ffwd: delegation is (much) faster than you think Roghanchi et al., SOSP’17
(Note: the paper link above should give you access to this paper in the ACM DL when accessed from The Morning Paper blog. If you’re subscribed via email and don’t otherwise have access, you might need to go via the blog site to access it. I didn’t find a publicly accessible pdf outside of this.)
As soon as we want to make use of more than one hardware thread to solve a given problem, then the question of coordination rears its head. Today’s paper choice examines mechanisms for providing safe and efficient access to shared variables and data structures across coordinating threads. Just as ‘Scalability, but at what CoST?’ challenged us to think about the overall performance of our systems in relation to what can be achieved with a single thread, so too does ffwd. The CoST paper showed us that many systems in fact never manage to outperform a single thread (or take very substantial resources to do so). In ffwd, the performance of a single thread is taken as an upper bound.
We’re interested here in shared data structures on multi-core systems, where those data structures are not naturally amenable to fine-grained locking (as, e.g., a hashtable is). Thus we need to take the equivalent of a coarse-grained lock to protect access to the structure. If we focus solely on the performance of the protected data structure (operations per second), then it’s clear that throughput will be upper-bounded by a single thread with permanent exclusive access.
Access to shared data structures is a common performance bottleneck in concurrent programs, which has spawned a range of approaches aimed at improving performance and scalability. Synchronization through mutual exclusion (locking) remains the most popular scheme for access to shared variables, and the design of efficient and scalable locks has been a rich topic of research for decades.
In place of these schemes, ffwd uses delegation: a hardware thread is dedicated to the data structure, and all accesses must go through that thread. Contrary perhaps to expectations, such a simple design turns out to be very competitive:
By definition, the performance of a fully delegated data structure is limited by the single-thread throughput of said data structure. However, due to cache effects, many data structures offer their best performance when confined to a single thread.
With powerful servers offering multiple hardware threads, such that dedicating a thread to a critical shared data structure is affordable, maybe we’ll see increasing use of delegation in the future. For data structures suitable for delegation (i.e., those that perform best on a single thread), ffwd can often improve performance by an order of magnitude compared to locking and other methods!
We expect delegation to consistently outperform coarse-grained locking on multi-core systems… Fine-grained locking can outperform delegation under the right circumstances. In particular, long critical sections are better suited to fine-grained locking, due to the added parallelism provided. For short critical sections, delegation is likely the better choice due to the per-lock throughput bound. Unless, that is, the data structure can be partitioned enough to support a large number of independent locks (e.g., a hash table).
One really nice thing about the delegation approach is that you don’t need to design a specialised highly concurrent data structure – the single dedicated thread accessing the structure hides you from any concurrency concerns.
For the rest of this piece we’ll first undertake a mini-tour of approaches to managing shared data structures so that we can get our bearings. Then we’ll look at what fundamentally limits the performance of locking and delegation-based approaches, before using that information to inform the design of ffwd. Finally, we’ll look at a selection of the evaluation results to get a feeling for how well ffwd works in practice.
A quick review of shared data approaches
- Spinlocks spin on a shared memory location until a lock is acquired. They outperform other lock types in low contention settings, but suffer from scalability problems under high contention.
- Queue-based locks spin on a local memory location rather than the global lock, polling only the previous lock-holder’s state. This improves fairness and reduces cache coherence communication, but can lead to complex memory management and they are slower than spinlocks under low contention.
- Lock-free data structures replace locks with speculative modifications that are then committed through a single atomic operation (often compare-and-swap). They can be more efficient than locking, but when highly contended frequent retries can lead to poor performance.
- Read-Copy-Update (and the related Read-Log-Upadte) provide lock-free access to readers while ensuring mutual exclusion to writers. “The overall idea is to maintain multiple versions of the same data structure, and only reclaim an old version after all readers have finished using it.” RCU is best suited to data structures that are infrequently updated.
- Software transactional memory generalises the speculative execution ideas behind lock-free data structures to arbitrary programs. During a transaction initiated by a programmer, every store to memory is buffered, and every read is logged, established the transaction’s read set. The STM commits writes to memory at the end of the transaction, if no concurrent modifications were made to values in the read set. Again, STM is not efficient for highly-contended data structures.
- Delegation and combining: delegation uses a dedicated server thread to operate on a shared data structure on behalf of client threads. In the combining variation, threads add work to be done to a list, and then one of the threads becomes the server/combiner by acquiring a global lock. ffwd does not employ combining.
