Towards web-based delta synchronization for cloud storage systems Xiao et al., FAST’18
If you use Dropbox (or an equivalent service) to synchronise file between your Mac or PC and the cloud, then it uses an efficient delta-sync (rsync) protocol to only upload the parts of a file that have changed. If you use a web interface to synchronise the same files though, the entire file will be uploaded. This situation seems to hold across a wide range of popular services:
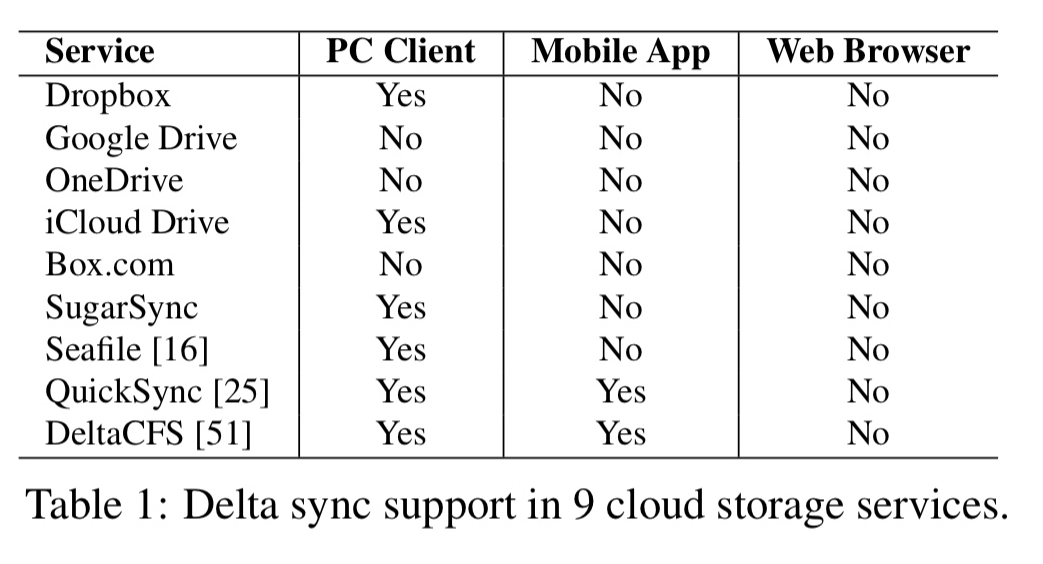
Given the universal presence of the web browser, why can’t we have efficient delta syncing for web clients? That’s the question Xiao et al. set out to investigate: they built an rsync implementation for the web, and found out it performed terribly. Having tried everything to improve the performance within the original rsync design parameters, then they resorted to a redesign which moved more of the heavy lifting back to the server-side.
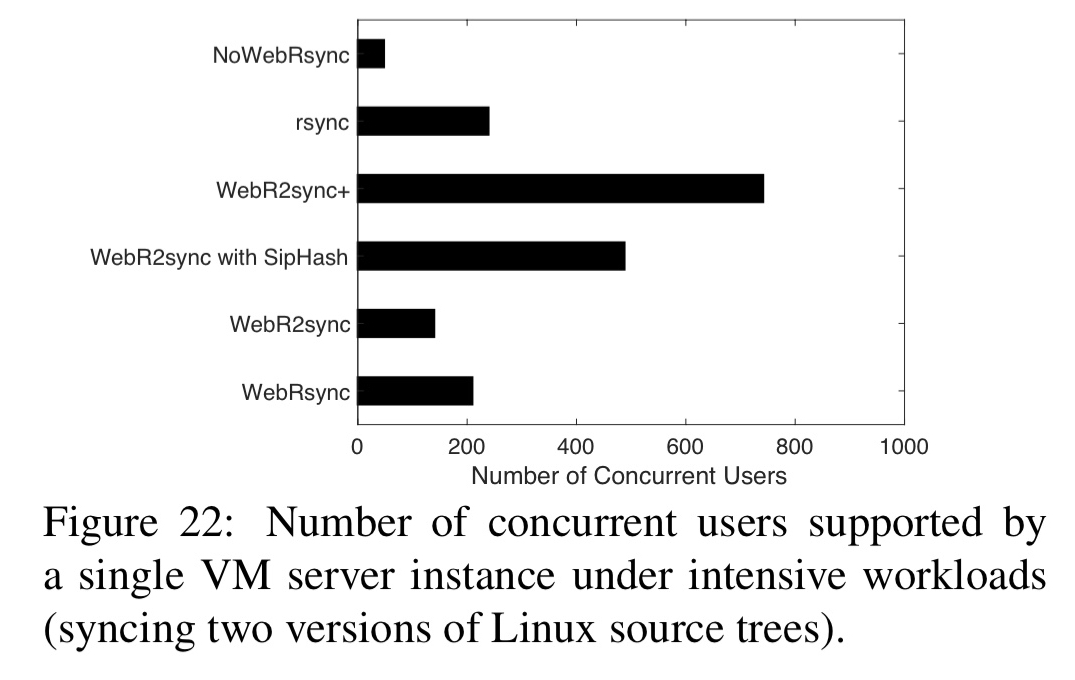
The resulting solution, WebR2sync+, outpaces WebRsync by an order of magnitude, and is able to simultaneously support 6800-8500 web clients’ delta sync using a standard VM server instance based on a Dropbox-like system architecture.
