When coding style survives compilation: de-anonymizing programmers from executable binaries Caliskan et al., NDSS’18
As a programmer you have a unique style, and stylometry techniques can be used to fingerprint your style and determine with high probability whether or not a piece of code was written by you. That makes a degree of intuitive sense when considering source code. But suppose we don’t have source code? Suppose all we have is an executable binary? Caliskan et al., show us that it’s possible to de-anonymise programmers even under these conditions. Amazingly, their technique still works even when debugging symbols are removed, aggressive compiler optimisations are enabled, and traditional binary obfuscation techniques are applied! Anonymous authorship of binaries is consequently hard to achieve.
One of the findings along the way that I found particularly interesting is that more skilled/experienced programmers are more fingerprintable. It makes sense that over time programmers acquire their own unique way of doing things, yet at the same time these results seem to suggest that experienced programmers do not converge on a strong set of stylistic conventions. That suggests to me a strong creative element in program authorship, just as experienced authors of written works develop their own unique writing styles.
If we encounter an executable binary sample in the wild, what can we learn from it? In this work, we show that the programmer’s stylistic fingerprint, or coding style, is preserved in the compilation process and can be extracted from the executable binary. This means that it may be possible to infer the programmer’s identity if we have a set of known potential candidate programmers, along with executable binary samples (or source code) known to be authored by these candidates.
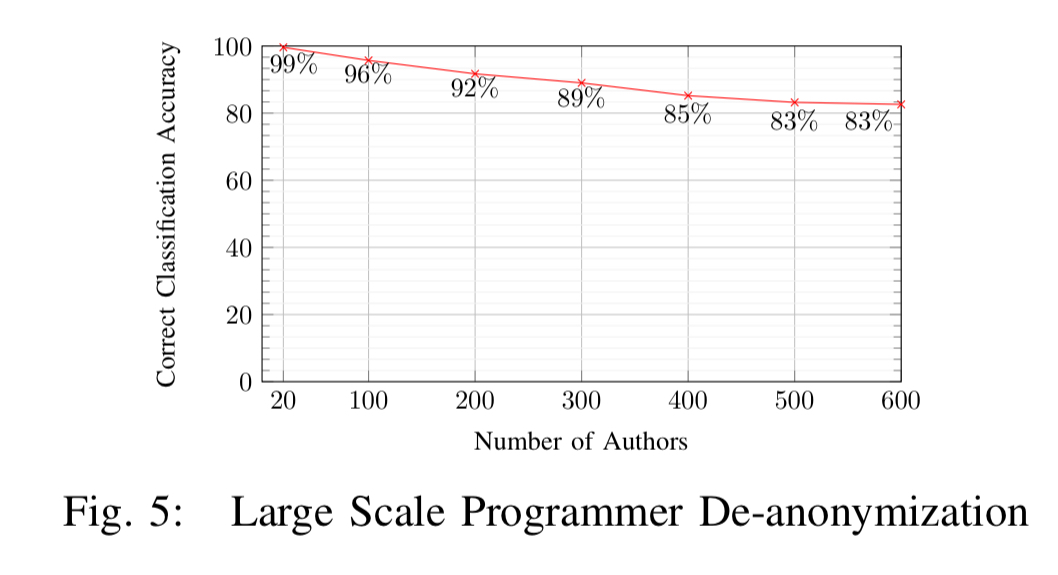
Out of a pool of 100 candidate programmers, Caliskan et al. are able to attributed authorship with accuracy of up to 96%, and with a pool of 600 candidate programmers, they reach accuracy of 83%. These results assume that the compiler and optimisation level used for compilation of the binary are known. Fortunately, previous work has shown that toolchain provenance, including the compiler family, version, optimisation level, and source language, can be identified using a linear Conditional Random Field (CRF) with accuracy of up to 99% for language, compiler family, and optimisation level, and 92% for compiler version.
One of the potential uses for the technology is identifying authors of malware.