In the limit: locking vs delegation performance bounds
Single-lock performance turns out to be constrained by interconnect latency, and delegation by server processing capacity (see §2 in the paper). The figure below plots number of critical sections per seconds (Mops) against varying critical section lengths:
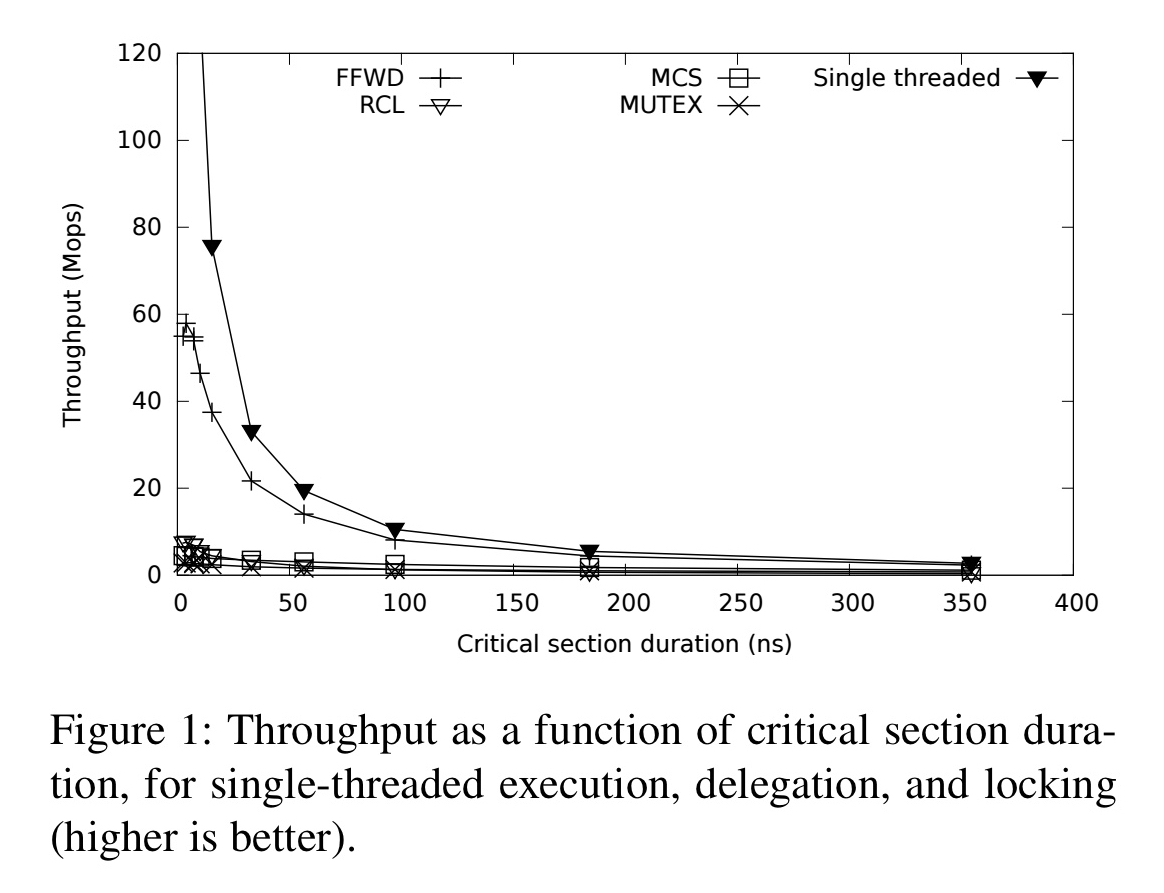
The shorter the critical section, the higher the relative locking overheads.
Delegation also benefits from enhanced memory locality. The following plot illustrates this effect when the critical section is updating a variable number of randomly selected elements within a 1Mb statically allocated array. “The lack of contention for the elements, and the effective use of the LLC cache, allows ffwd to substantially outperform the other approaches across the range.”