Porting rsync to WebRsync
The starting point in the journey was simply to implement rsync for the web…
To understand the fundamental obstacles of web-based delta sync, we implement a delta sync solution, WebRsync, using state-of-the-art web techniques including JavaScript, WebSocket, and HTML5 File APIs. WebRsync implements the algorithm of rsync, the de facto delta sync protocol for PC clients, and works with all modern web browsers that support HTML5.
Following rsync, the design looks like this:
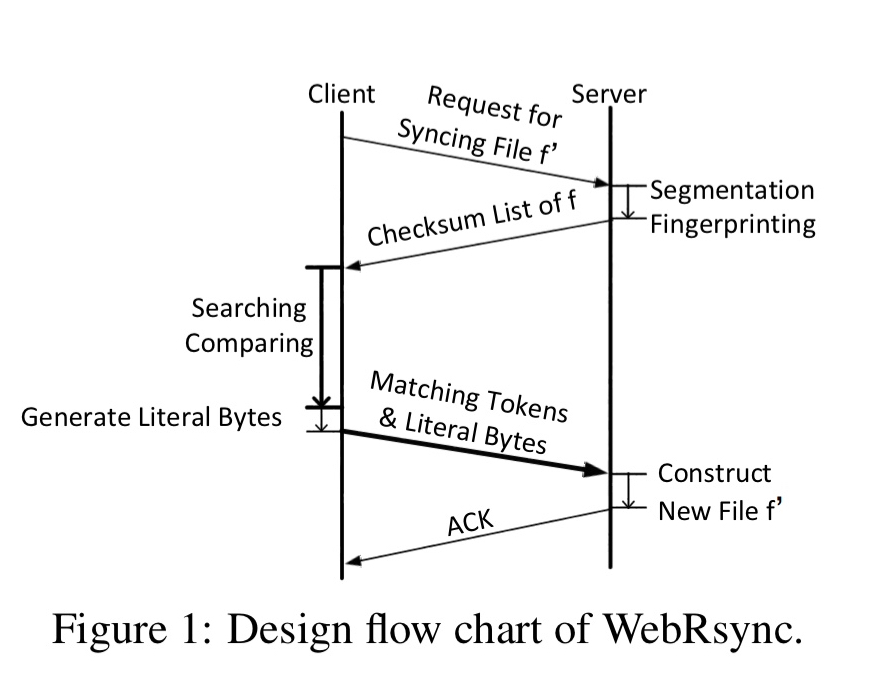
- The client initiates a request for file synchronisation
- The server executes fixed-size chunk segmentation and fingerprinting operations, returning a checksum list to the client.
- The client performs chunk search and comparison operations on the file using the checksum list.
- The result is a set of matching tokens (overlap between the stored file and the client’s version) and literal bytes representing the novel parts in the client version.
