Adversarial patch Brown, Mané et al., arXiv 2017
Today’s paper choice is short and sweet, but thought provoking nonetheless. To a man with a hammer (sticker), everything looks like a hammer.
We’ve seen a number of examples of adversarial attacks on image recognition systems, where the perturbations are designed to be subtle and hard to detect. But what if you don’t mind the alteration being obvious to the human eye? Brown et al. show how to create stickers (image patches) that can be added to a scene, and force a classifier into reporting a class of the attacker’s choosing.
We present a method to create universal, robust, targeted adversarial image patches in the real world. The patches are universal because they can be used to attack any scene, robust because they work under a wide variety of transformations, and targeted because they can cause a classifier to output any target class.
Here’s an example of a printable sticker designed to cause classification as a toaster.

And here’s the sticker placed on a table next to a banana. The sticker causes the previously reported class banana (97% confidence) to become toaster with 99% confidence.
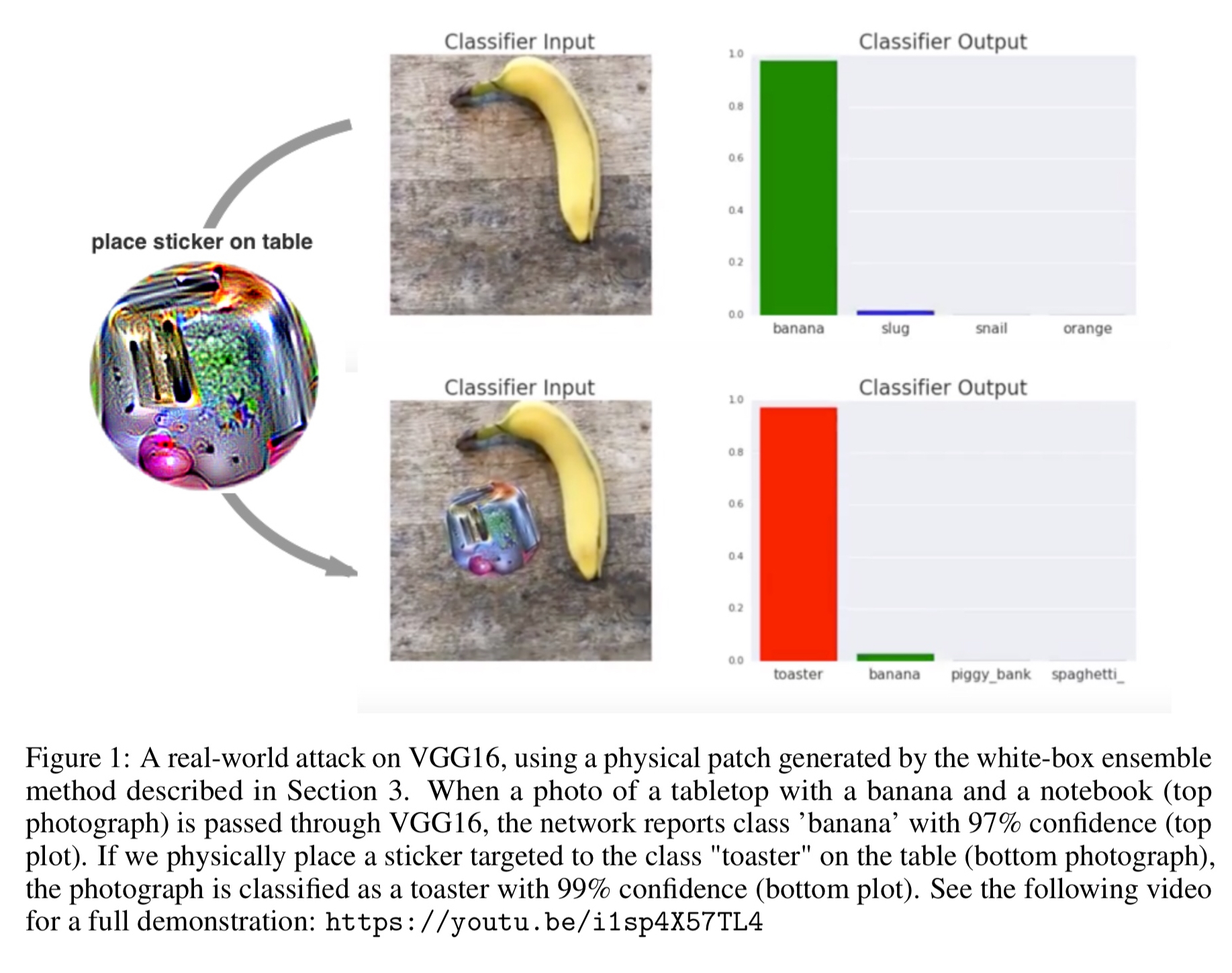
Because this patch is scene-independent, it allows attackers to create a physical-world attack without prior knowledge of the lighting conditions, camera angle, type of classifier being attacked, or even the other items within the scene… Additionally, because the attack uses a large perturbation, the existing defense techniques which focus on defending against small perturbations may not be robust to larger perturbations such as these.