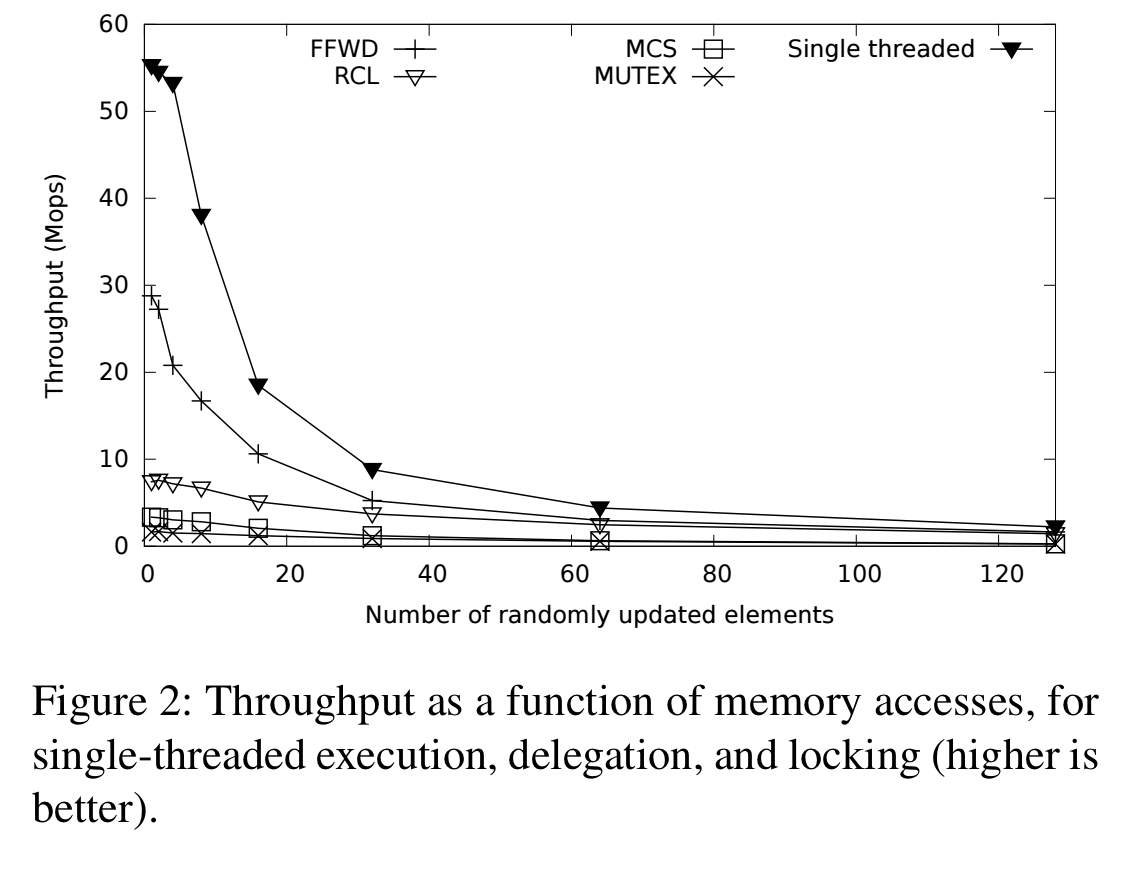
fast, fly-weight delegation (ffwd)
ffwd provides a super-simple interface:
FFWD_Server_Init()starts a server thread, and allocates and initialises the request and response linesFFWD_Delegate(s, f, retvar, argc, args...)delegates function f to server s, with specified arguments, storing the return value in retvar.
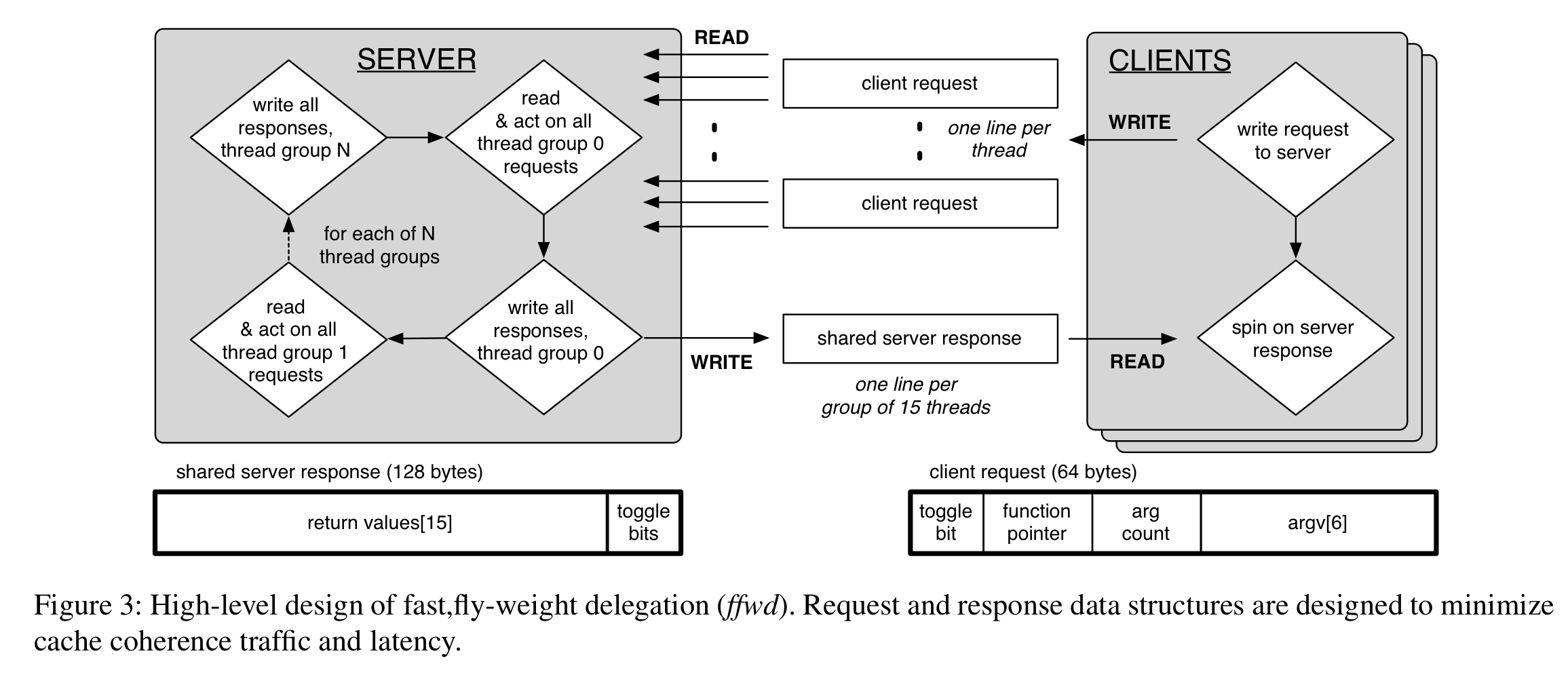
The overall design looks like this:
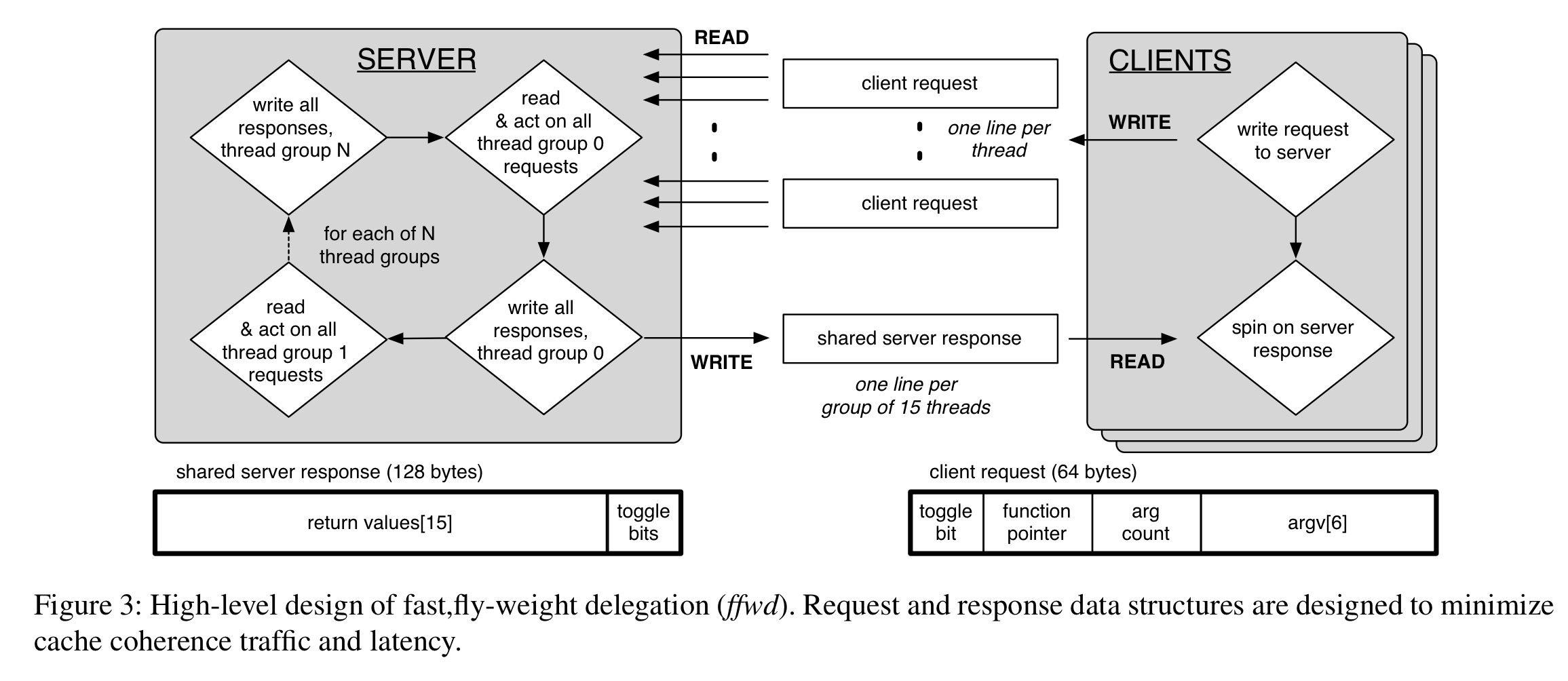
(Enlarge).
The design is described in terms of a system with 64-byte cache lines and up to 32 threads per socket. Each client core maintains a a dedicated 128-byte request cache line pair which is exclusively written to by the hardware threads of that core, and read only by the server. A client writes to its request line, then spins on its dedicated response sole with its 128-byte response line pair. The server processes requests in a round-robin, socket-batched fashion, polling all request lines and handling any new requests from one socket before proceeding to the next. Individual return values are locally buffered until processing for the current response group has finished, then written back all together.
Requests contain a toggle bit that indicates the state of each individual request/response channel. When the request and response toggle bits for a given client differ, a new request is pending. When they are equal, the response is ready.