- The matching tokens and literal bytes are sent to the server for processing.
- The server returns an acknowledgement to the client to complete the process.
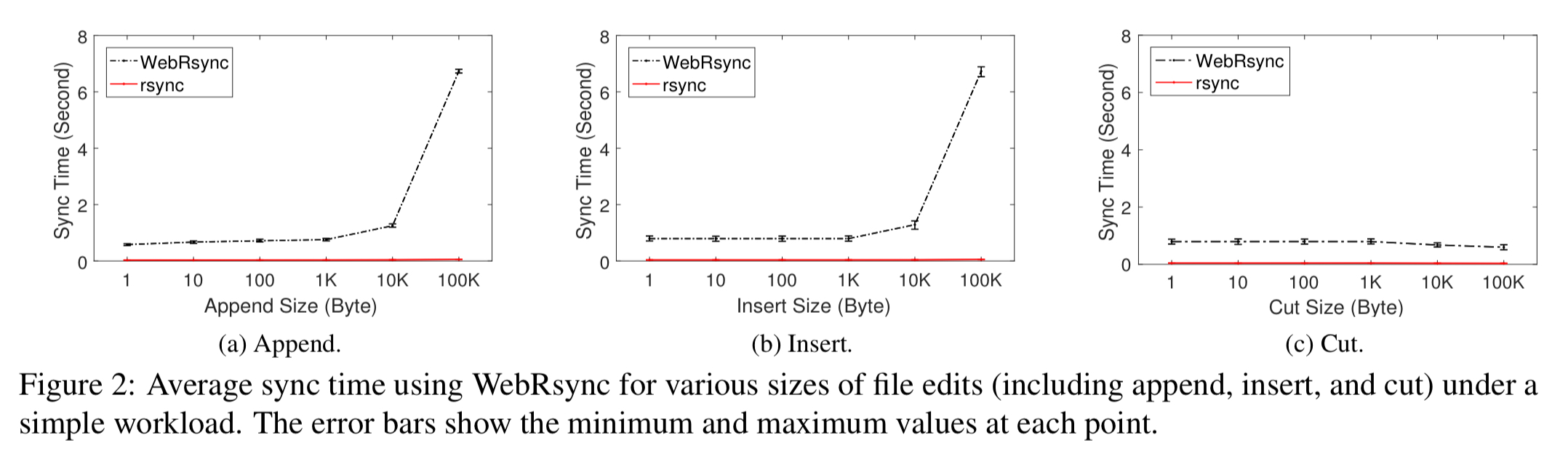
The bad news is that WebRsync is 16-35x slower than rsync on the exact same file edits.
Comparing rsync and WebRsync, it’s clear that most of the WebRsync overhead is on the client side.
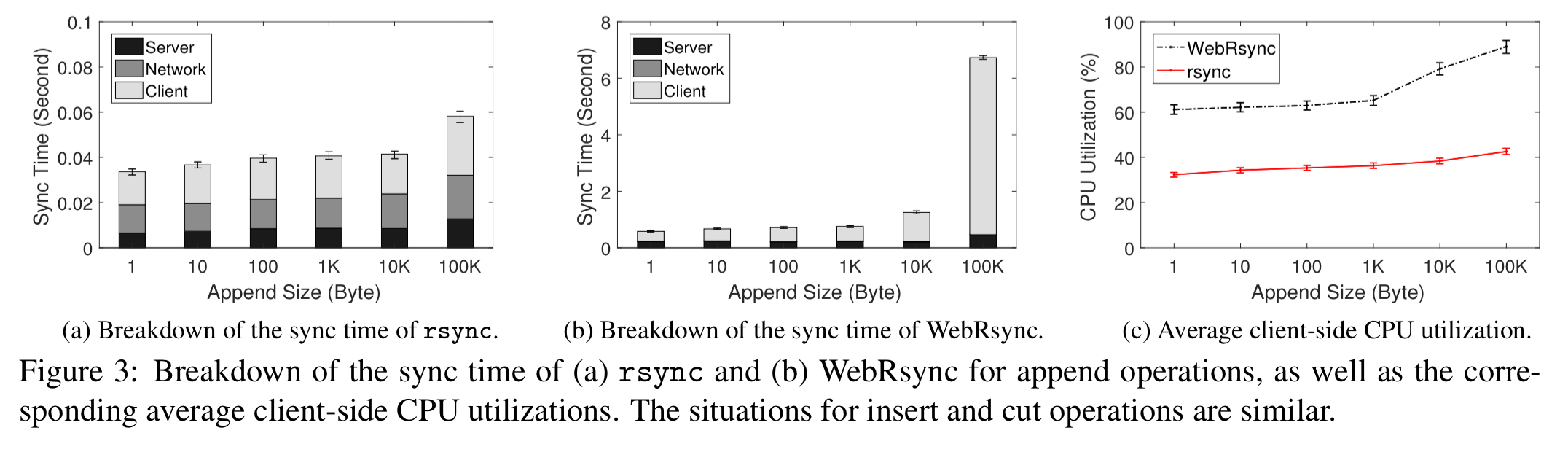
During the WebRsync process, the browser would also frequently stall and stop becoming responsive.
