We’ll be looking at a couple more papers from the re-coding Black Mirror workshop today:
- Pitfalls of affective computing, Cooney et al.
- Ease and ethics of user profiling in Black Mirror, Pandit & Lewis
(If you don’t have ACM Digital Library access, all of the papers in this workshop can be accessed either by following the links above directly from The Morning Paper blog site, or from the WWW 2018 proceedings page).
Pitfalls of affective computing
It’s possible to recognise emotions from a variety of signals including facial expressions, gestures and voices, using wearables or remote sensors, and so on.
In the current paper we envision a future in which such technologies perform with high accuracy and are widespread, so that people’s emotions can typically be seen by others.
Clearly, this could potentially reveal information people do not wish to reveal. Emotions can be leaked through facial micro-expressions and body language making concealment very difficult. It could also weaken social skills if it is believed that there is no need to speak or move to convey emotions. “White lies” might become impossible, removing a person’s responsibility to be compassionate. It could also lead to physical harm:
The ability to quickly detect threats and opportunities via negative or positive emotions could increase the incidence of fighting and violence… for example, a person could feel threatened by seeing their partner and a potential rival feel highly positive emotions toward one another, which could lead to anger and violence.
Misreading emotions, or overly simplifying emotions (e.g. boiling things down to just one emotion to display, rather than the complex mix which is reality), can also cause miscommunications and misunderstandings.
.. if a person’s own inference about someone else’s emotions differs from what is visualized, dissonance and distrust might be felt. Finally, a system could be hacked to make it seem as if a person genuinely feels a different emotion, which could benefit politicians, lawyers, or criminals.
And then of course there’s the possibility that robots and computers, on being able to read emotions, could also gain an advantage in persuading people, perhaps for commercial gain. Think of dark uses such as scams target certain demographics such as the elderly, which can also check that a victim truly believes a story and use emotional feedback to be more convincing.
The authors propose a guideline that “a person’s emotions should only be visualized with their consent, to trusted persons.” It’s going to be hard to defend against systems that quietly observe you though. A person with depression should not be forced to expose their condition to total strangers, and employees should not be afraid of being continually monitored and losing their jobs for some emotional slip-up.
…under privacy regulation such as the GDPR, one’s emotional state could be regarded as personal information and therefore subject to protections and transparencies which are already available today. We believe that such considerations of what problems can occur and how they can be avoided, will enable emotion visualization to contribute positively to people’s well-being.
Ease and ethics of user profiling in Black Mirror
This discussion paper is based on the episode ‘Nosedive’, and examines scenarios in which users are widely profiled, and the profile information becomes embedded in everyday life. (Think of China’s social credit system!). Consider a fictitious organisation F-social that provides services to its users (free or paid) and manages to accumulate a lot of personal information along the way.
A restaurant sends in facial pictures of its customers to F-social to get a metric of the amount of purchasing power they possess and how likely they are to splurge. They are able to do this via a seemingly innocuous notice at their doors that says “by entering the premises you consent to be identified.”
F-social identifies the individuals by looking for matches to their facial profiles in its database of users. If the individual doesn’t use F-social they may still be identifiable in the tagged photos of their friends. If there is really no information, F-social returns the ‘no-match’ result, which is interpreted by the restaurant as being ambiguous and suspicious.
At the next step, F-social computes a score for the restaurant indicating the customer’s likely spending power, and their potential to splurge today. It might do this by looking at past purchases, or obtained via linked financial data. It can see what kinds of dishes have been ordered and their prices. Then F-social looks for indications of any special occasion in the profile – a birthday, anniversary, promotion etc.. Finally F-social considers how far into the salary month the customer is. The experience the customer is about to receive at the restaurant can be heavily influenced by these behind the scenes black-box calculations… “This second-hand effect of limiting access or discriminating based on some metric results in a pressure to conform to accepted behaviours.”
The current norm seems to be to consider the practical implications of a technology after its widespread usage and in most cases only when someone else raises objections based on their perceived risks… The core issue underlying the lack of discussions on these topics by technologists (is that) no method for practising ethics integrates into the methodology for work readily enough to adopt it.
To help address this issue, the author’s offer us the ‘Ethics Canvas’, inspired by the popular Business Model Canvas.