The authors highlight six key aspects of the design:
- On Intel’s Xeon family, cache lines are 64 bytes, but the L2 cache of each core includes a pair prefetcher which treats memory as consisting of 128-byte line-pairs. Independent false-sharing-free memory access is thus only available in 128-byte granularity on Xeon. ffwd therefore chooses to work with 128-byte aligned line-pairs.
- One 128-byte line-pair is allocated per core for requests, split equally between the two hardware threads. The only contention is between the writing client and the reading server. “The server’s read request transitions the cache line to the shared (S) state and copies the contents over the interconnect, while the client’s subsequent write invalidates the server’s copy (without data transfer), and transitions the line to the modified (M) state.”
- One 128-byte line-pair is allocated per socket (up to 15 hardware threads) for responses. This contains the toggle bits and 8-byte return values. When copying responses, the toggle bits are copied last. The first subsequent read by a client transitions the cache line pair to the S state and copies the data. Subsequent reads by other clients on the same socket are served by their local last-level cache.
- Request and response lines are both allocated on NUMA nodes, which gave a substantial performance advantage. “We hypothesize that this NUMA allocation strategy avoids extra steps in the invalidation process…”
- There is minimal overhead in processing requests. The specified number of parameters are read from the request into the parameter passing registers, the specified function is called, and then the eventual return value is buffered for subsequent combined transmission.
- The server does not acquire any locks during its operation. Atomic operations are avoided because they are not reordered with respect to other loads and stores, degrading performance.
Evaluation
The evaluation section looks at both application level and and micro-benchmark experiments. I only have space here to share the briefest of highlights.
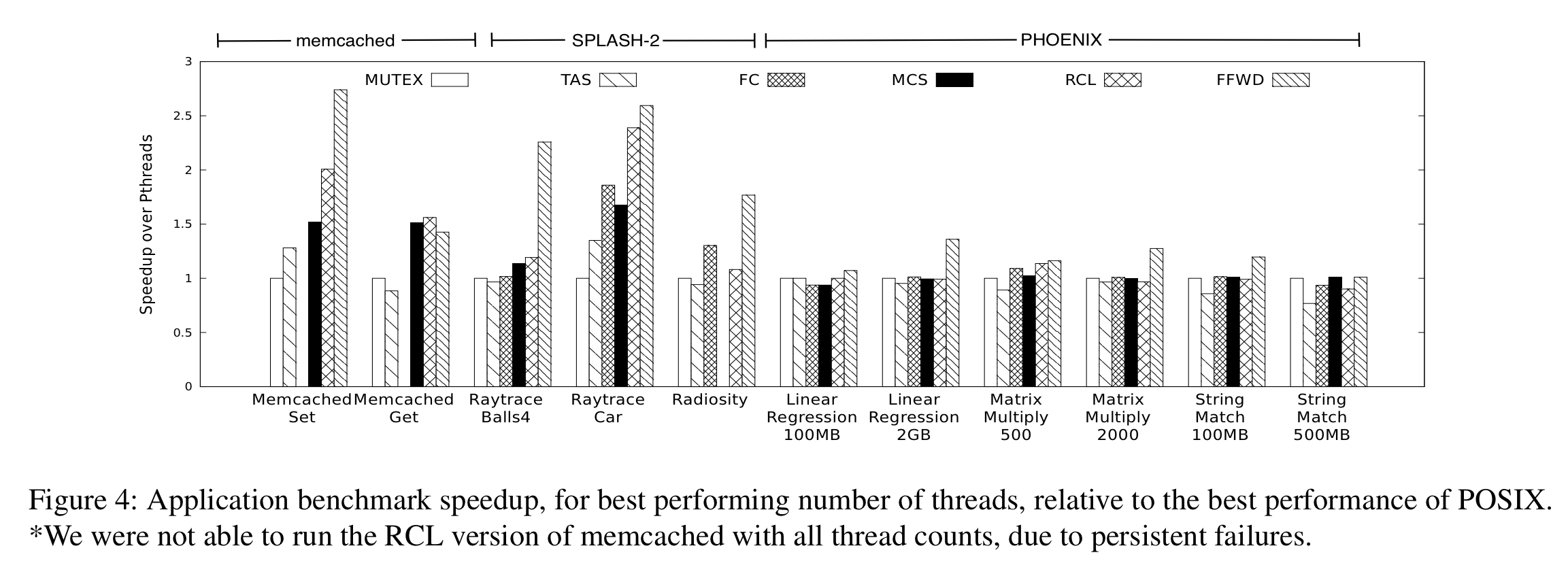
Here we see the results of the application level benchmarks, when using the ideal thread count for the respective method. In the figure below, MUTEX = a posix mutex lock, TAS = test-and-set spinlock, MCS = MCS locking, FC = flat combining delegation methods, and RLC is a prior art pure delegation method.