Improving WebRSync
To isolate performance issues to the JavaScript VM, the authors rebuilt the client side of WebRsync using the Chrome native client support and C++. It’s much faster:
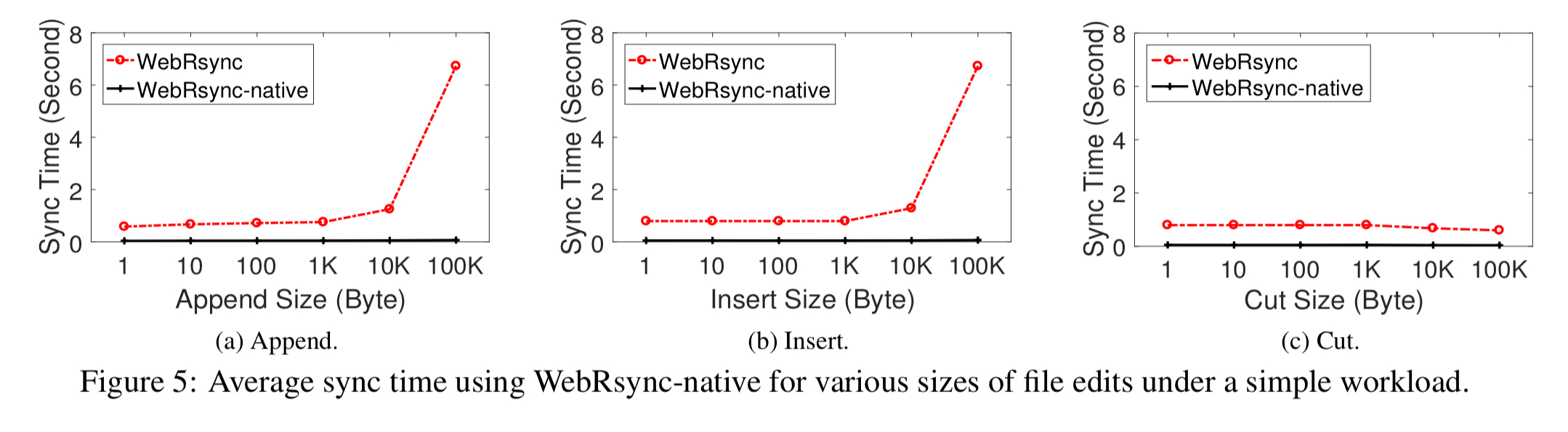
Unfortunately, this solution requires the user to download and install a plug-in, which impairs the usability and pervasiveness of the solution.
A second experiment uses web workers to do the heavy lifting in the background. This solves the browser hanging issues, but doesn’t meaningfully reduce the overall sync time or CPU usage.
Version 2: WebR2sync+
The core idea in WebR2sync is to move the search and comparison operations from the client to the server, swapping roles. The client generates a checksum list and sends it to the server, and the server does the generation of matching tokens. Literal bytes are still generated by the client though.