Finding fingerprint features in executable binaries
So how is this seemingly impossible feat pulled off? The process for training the classifier given a corpus of works by authors in a candidate pool has four main steps, as illustrated below:
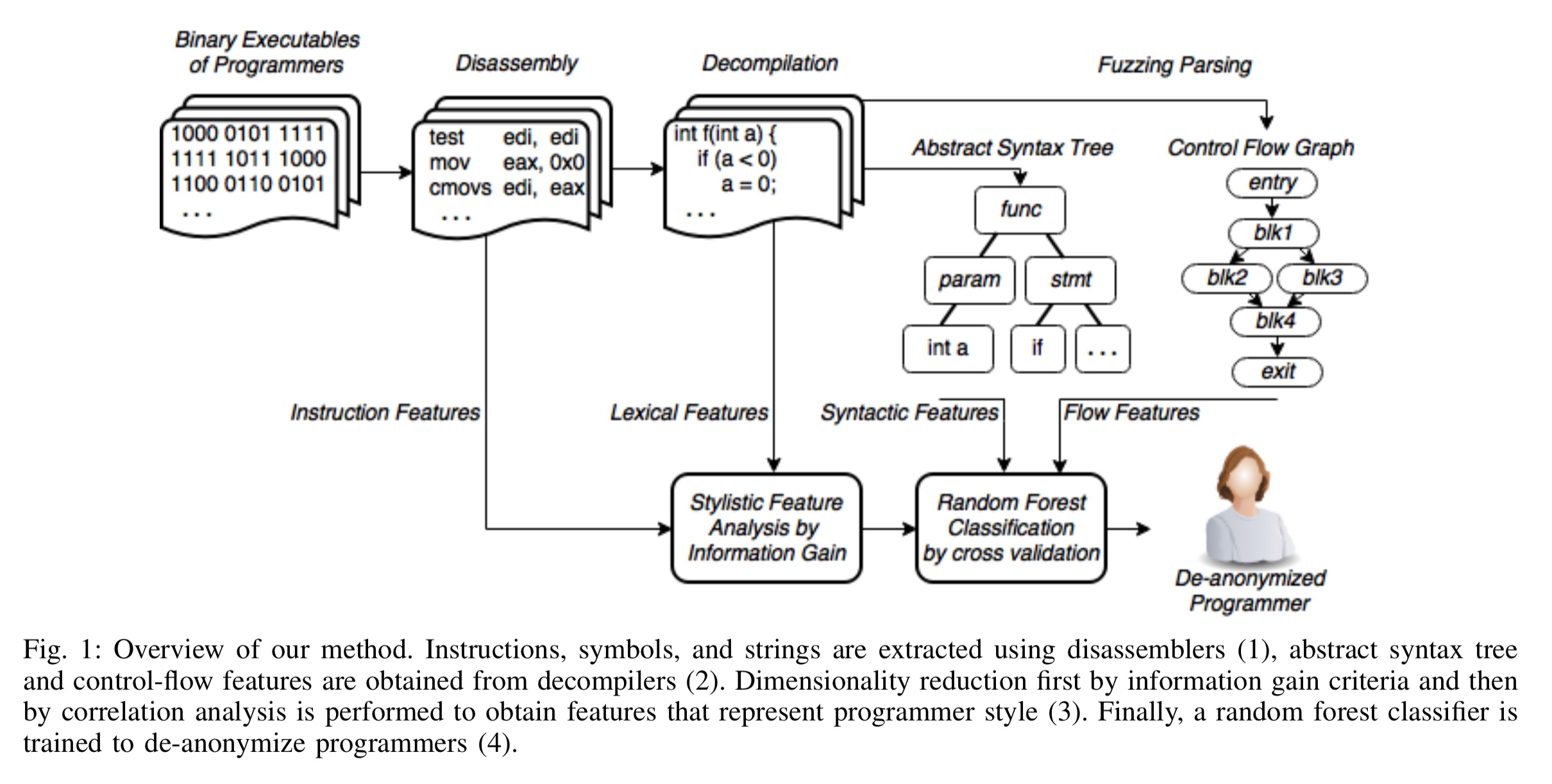
- Disassembly: first the program is disassembled to obtain features based on machine code instructions, referenced strings, symbol information, and control flow graphs.
