Tail attacks on web applications Shan et al., CCS’17
This paper introduces a stealthy DDoS attack on classic n-tier web applications. It is designed to push the tail latency high while simultaneously being very hard to detect using traditional monitoring tools. The attack exploits ‘millibottlenecks’ — caused by buffers in the system that fill up when subjected to a short burst of traffic — by sending timed pulses of attack traffic.
Tail attacks aim to create very short (hundreds of milliseconds) resource contention (e.g., CPU or disk I/O) with dependencies among distributed nodes, while giving an “unsaturated illusion” for state-of-the-art IDS/IPS tools leading to a higher level of stealthiness.
The attacker sends short “ON” bursts of attack traffic, where the duration of a burst is typically on the order of milliseconds. These are followed longer “OFF” periods in which the target system can cool down, clearing up the queued requests and returning to a lower utilisation state.
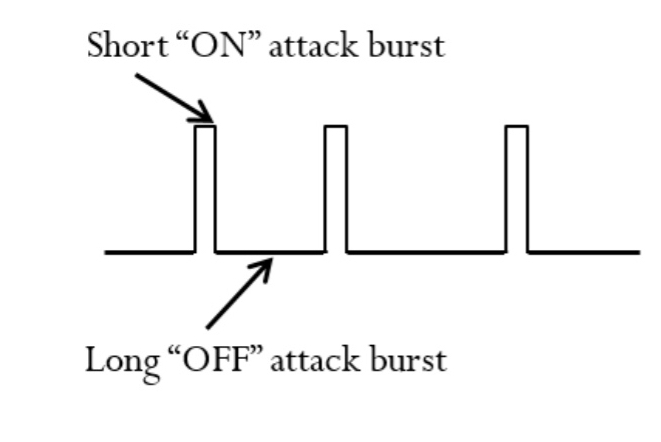