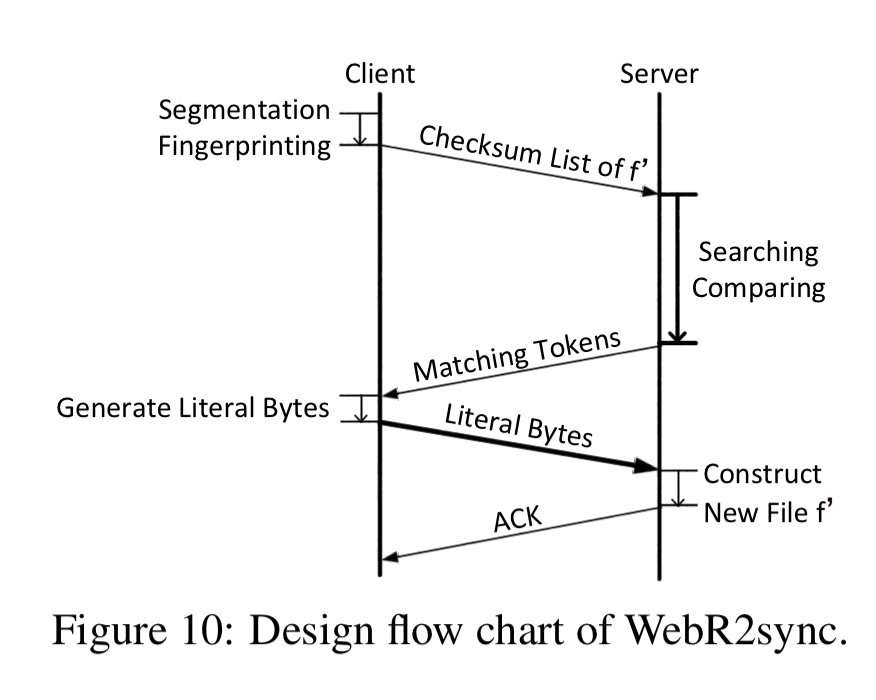
While WebR2sync significantly cuts the computation burden on the web client, it brings considerable computation overhead to the server side. To this end, we make two additional efforts to optimize the server-side computational overhead.
The first optimisation exploits the fact that most edits coalesce in a small number of areas in a file:
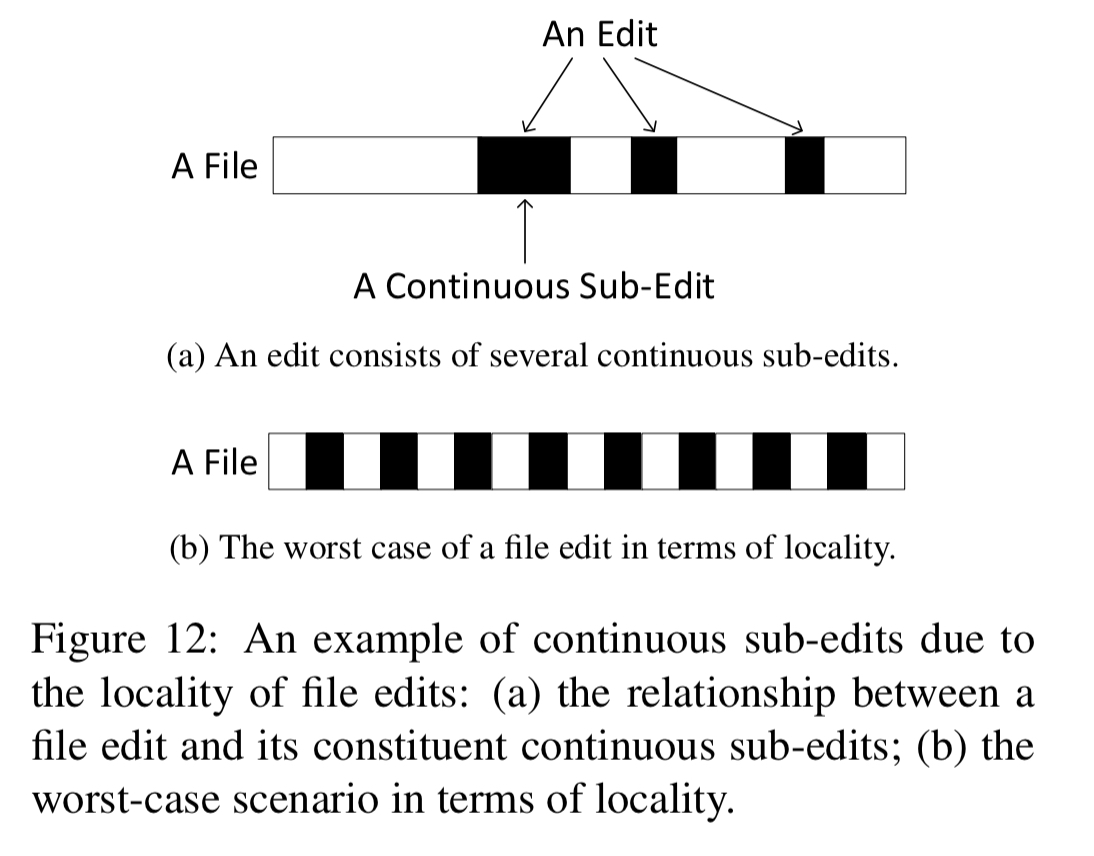
Full rsync (and WebRsync) uses a 3-level chunk searching scheme starting with a 16-bit hash code indexing into 32-bit rolling checksums, and finally to a 128-bit MD5 checksum. In WebR2sync+, when the i-th chunk has been shown to match, the assumption is made that the i+1-th chunk is likely to match also and the MD5 checksums are directly