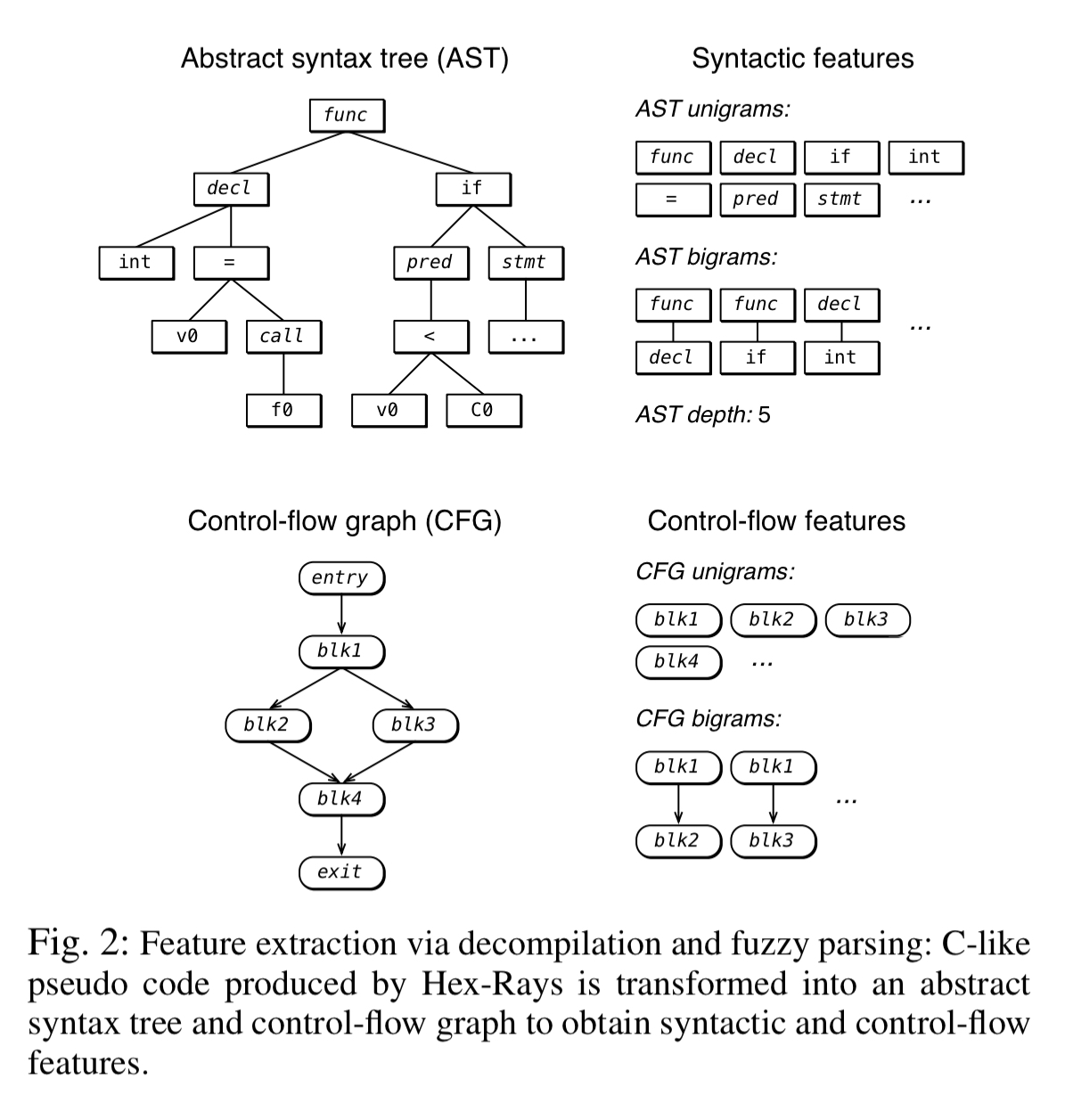
- Decompilation: the program is translated into C-like pseudo-code via decompilation, and this pseudo-code is passed to a fuzzy C parser to generate an AST. Syntactical features and n-grams are extracted from the AST.
- Dimensionality reduction: standard feature selection techniques are used to select the candidate features from amongst those produced in steps 1 and 2.
- Classification: a random forest classifier is trained on the corresponding feature vectors to yield a program that can be used for automatic executable binary authorship attribution.