When an attack pulse is sent, resource millibottlenecks occur in one of the tiers (assuming the pulse parameters are set accordingly).
A millibottleneck stops the saturated tier processing for a short time (order of milliseconds), leading to the filling up of the message queues and thread pools in the bottleneck tier, and quickly propagating the queue overflow to all the upstream tiers of the n-tier system.
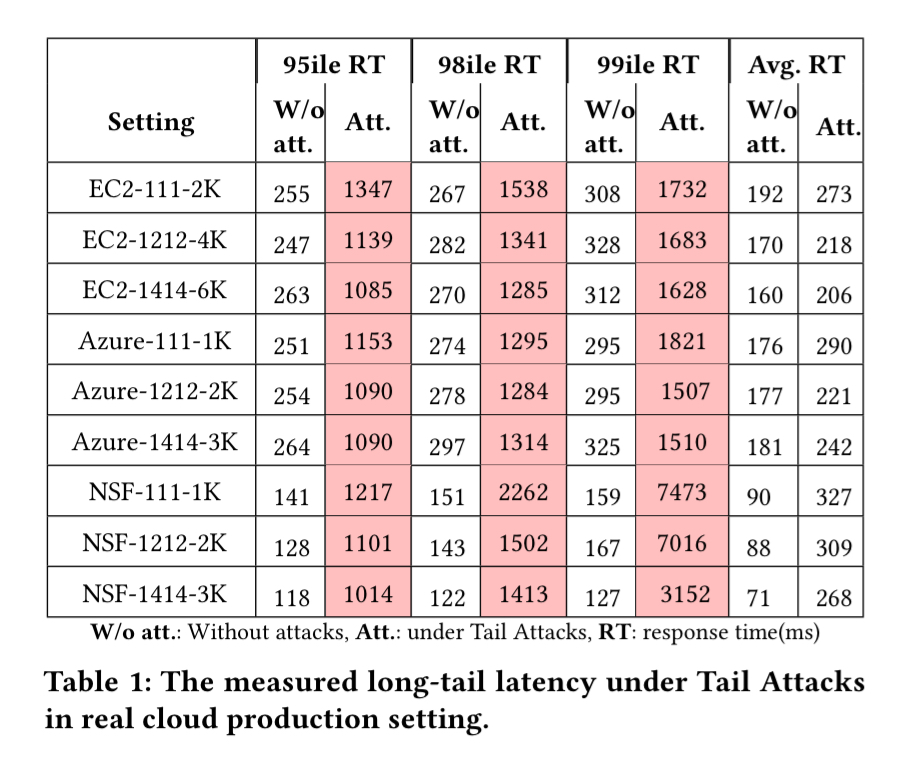
Once things are backed up all the way to the front-end, incoming packets for new requests will be dropped, and end-users may see very long response times (on the order of seconds). Testing across EC2, Azure, and an academic cloud platform “NSF Cloudlab”, tail attacks show a 4x-8x increase in 95th percentile latencies when testing a variety of configurations of the RUBBoS n-tier web application benchmark.
Tail attack analysis
Tail attacks can be modelled using queueing networks. The following table shows the parameters in the model:
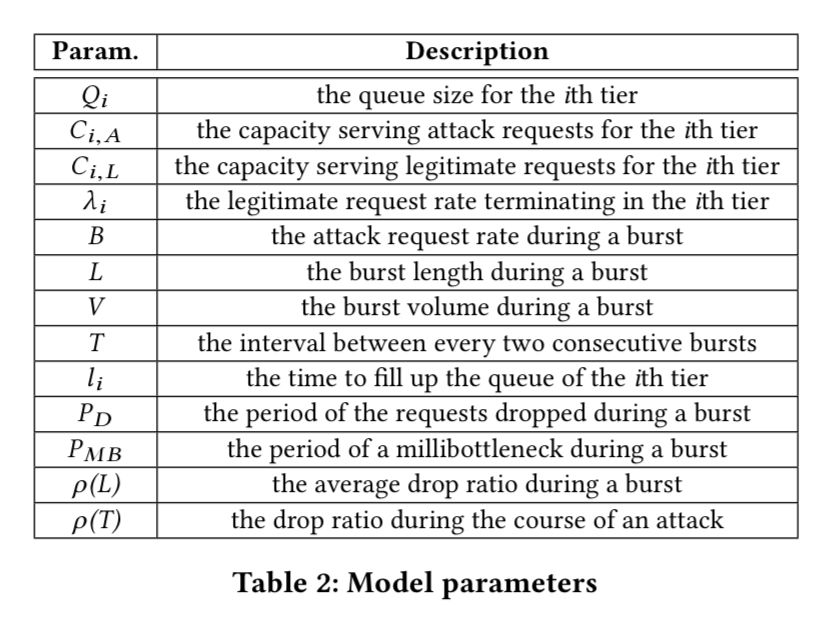
With reference to the parameters above, the attack volume during a burst is given by:

