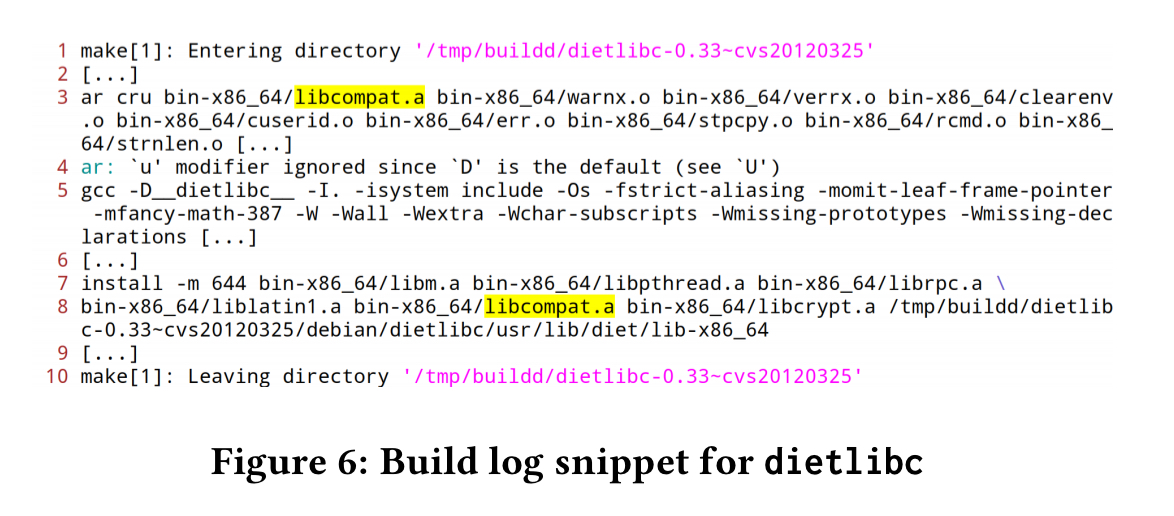
The QA component splits the build logs into directory sections passed on the ‘Entering / Leaving directory’ messages in the logs. Each directory section thus contains a set of commands, which is denoted a ‘command file’ in the paper. TF/IDF is used to assign a weight value to each command file to assess it’s relevance to the initial seed queries. The commands from the most relevant command files are then added to the query set, to produce an augmented query set. (In the example above, the ar cru bin-x86_64/libcompat.a... command causes us to add the content of this command file).
Heuristic filtering
The authors extract fourteen heuristic rules from Debian’s documentation. These rules are encoded as Perl regular expressions(!), as summarised in the table below.
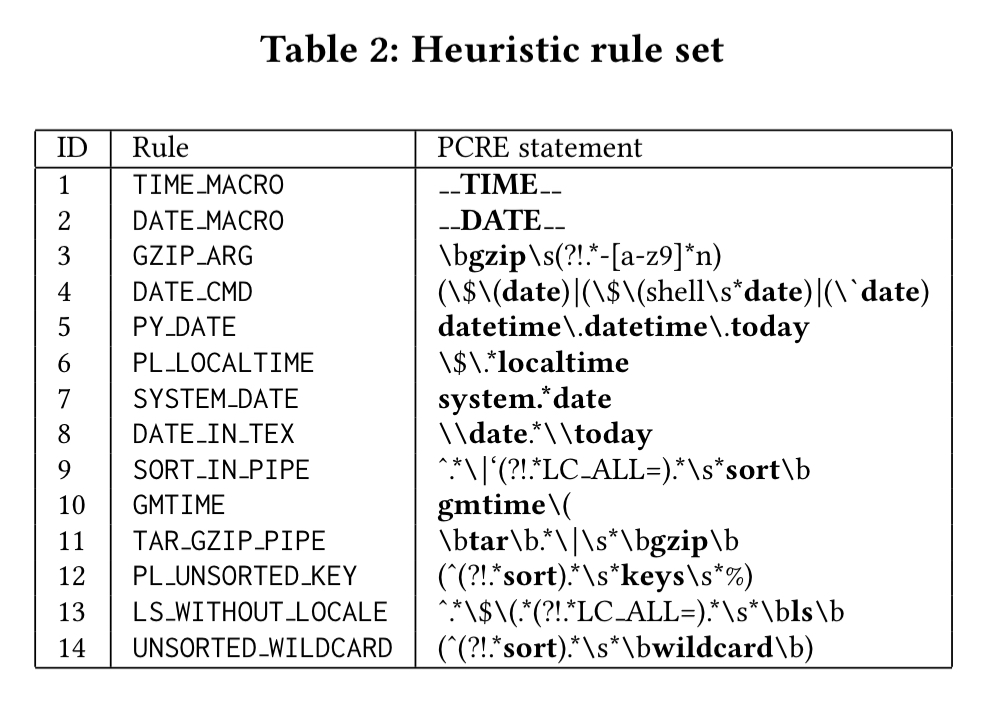
- The time and date rules look for uses of the
__TIME__and__DATE__macros. - The gzip rule (3) looks for uses of gzip without the
-nargument (in which case gzip embeds timestamps in the resulting archive). - The date cmd rule (4) looks for capture of the current date using the
dateshell command - PL_LOCALTIME looks for Perl scripts capturing date and time
- DATE_IN_TEX looks for date embedding in tex files
- SORT_IN_PIPE captures cases where sort is used without a local set
- TAR_GZIP_PIPE looks for
tarandgzipexecuted in a pipeline - PL_UNSORTED_KEY catches traversal of unsorted hash keys in Perl
- LS_WITHOUT_LOCALE captures cases where
