Emergent complexity via multi-agent competition Bansal et al., Open AI TR, 2017
(See also this Open AI blog post on ‘Competitive self-play’).
Today’s action takes place in 3D worlds with simulated physics (using the MuJoCo framework). There are two types of agents, ants:

And humanoids:

These learn to play against each other (ant vs ant, and humanoid vs humanoid) in four different games:

- Run to goal: agents start of facing each other in a 3D world, with goals each agent has a goal location on the opposite side of the world. The agent that reaches its goal first wins.
- You shall not pass: the same setup as run to goal, but now one agent (the blocker) is set the goal of blocking the other agent from reaching it’s goal. If the blocker is successful in this task and is still standing at the end of an episode then it wins. The opponent of course wins by reaching it’s goal.
- Sumo: The agents compete on a round arena, with the goal of either knocking the other agent to the ground or pushing it out of the arena.
- Kick and defend: a penalty shootout-like scenario in which one agent must kick a ball through a goal while the other agent defends.
The agents are trained using reinforcement learning with policy gradients using proximal policy optimisation. We’ll get into some of the details shortly. As with Alpha[Go] Zero that we looked at yesterday, the agents learn through self-play: training consists of playing lots of one-on-one contests between agents. Just as AlphaZero is taught nothing about chess openings, strategies, or tactics, so the agents in the 3D world are taught nothing of tactics, they simply know the reward they obtain at the end of play for meeting their objective (or not).
… a competitive multi-agent environment trained with self-play can produce behaviors that are far more complex than the environment itself.
The cool part of this paper is the behaviours that the agents discover all by themselves. Seeing is better than reading here, so if you have the time, take 2 minutes to watch this highlights reel:
- On Run-to-Goal, the ants demonstrate behaviours such as blocking, standing against opposing forces, using legs to topple the opponent and running towards the goal. The smaller humanoids try to avoid each other and run towards their goal really fast.
- On You-shall-not-pass the blocking humanoid learned to block by raising its hand, while its opponent eventually learned to duck underneath in order to cross to the other side.
- In Sumo, humanoids learn a stable fighting stance — as well as using their heads to knock into the opponent (no penalty for that in 3D world!).
- On Kick-and-defend the kicker learns to use its feet to kick the ball high and try to avoid the defender. It also makes dummy movements to try and fool the defender. In turn, the defender learns use its hands and legs to obstruct the ball.
There are no rewards for any of these behaviours, beyond the ultimate reward that is the outcome of the game. And yet once more, watching the agents in action, they feel quite ‘human’ in their strategies.
These discovered skills show a degree of transference to other tasks too: taking an agent trained on Sumo and subjecting it to strong wind forces, the agent manages to stay upright despite never experiencing windy environments before.
So that’s the fun stuff. Now lets take a look at some of training techniques used under the covers.
Training agents using self-play
When trained with self-play, the competitive multi-agent environment provides the agents with a perfect curriculum. This happens because no matter how weak or strong an agent is, an environment populated with other agents of comparable strength provides the right challenge to the agent, facilitating maximally rapid learning and avoiding getting stuck.
Agents are trained using a distributed training system. The policy network produces a probability distribution over possible actions, and then an action to take is sampled from this distribution. Rollouts (self-play) continue from this point to figure out the ultimate outcome, and the PPO (proximal policy optimisation) gradient algorithm is used update the network. (Andrej Karpathy has a good overview of deep reinforcement learning with policy networks and policy gradients on his blog).