compared. “If the two chunks are identical, we simply move forward to the next chunk; otherwise, we return to the regular 3-level chunk searching scheme.”
The second optimisation is based on the observation that a full cryptographic hash is overkill for file chunk comparisons. The overhead of MD5 is around 5-6 cycles per byte, whereas SipHash has a computation overhead of around 1.13 cycles per byte with an acceptably low collision probability.
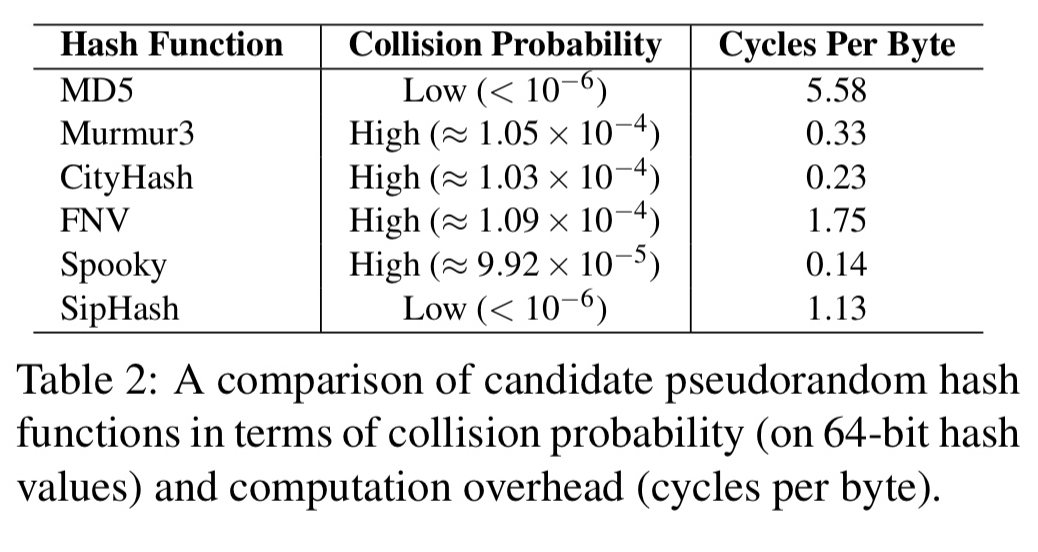
Replacing MD5 with SipHash reduces computation complexity by almost 5x. As a fail-safe mechanism in case of hash collisions, WebRsync+ also uses a lightweight full content hash check. If this check fails then the sync will be re-started using MD5 chunk fingerprinting instead.