And the period of damage during which requests will be dropped is given by:

End-users with dropped requests perceive a long response time, which can be approximated by:

An attacker needs to choose attack parameters 
Maintaining optimal attack parameters using feedback control
Since baseline workloads vary (and so might system capacity), we need to dynamically adjust attack parameters to keep them in the sweet spot. Too little and the system will shrug the attacks off. Too much and detection mechanisms may be triggered.
Enter the feedback controller:
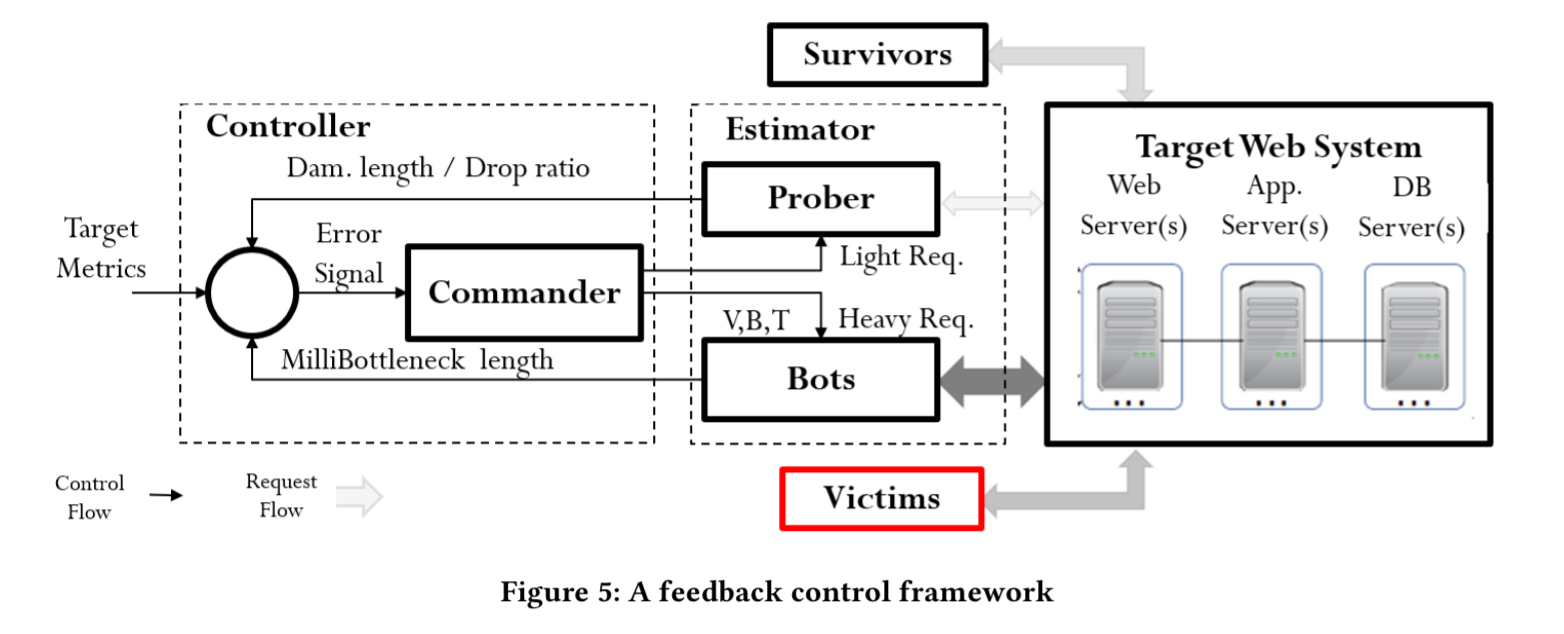
The controller is a Kalman filter which executes recursively for each new observation. First it creates an a priori estimate of the system state and error matrix, and then these are refined using the current measurement.
Using the Kalman filter, the Controller can predict the required attack parameters at the k-th burst given the historical results of all k-1 bursts, dynamically command the new parameters to the bots, and automatically and effectively launch Tail Attacks.
The observations needed by the filter are produced by the estimator. A “Prober” monitors attacks and is used to infer 