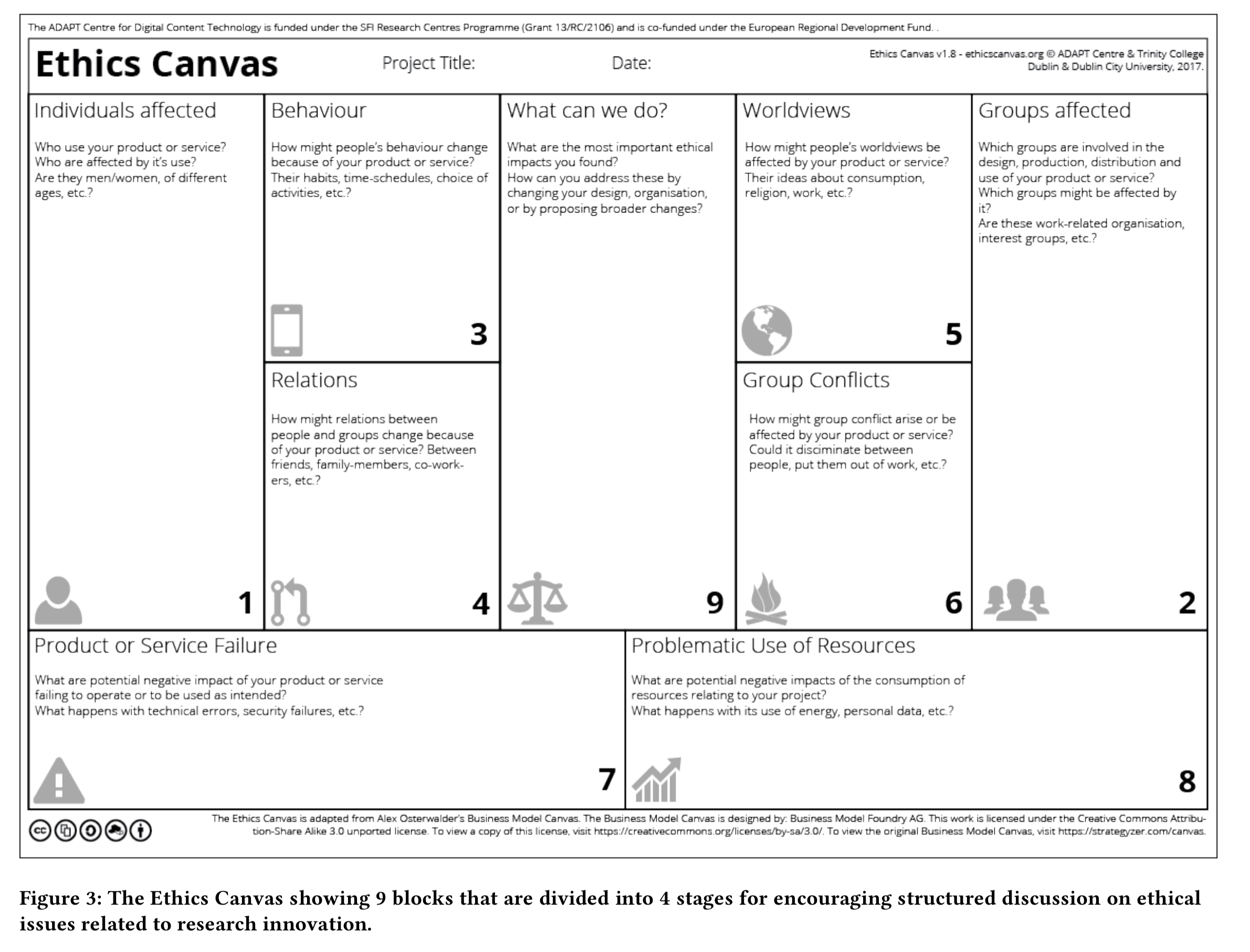
The canvas has nine thematic blocks, typically completed in four stages.
- Identification of stakeholders. Blocks 1 and 2 identify the individuals and group stakeholders based on the technology under consideration.
- Identification of potential ethical impacts. The next step is to fill in blocks 3,4, 5, and 6 with identified potential ethical impacts for the stakeholders (see questions in the boxes for illustration).
- Consider ethical impacts on non-stakeholders (boxes 7 and 8 regarding the impact of failures and use of resources).
- Make an action plan (box 9)
The ethics canvas can be printed or used as a web application that can be used without an account and can be downloaded. Certain features such as collaborative editing, comments, tagging, and persistence are made available through an account. The source of the application is hosted online and is available under the CC-by-SA 3.0 license.
Let’s take a look at how the canvas helps us to analyse our hypothetical F-social restaurant scenario.
Stakeholders
Individual stakeholders include any users of F-social, as well as any non-users tagged in images F-social have access to, and of course customers of the restaurant. Looking at the datasets used by F-social behind the scenes (such as data from credit companies) we can also include users who appear in those datasets as stakeholders.
Affected groups could by any group of people averse to being tracked, e.g. journalists looking for safe places to meet, or people in positions of power where information about their whereabouts can pose a security risk. Any minority group that might inadvertently be disadvantaged by the profiling are also at risk.
Stakeholder impacts
Users may find more incentives to post things that boost their ratings, and refrain from posting negative things. “They are also more likely to provide information if it helps them achieve monetary or other forms of benefits from services that use the ratings to vet customers.” Moreover, if the ratings take into account a user’s social circle, then a user is more likely to want to have their social circle made up of people who will have a positive effect on their rating. Eventually people with higher ratings may look down on those with lower ratings (as we see in the ‘Nosedive’ episode).
For example, places that only cater to people with higher ratings automatically are seen as ‘exclusive’ whereas places that readily accept people with lower ratings might be seen as not being ‘classy’. To a certain extent, this phenomenon is observable today with regards to monetary spending capacity.
Non-stakeholder impacts
The F-social metric may be open to being gamed, or the service attacked or disabled. This could lead to users being denied services. Some clients of the service may try to use it for purposes not deemed acceptable under legal, business, ethical, or moral viewpoints. Governments or state-level entities may demand access to the data.
Mitigating actions?
Assuming the service being provided by F-social is legally acceptable and hence can’t be shutdown on that basis, the authors proposal is to add more transparency: the algorithm used to calculate the rating could be openly evaluated (what if it’s a neural net?) to provide a level of authenticity and oversight to the usage of data, and help prevent false information about the service from spreading. In this section the authors seem to have deviated from (my interpretation of) the intent of box 9, which is that it should be used by the F-social organisation itself to think through its offering before launch, and for continual review. Instead they focus more on what external users who don’t like F-social may be able to ask/force it to do.
You can find out more about the canvas and give it a go for yourself at https://ethicscanvas.org.

2 thoughts on “Re-coding Black Mirror, Part II”
Comments are closed.