Evaluation
The client side of WebR2sync+ is 1700 lines of JavaScript. The server side is based on node.js (about 500 loc) and a set of C processing modules (a further 1000 loc).
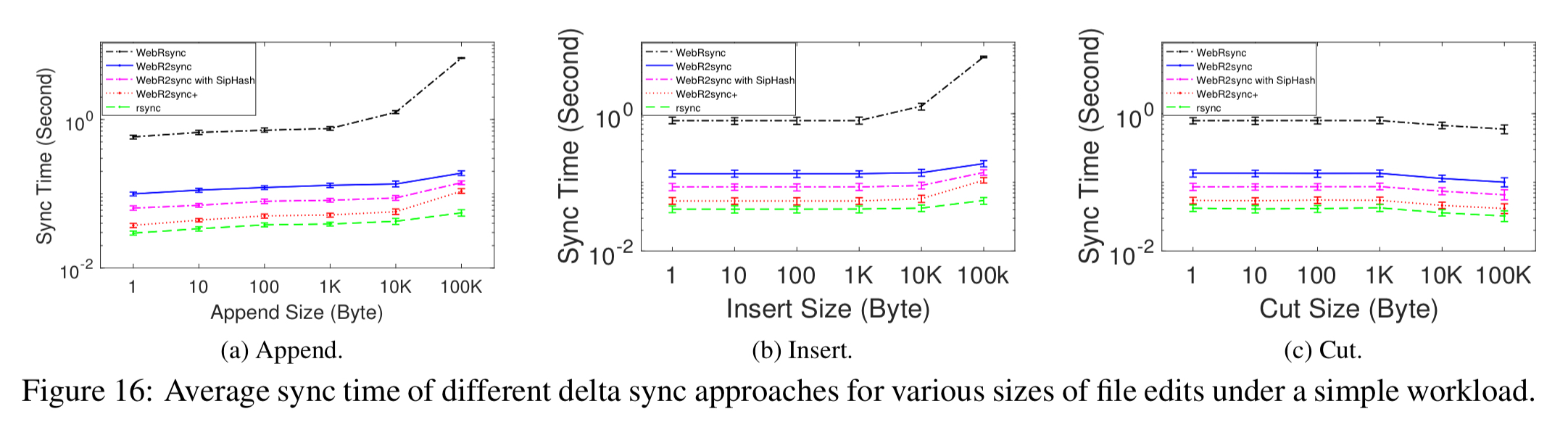
Comparing the red and green (bottom two) lines in the charts below, you can see that WebR2sync+ has sync times approaching those of rsync:
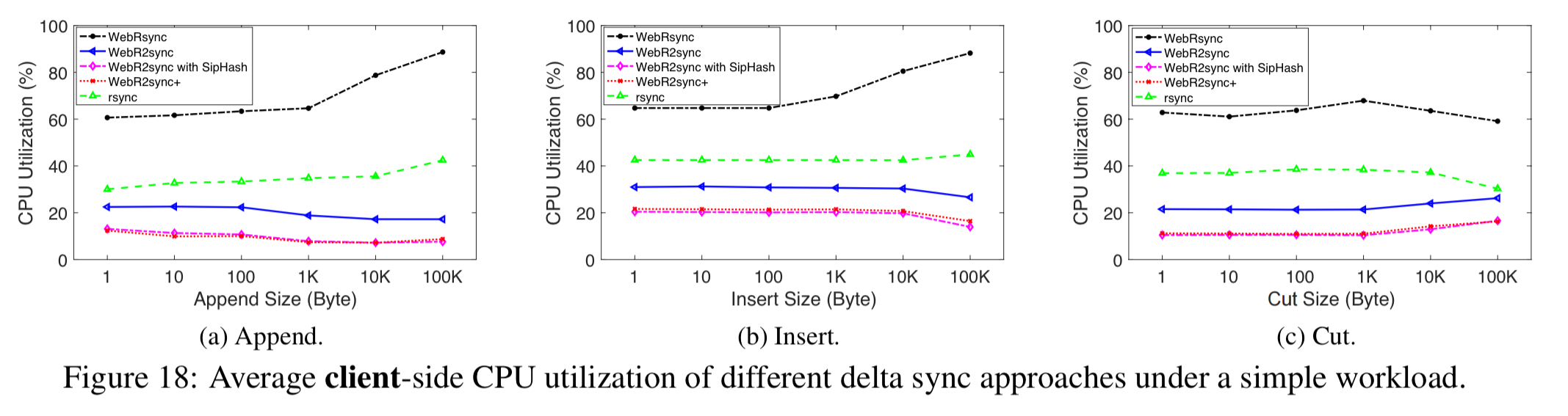
Client-side CPU utilisation is even lower than rsync (due to the swapping of roles):
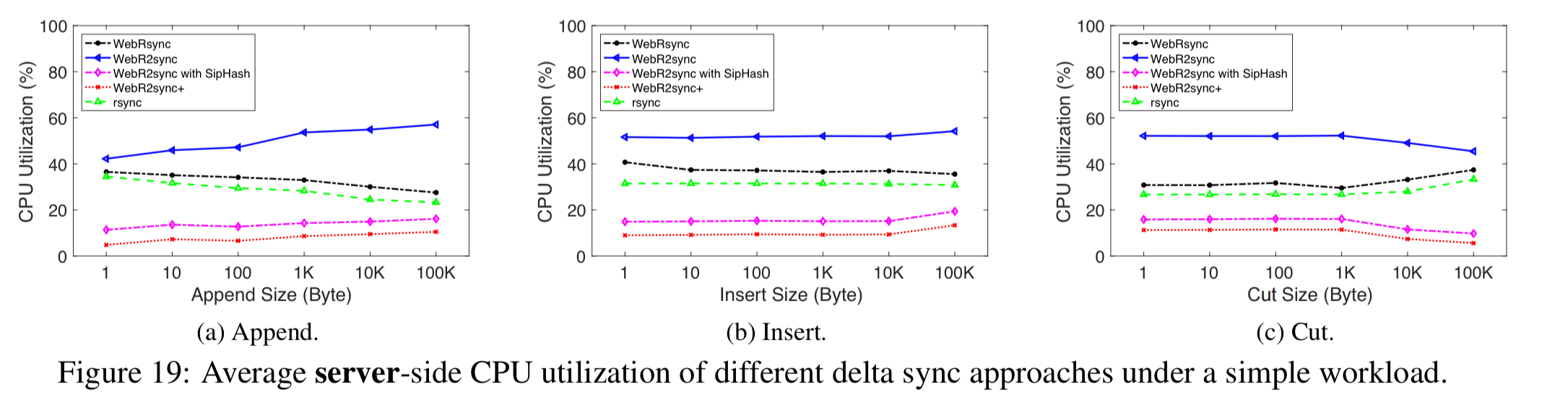
Looking at server-side utilisation, vanilla Web2Rsync (without the ‘+’ optimisations) consumes the most CPU. But with the two server-side optimisations in place, Web2Rsync+ actually has even lower server-side resource consumption than rsync.
Given this lower utilisation, Web2Rsync+ can support more concurrent clients:

I saw the total sync traffic numbers in the results section, but I didn’t see any upload vs. download comparison. Does anyone know if the authors have published those numbers? My ADSL crawls on upload, so I would benefit from a sync that reduced upload traffic.
Reblogged this on Elmar Klausmeier's Weblog and commented:
Very interesting article.
Some remarkable excerpts:
To isolate performance issues to the JavaScript VM, the authors rebuilt the client side of WebRsync using the Chrome native client support and C++. It’s much faster.
Replacing MD5 with SipHash reduces computation complexity by almost 5x. As a fail-safe mechanism in case of hash collisions, WebRsync+ also uses a lightweight full content hash check. If this check fails then the sync will be re-started using MD5 chunk fingerprinting instead.
The client side of WebR2sync+ is 1700 lines of JavaScript. The server side is based on node.js (about 500 loc) and a set of C processing modules (a further 1000 loc).