Tail attacks in action
The RUBBoS n-tier web application benchmark modelled on Slashdot is deployed in a variety of configurations across three cloud services. In the table below, the four digit (or three digit) notation #W#A#L#D represents the number of web servers, app servers, load balancers (may not be present) and database servers.
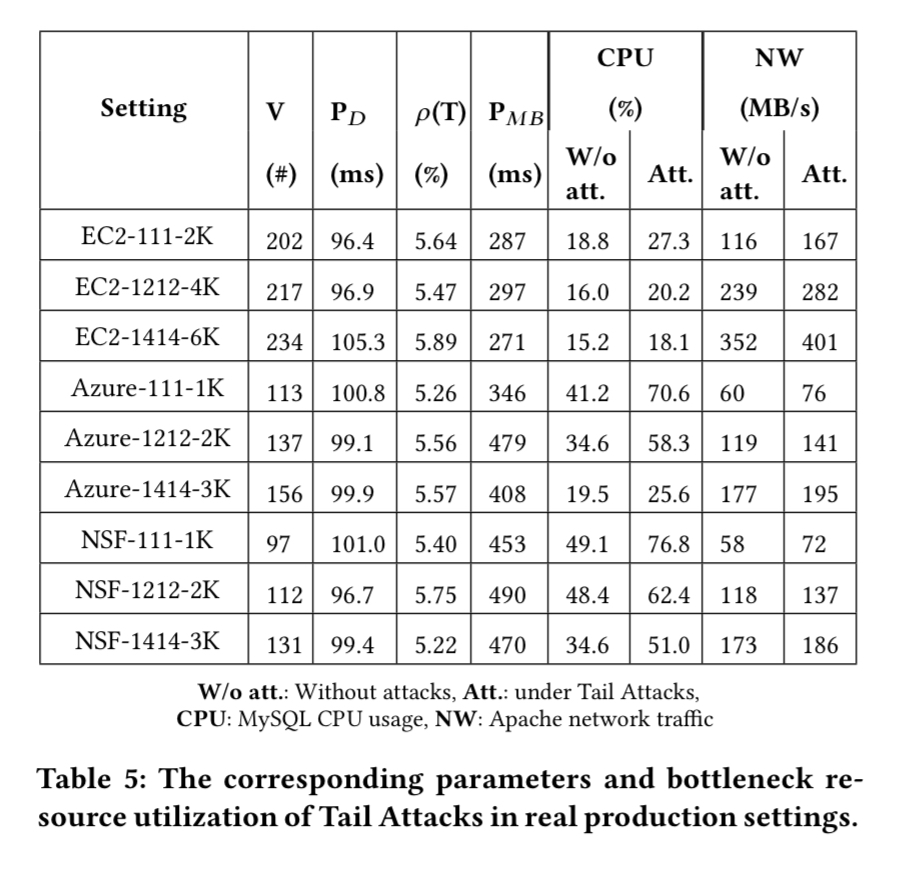
Columns 2 to 5 (in the table above) show the corresponding model parameters in our real cloud production setting experiments controlled by our attack framework. It clearly shows that our attacks controlled by our algorithm can achieve the predefined targets (5% drop ratio, damage length less than 100ms, millibottleneck length less than 500ms).
Here’s the same story plotted as a sequence of charts:
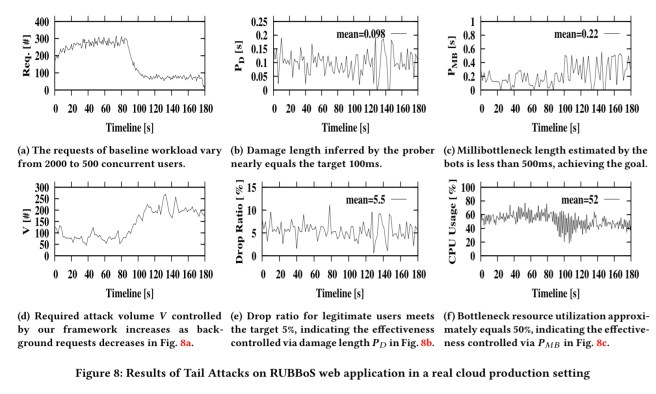
Detection and defence
Detecting and defending against Tail Attacks requires a three-pronged strategy:
- Fine-grained monitoring, with granularity less than the millibottlenecks period.
- Burst detection looking for potential attack bursts where requests are dropped, cross-tier queues are overflown, millibottlenecks (on e.g. CPU or I/O) occur, and there is a burst of requests.
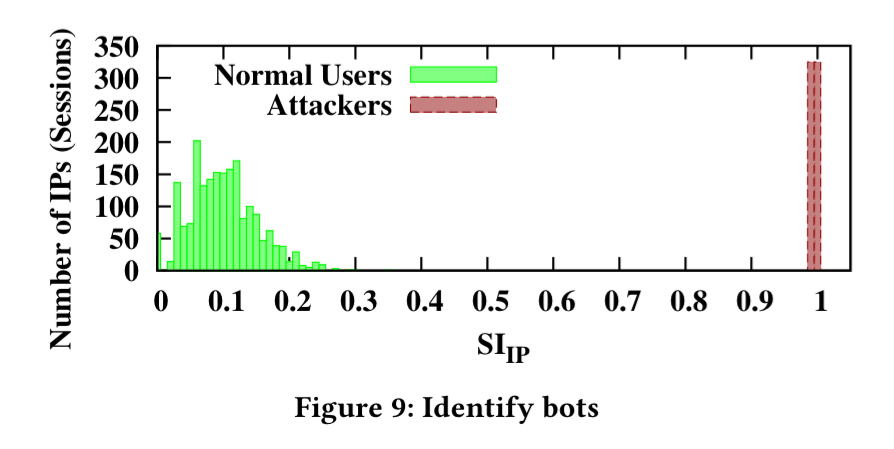
- IP-based statistical analysis to try and separate the bots from legitimate users.
For case 3, we can define a suspicion index for each IP address as:

Where 

Welcome to the emerging world of low-volume application DDoS attacks!

Isn’t the RuBBoS benchmark a bit too old?