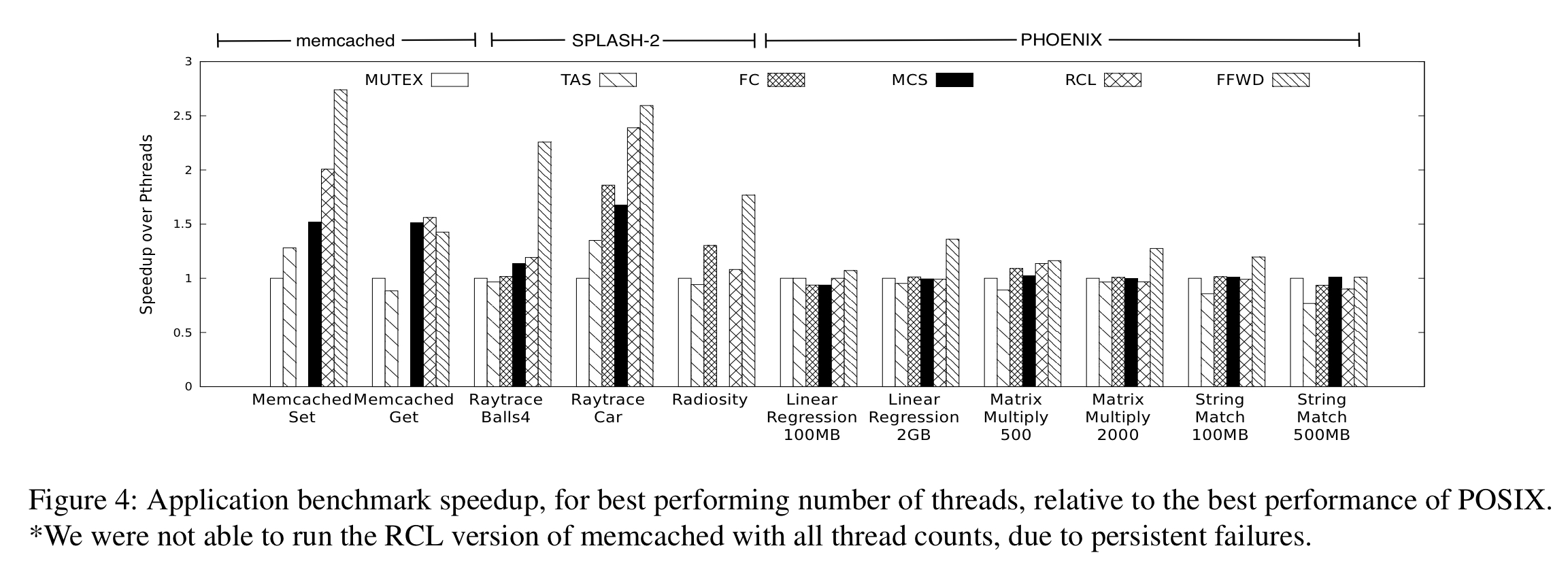
(Enlarge).
The advantages of ffwd can be further seen when looking at performance with varying numbers of threads (lower on the y axis is better in this chart):
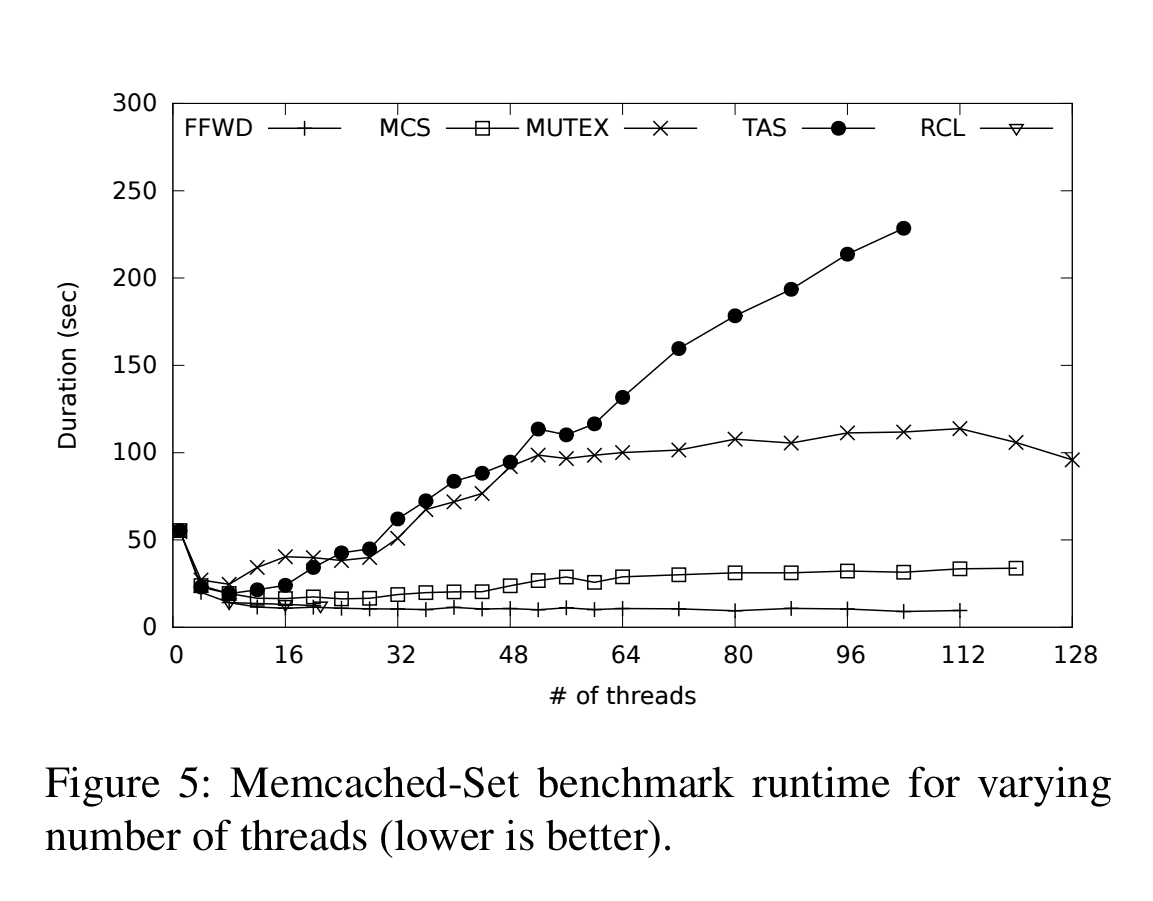
We find that for all benchmark applications evaluated, on all platforms tested, ffwd matches or outperforms all lock types (including combining), as well as RCL. Overall, the performance gains can be attributed to two main sources: eliminating contention for highly contended data structures, and improved memory locality, for all shared data.
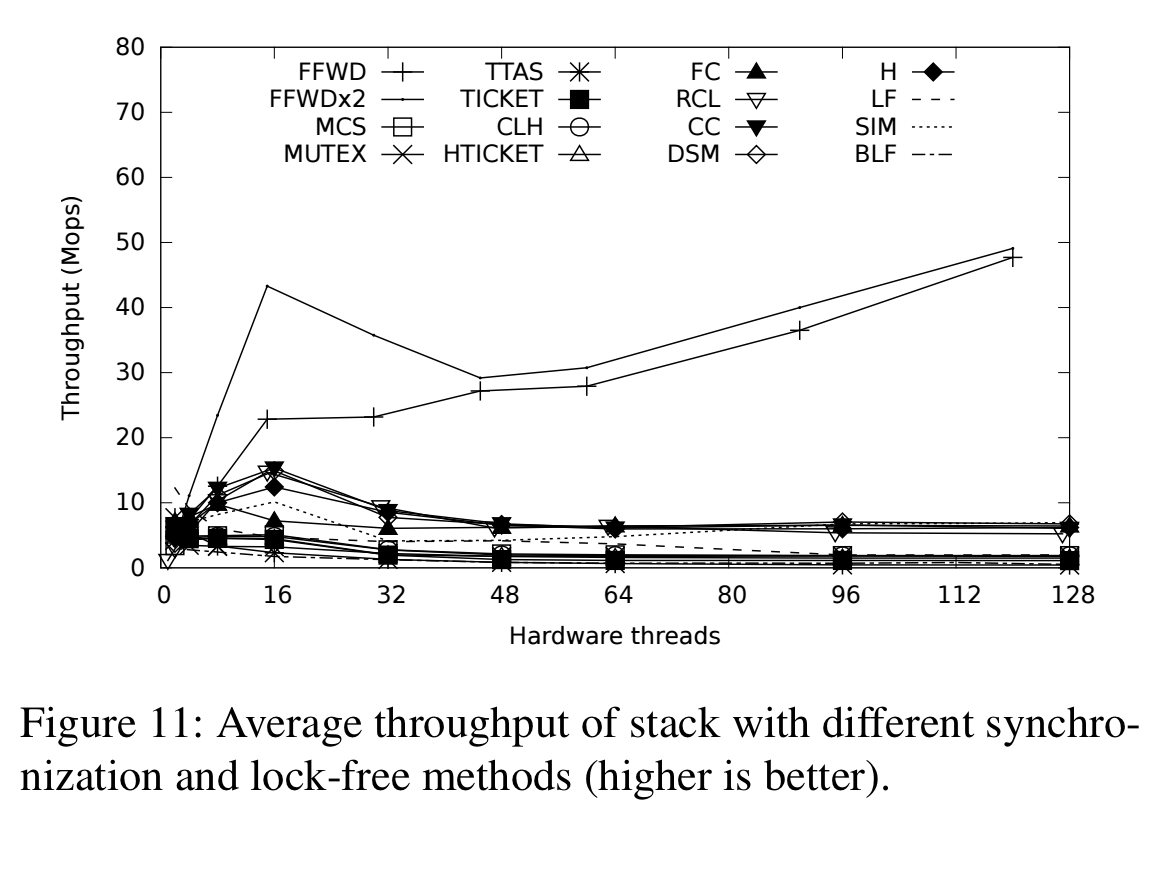
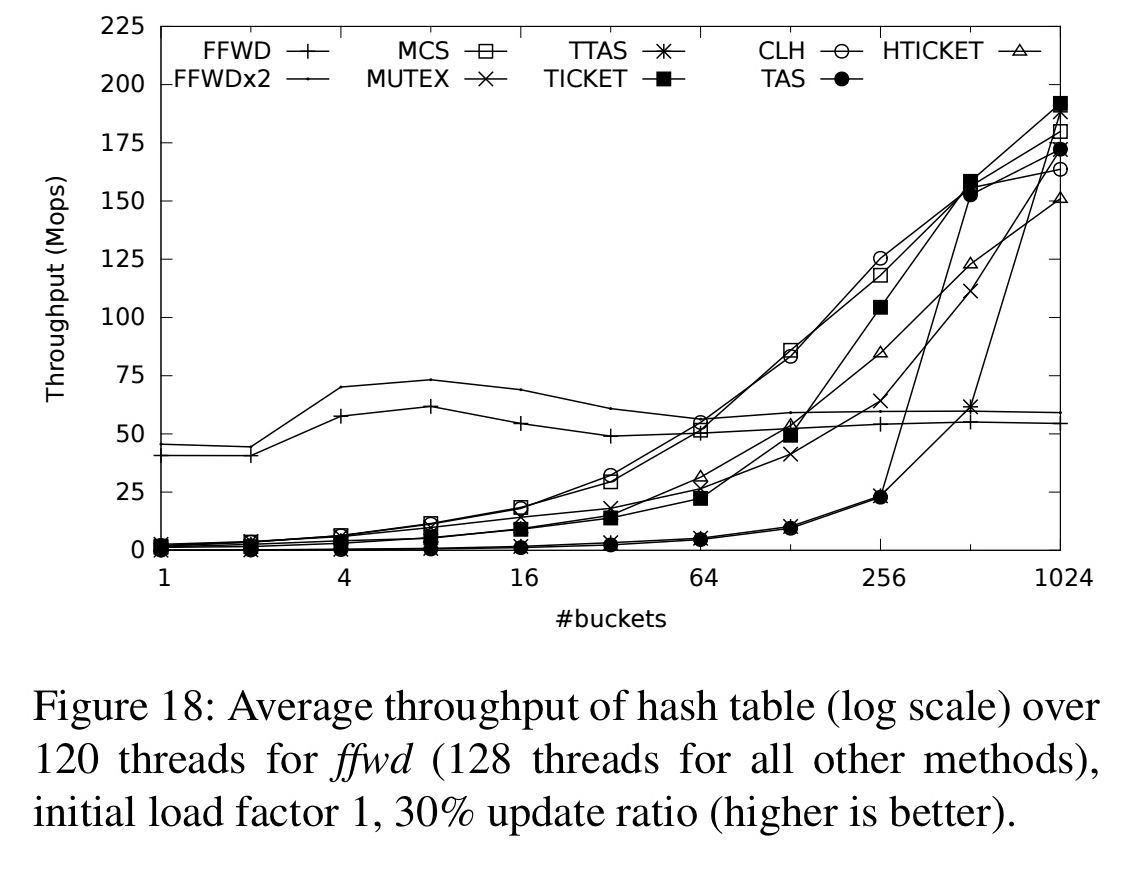
The micro-benchmarks example a fetch-and-add scenario (very short critical sections), queue and stack data structures, several varieties of linked-list, a binary search