You can download the code at https://github.com/calaylin/bda.
Disassembly
The disassembly step runs the binary through two different disassemblers: the netwide disassembler (ndisasm), which does simple instruction decoding, and the radare2 state-of-the-art open source disassembler, which also understands the executable binary format. Using radare2 it is possible to extract symbols, strings, functions, and control flow graphs.
Information provided by the two disassemblers is combined to obtain our disassembly feature set as follows: we tokenize the instruction traces of both disassemblers and extract token uni-grams, bi-grams, and tri-grams within a single line of assembly, and 6-grams, which span two consecutive lines of assembly… In addition, we extract single basic blocks of radare2’s control flow graphs, as well as pairs of basic blocks connected by control flow.
Decompilation
Decompilation is done using the Hex-Rays commercial state-of-the-art decompiler, which produces human readable C-like pseudo-code. This code may be much longer than the original source code (e.g. decompiling a program that was originally 70 lines long may produce on average 900 lines of decompiled code).
From the decompiled result, both lexical and syntactical features are extracted. Lexical features are word unigrams capturing integer types, library function names, and internal function names (when symbol table information is available). Syntactical features are obtained by passing the code to the joern fuzzy parser and deriving features from the resulting AST.
Dimensionality reduction
Following steps one and two, a large number of features can be generated (e.g., 705,000 features from 900 executable binary samples taken across 100 different programmers). A first level of dimensionality reduction is applied using WEKA’s information gain attribute selection criteria, and then a second level of reduction is applied using correlation based feature selection. The end result for the 900 binary samples is a set of 53 predictive features.
Classification
Classification is done using random forests with 500 trees. Data is stratified by author analysed using k-fold cross-validation, where k is equal to the number of available code samples per author.
Evaluation results
The main evaluation is performed using submission to the annual Google Code Jam competition, in which thousands of programmers take part each year. “We focus our analysis on compiled C++ code, the most popular programming language used in the competition. We collect the solutions from the years 2008 to 2014 along with author names and problem identifiers.”
Datasets are created using gcc and g++, using each of O1, O2, and O3 optimisation flags (so six datasets in all). The resulting datasets contain 900 executable binary samples from 100 different authors. As we saw before, the authors are able to reduce the feature set down to 53 predictive features.
To examine the potential for overfitting, we consider the ability of this feature set to generalize to a different set of programmers, and show that it does so, further supporting our belief that these features effectively capture programming style. Features that are highly predictive of authorial fingerprints include file and stream operations along with the formats and initializations of variables from the domain of ASTs, whereas arithmetic, logic, and stack operations are the most distinguishing ones among the assembly instructions.
Without optimisation enabled, the random forest is able to correctly classify 900 test instances with 95% accuracy. Furthermore, given just a single sample of code (for training) from a given author, the author can be identified out of a pool of 100 candidates with 65% accuracy.
The classifier also reaches a point of dramatically diminishing returns with as few as three training samples, and obtains a stable accuracy by training on 6 samples. Given the complexity of the task, this combination of high accuracy with extremely low requirement on training data is remarkable, and suggests the robustness of our features and method.