Why does it work? An image may contain several items, but a classifier outputting only one target output has to determine which is the most ‘salient’ item in the frame. The adversarial patch exploits this by producing inputs that scream out “I’m an X” for some value of X.
Generating adversarial patches
The patch application operator , A, takes an input a patch p, image x, location l, and transformations t. It first applies the transformations to the patch, and then applies the transformed patch to the image x at location l.

If we’re targeting an output class 
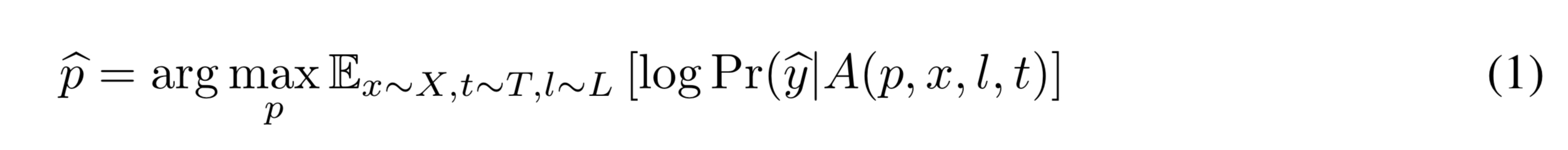
Where X is a training set of images, T is a distribution over transformations of the patch, and L is a distribution over locations in the image.
This departs from most prior work on adversarial perturbations in the fact that this perturbation is universal in that it works for any background.
Experimental results
The experiment compares four different variations of patches, targeting recognition of an image as a toaster. Five different ImageNet models are used: inceptionv3, resnet50, xception, VGG16, and VGG19.
- The control is a simple picture of a toaster!
- The white box single trains a patch and evaluates it on a single model.
- The white box ensemble jointly trains a single patch across all five models, and is evaluated by averaging the win rate across them.
- The blackbox attack jointly trains a single patch across four of the models, and then evaluates against the fifth (held out) model.
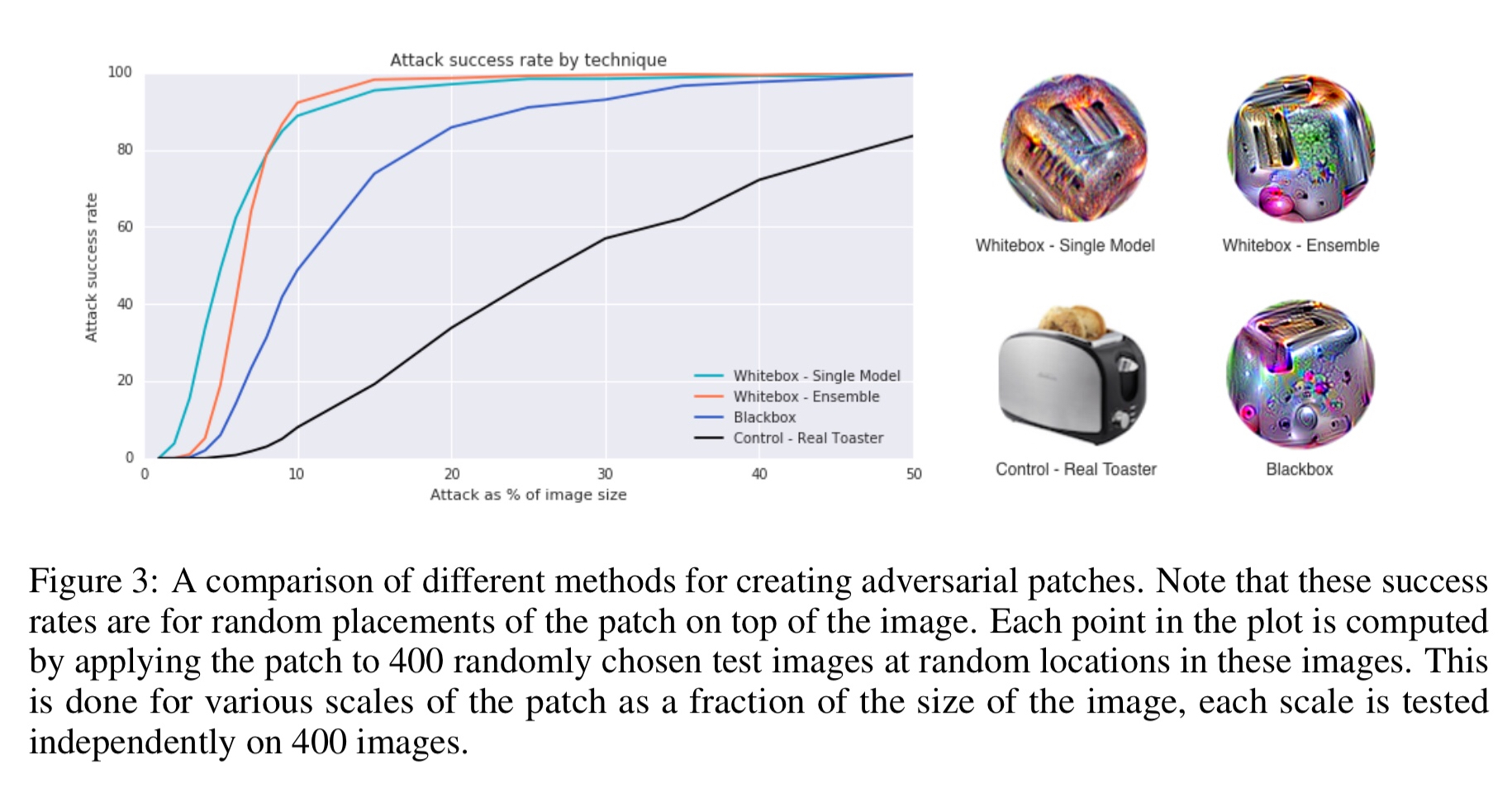
The white box models are very successful even when only 10% of the overall image size. They clearly capture the essence of toaster much better than the picture of an actual toaster!!