tree, and a hash table. Where the other methods can take advantage of finer-grained locking, ffwd is competitive up to 64-128 buckets, after which it starts to fall behind. In other scenarios it is very competitive. See §4 in the paper for the full details.

{kind=link}
{kind=link}
Where is the code?
https://github.com/bitslab/ffwd
Thanks
Thank you so much, adriancolyer! It’s cool!
Thank you so much, adriancolyer! It’s cool!
BTW, you can find the paper on the github too:
Click to access ffwd_techreport.pdf
Thanks for bringing attention to our work Adrian. It’s not just for high-powered servers – as everyday machines get more and more cores (how many of you have 10 cores in your smartphone?), we expect delegation to become a common design choice. What really makes ffwd stand out among other delegation schemes, however, is its outstanding performance.
Hi,
I’m an Erlang programmer. As Robert Virding pointed out, this sounds a lot like SMP Erlang. I believe what the blog post calls hardware threads are what Erlang refers to as scheduler threads.
Erlang’s green threads usually have an affinity to a scheduler thread (unless the scheduler decides to migrate them). A green thread “serves” a data structure needed by another, which usually (but not always) involves copying.
https://hamidreza-s.github.io/erlang/scheduling/real-time/preemptive/migration/2016/02/09/erlang-scheduler-details.html
https://github.com/erlang/otp/blob/master/erts/emulator/internal_doc/ThreadProgress.md
https://github.com/erlang/otp/blob/master/erts/emulator/internal_doc/ProcessManagementOptimizations.md
This is how Erlang has been doing things for over 25 years.
Amazing! Thanks for sharing ^^