The technique continues to work well as the candidate pool size grows:
Turning up the difficulty level
Programming style is preserved to a great extent even under the most aggressive level 3 optimisations:
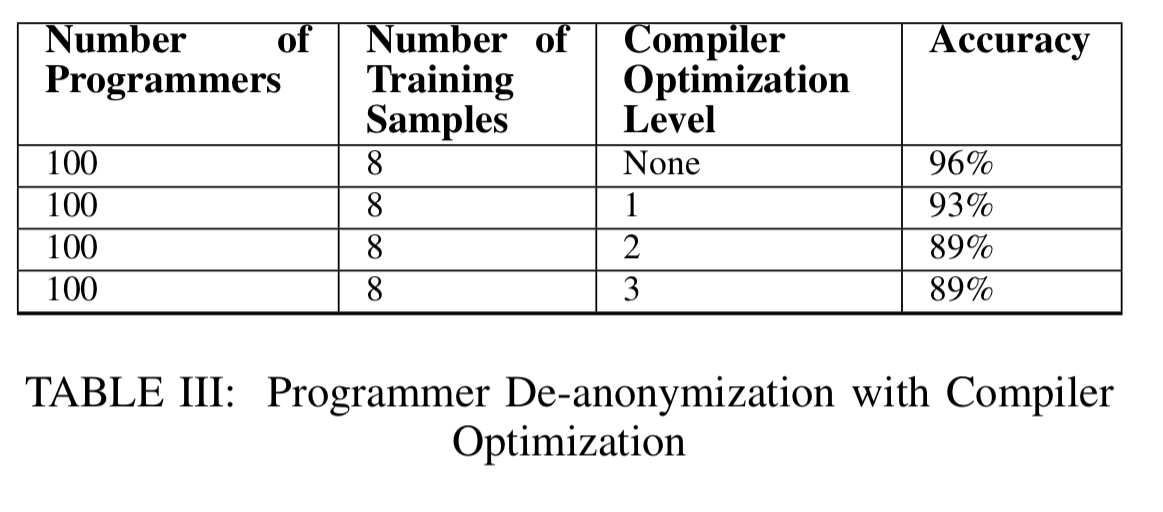
…programmers of optimized executable binaries can be de-anonymized, and optimization is not a highly effective code anonymization method.
Fully stripping symbol information reduces classification accuracy by 24%, so even removing symbols is not an effective form of anonymisation.
For the pièce de résistance the authors use Obfuscator-LLVM and apply all three of its obfuscation techniques (instruction substitution, introducing bogus control flow, flattening control flow graphs). And the result? “Using the same features as before, we obtain an accuracy of 88% in correctly classifying authors.”
… while we show that our method is capable of dealing with simple binary obfuscation techniques, we do not consider binaries that are heavily obfuscated to hinder reverse engineering.
So you want to stay anonymous?
If you really do want to remain anonymous, you’d better plan for that from the very beginning of your programming career, and even then it doesn’t look easy! Here are the conditions recommended by the authors:
- Do not have any public repositories
- Don’t release multiple programs using the same online identity
- Try to have a different coding style (!) in each piece of software you write, and try to code in different programming languages.
- Use different optimisations and obfuscations to avoid deterministic patterns
Another suggestion that comes to mind is to use an obfuscater deliberately designed to prevent reverse engineering. Although since these weren’t tested, we don’t actually know how effective that will be.
A programmer who accomplishes randomness across all potential identifying factors would be very difficult to deanonymize. Nevertheless, even the most privacy savvy developer might be willing to contribute to open source software or build a reputation for her identity based on her set of products, which would be a challenge for maintaining anonymity.

100% disagree,
If any coder, likely me, changes styles and coding approach,
because,IF i found someone, better than me,
I will copy, paste and modify, thus, my methods and style will
change many times, even within a year.
I believe, a LOT of coders, are like me.
I could implement, any app, more than 3 different ways,
Just because, i want to test some other approach.
7 likes? 44k likes more like it.
Any real coder, can tell you, any COMPLEX method, can be code 100 different ways.
Produce 100 difference binary, yet, produce the same result.
You article, likely, written by a FAKE coder.
By the way, any ASM coder, will most likely, disagree with that article.
One Group of Smart people, does not means, they are correct.
Debate, is what science is all about.
Quote: unique style, and stylometry techniques can be used to fingerprint your style and determine with high probability whether or not a piece of code was written by you.
UnQuote.
This may be current, when apply to a single platform and language,
Not Very UNLIKE, be correct for all PLATFORM LANGUAGES.
ASM, UNIX-C, APL, FORTRAN, AND hundreds for old and new languages,
DART is similar to C#, binary however, will be different,
because compiler is different.
if ( cond1 == true )
{
}
else
{
}
vs I
if (cond1 == true) { } else { }
2 different styles, produce the same binary.
coding my favorite game
Read through the article and can say that their experiment is tainted.
During feature selection, they use all of their data, picking 53 out of 700K features. If you choose 700K absolutely random features and try to select a subset that correlates with the target label (on the whole data), you will always find something that does.
Then if you train random forest on one subset of your data and test on another subset, you still use features that know a lot about your test dataset.
To be short, an experiment is dirty and doesn’t reflect the real learning power of this method.