Essentially, we do multiple rollouts in parallel for each agent and have separate optimizers for each agent. We collect a large amount of rollouts from the parallel workers and for each agent optimize the objective with the collected batch on 4 GPUs… we estimate the generalize advantage estimate (GAE) from the full rollouts. This is important as the competitive reward is a sparse reward, which is only given at the termination of the episode.
A number of other factors needed to be taken into account during training: encouraging the agents to explore, stopping them from getting stuck in a rut with particular opponents, and keeping enough randomisation in the world to prevent overfitting. We’ll look at each of these in turn next.
Encouraging exploration
The agents aren’t likely to achieve much success unless they learn some basic motor skills such as the ability to walk. Hence they only very small chances of receiving rewards. “This is the general reinforcement learning problem of training from sparse reward which is ac active area of current research.”
The problem is solved by adding extra rewards (dense rewards) in the beginning phase of training to allow agents to learn basic motor skills. These exploration rewards are gradually reduced to zero as training progresses, in favour of the overall competition reward, using a simple linear annealing factor. Typically the dense reward is a factor in about 10-15% of the training epoch.
Agents training without this exploration curriculum exhibit non-optimal behaviours. For example, in Sumo the agents just learn to stand and move towards the center of the arena. It also takes more samples to train them.
Mixing up opponents
We found that training agents against the most recent opponent leads to imbalance in training where one agent becomes more skilled than the other agent early in training and the other agent is unable to recover.
The fix for this is to train against randomly selected older versions of the opponent rather than simply always using the most recent. The following tables show the results in Sumo training for the humanoid and ant agents ($\delta = 1.0$ corresponds to the most recent agent, and 
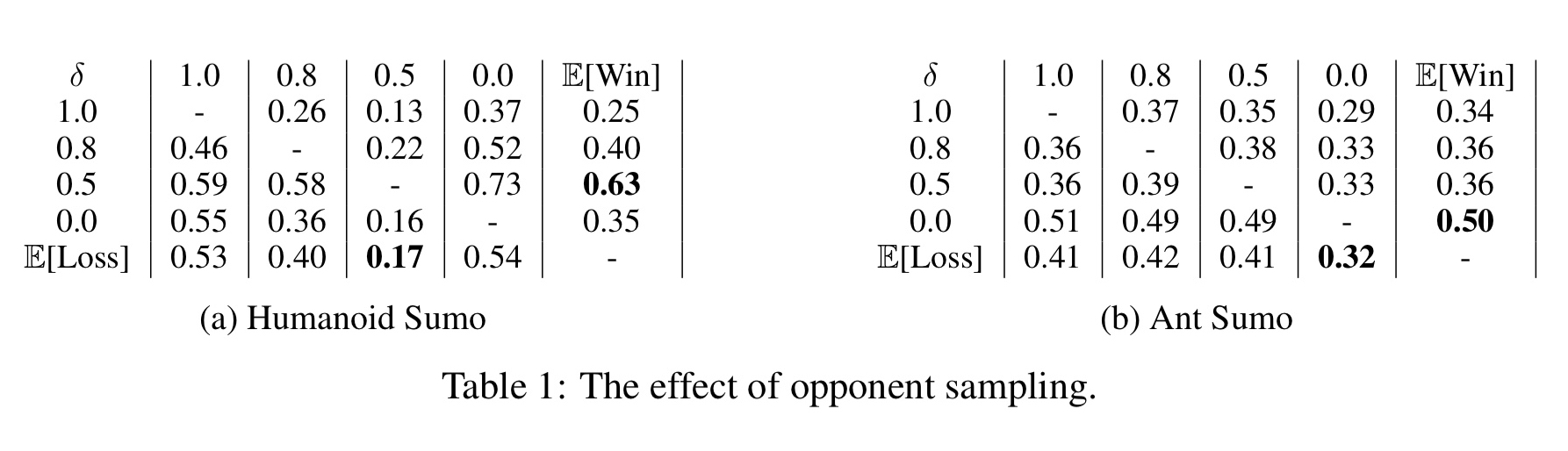
Sampling over the whole history works best for ants, but for humanoids 
The differences in these win-rates for different sampling strategies show that the choice of the opponent during sampling is important and care must be taken while designing training algorithms for such competitive environments.
Another related problem is overfitting to the behaviour of the opponent when trained for long periods, resulting in policies that don’t generalise well to new opponents. To overcome this, multiple policies (an ensemble) are learned simultaneously — in each rollout one of the other policies is selected at random as the opponent.
We find that training in ensemble performs significantly better for the humanoid body, whereas for ant the performance is similar to training a single policy. Again we suspect this is because there is not enough variability in the behavior of ant across different runs.
Mixing up the world
With little or no variation in the environment agents can also overfit. For example, running straight to the expected location of the ball in a game of Kick-and-Defend. Too much randomisation is a problem in the other direction: with a lot of randomisation in ball and agent positions, agents are unable to learn to kick. The solution is to start with a small amount of randomisation, which is easier for the agents to solve, and then gradually increase the randomisation during training.
We found this curriculum to work well for all the environments.
In conclusion
By adding a simple exploration curriculum to aid exploration in the environment we find that agents learn a high level of dexterity in order to achieve their goals, in particular we find numerous emergent skills for which it may be difficult to engineer a reward. Specifically, the agents learned a wide variety of skills and behaviors that include running, blocking, ducking, tackling, fooling opponents, kicking, and defending using arms and legs.