lsis used without a locale - UNSORTED_WILDCARD looks for the use of
wildcardin Makefiles without sorting
With the rules in hand, it’s a simple matter of running grep over the source tree. Heuristic filtering has good recall, but poor precision (i.e., it can produce a lot of false positives).
Ranking
We can compute the cosine similarity (using TF/IDF) between each package file and the augmented queries to produce a ranked list of candidate files from the QA module. These are then combined with the files highlighted by the HF module to give a simple weighted score:

Where QA(f) is the similarity score produced by the QA module, and HF(f) is 1 if the HF module flagged the file, and 0 otherwise. α is a configurable parameter to tune the balance between the two terms.
RepLoc in action
At the time of the study, Debian had 761 packages with accompanying patches that turned unreproducible builds into reproducible ones. This constitutes the ground truth dataset for RepLoc. The dataset is further divided into four subsets based on the major causes of non-reproducibility. The table below summarises how well RepLoc gets on. Concentrate on the bottom line (RepLoc) in each row (the other lines show how RepLoc behaves with different subsets of its modules).
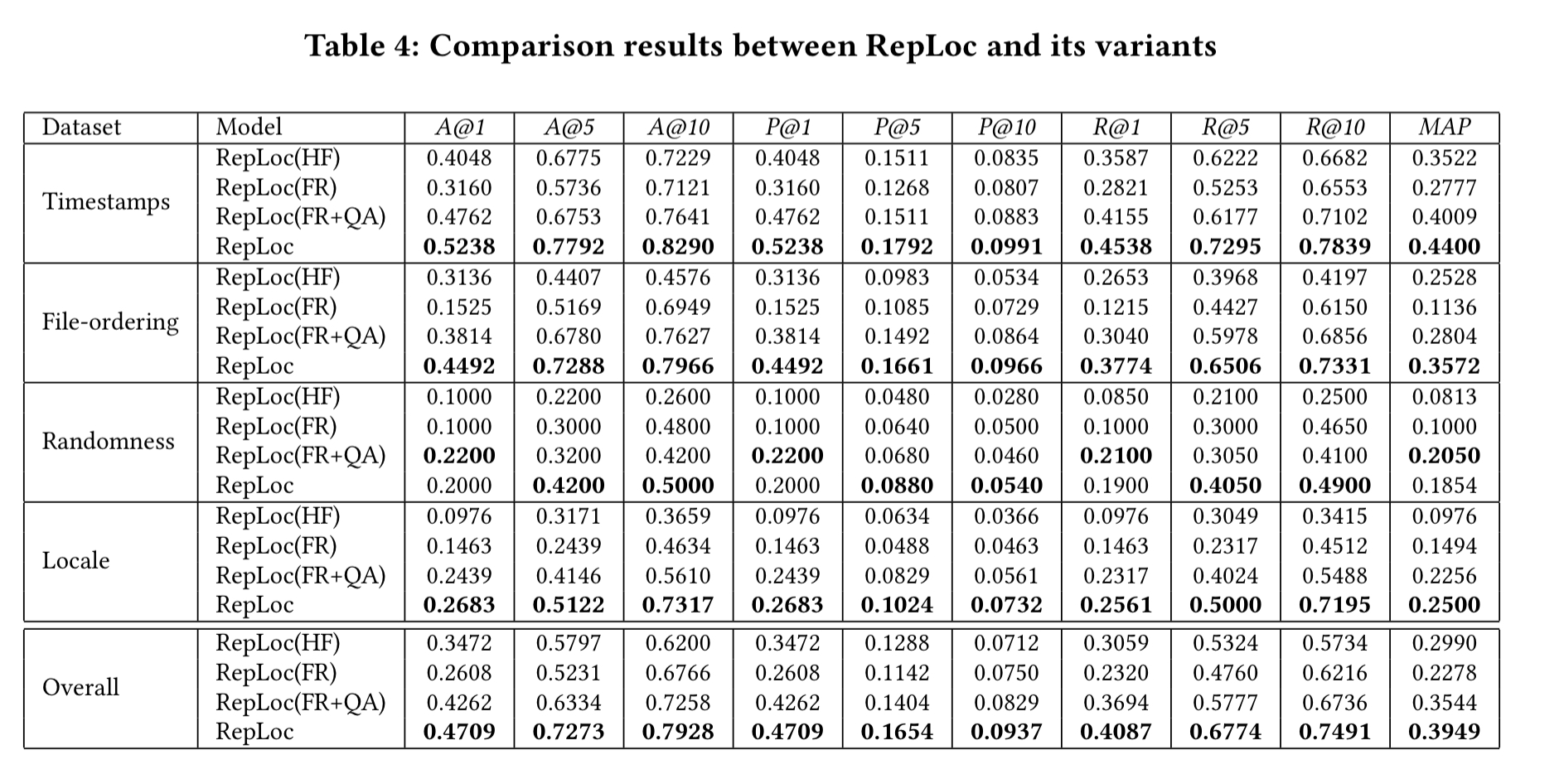
- A@N is a top-N accuracy rate score, defined as the percentage of top-N ranked file lists produced by RepLoc that contain at least one problematic file (from the patches).
- P@N is a top-N precision score, defined as the percentage of files reported in a top-N list that are genuinely problematic
- R@N is at top-N recall score, defined as the percentage of all problematic files that are successfully identified in a top-N list.
Overall, RepLoc achieves an average accuracy score of 79% for Top-10 files. I.e., if you examine the first ten files RepLoc highlights, you have a 79% chance of finding an issue causing an unreproducible build in at least one of them. You will also find on average 75% of all the files with reproducibility problems by the time you have worked through that top-10 list.
The authors then used RepLoc to see if they could find the root causes of unreproducible builds for packages where no ground truth was available (i.e., there was no-known reproducible build process for them). Three packages from Debian are fixed (regina-rexx, fonts-uralic, and manpages-tr). The problematic files are right at the top of list produced by RepLoc. Three packages from Guix are also fixed (libjpeg-turbo, djvulibre, and skalibs). Once more the problematic files are right at the top of the list produced by RepLoc.
Future work
For the future work, we are interested in the localization of problematic files for tool-chain related issues. Also, inspired by record-and-play techniques from crash reproduction based debugging research, it would be interesting to leverage these techniques to detect more accurate correspondence between the build commands executed and the built binaries.

One thought on “Automated localization for unreproducible builds”
Comments are closed.