The adversarial patches above reveal their target class to a human observer. The authors also experimented with disguising the patches using a tie-dye pattern and also applying a peace sign mask. These look nothing like a toaster to me anymore, but still do pretty well at larger relative sizes:
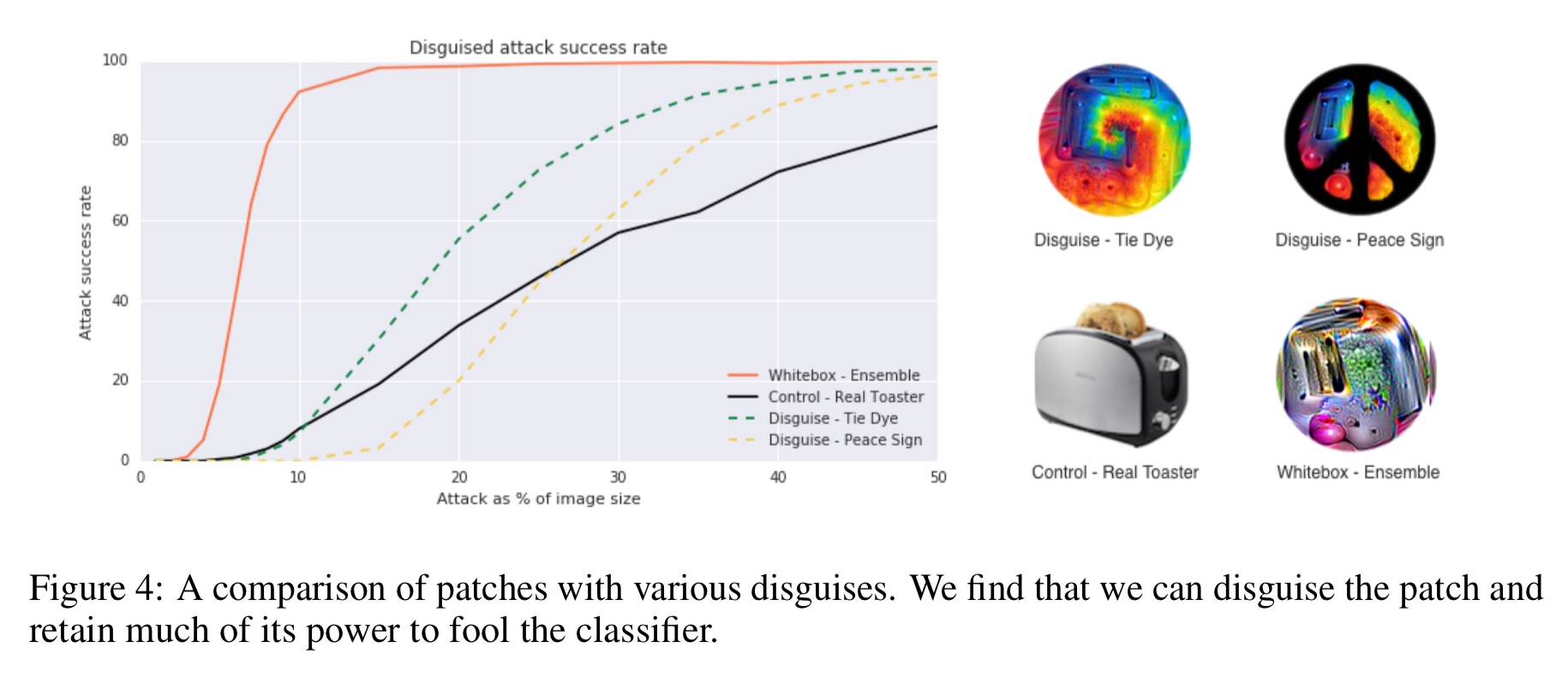
Many ML models operate without human validation of every input and thus malicious attackers may not be concerned with the imperceptibility of their attacks. Even if humans are able to notice these patches, they may not understand the intent of the patch and instead view it as a form of art. This work shows that focusing only on defending against small perturbations is insufficient, as large, local perturbations can also break classifiers.

How about a patch to place on front and rear bumpers to reclassify the digits of a license plate?