Occupy the cloud: distributed computing for the 99% Jonas et al., SoCC’17
‘Occupy the cloud’ won the best vision paper award at the recent ACM Symposium on Cloud Computing event. In the spirit of a vision paper, you won’t find detailed implementation and evaluation information here, but hopefully you’ll find something to make you think. If I had to summarise the argument, I think it’s this: speed of deployment and ease of use coupled with good enough runtime performance wins. DevOps are the new Kingmakers. Follow that line-of-thought, and the authors take you to an interesting proposition: serverless could be the centrepiece of a new distributed data processing platform.
In this paper we argue that a serverless execution model with stateless functions can enable radically-simpler, fundamentally elastic, and more user-friendly distributed data processing systems. In this model, we have one simple primitive: users submit functions that are executed in a remote container; the functions are stateless as all the state for the function, including input, output is accessed from shared remote storage.
At this point the alarm bells are probably ringing. How on earth can you make that even remotely efficient when all you have are stateless functions and hence you’ll be serializing and deserializing all over the place?
Surprisingly, we find that the performance degradation from using such an approach is negligible for many workloads and thus, our simple primitive is in fact general enough to implement a number of higher-level data processing abstractions, including MapReduce and parameter servers.
What users want
Many more casual users of data processing platforms (the 99% from the paper title) don’t want to spend hours understanding a complex stack of e.g. Spark, Scala, HDFS, Yarn and the JVM. Even the choice of instance types (70 on AWS at the time the paper was written), cluster sizes, regions and so on can be bewildering.
… most software, especially in scientific and analytics applications, is not written by computer scientists, and it is many of these users who have been left out of the cloud revolution.
What do these users want? To get vastly better performance than available on their laptop or workstation while taking minimal development time.
For an interesting number of compute bound workloads, such as trying a large number of random initial seeds in a Monte Carlo simulations, or sweeping over a wide-range of hyperparameters in a machine learning setting (or even being guided through a set of input parameters by a system such as Vizier), it’s a big step forward to parallelise across functions, without necessarily worrying about intra-function optimisations.
Therefore, a simple function interface that captures sufficient local state, performs computation remotely, and returns the result is more than adequate.
Even for data-bound workloads, many users would be served by a simpler version of existing map-reduce frameworks with outputs persisted on object storage.
How simple can we make it?
Many of the problems with current cloud computing abstractions stem from the fact that they are designed for a server-oriented resource model. Having servers as the unit of abstraction ties together multiple resources like memory, CPU and network bandwidth. Further servers are also often long running and hence require DevOps support for maintenance. Our proposal is to to instead use a serverless architecture with stateless functions as the unifying abstraction for data processing.
Users can run arbitrary (data processing) functions without setting up and configuring servers/frameworks etc.
To make this work, you need a low overhead execution runtime, a fast scheduler, and high performance remote storage.
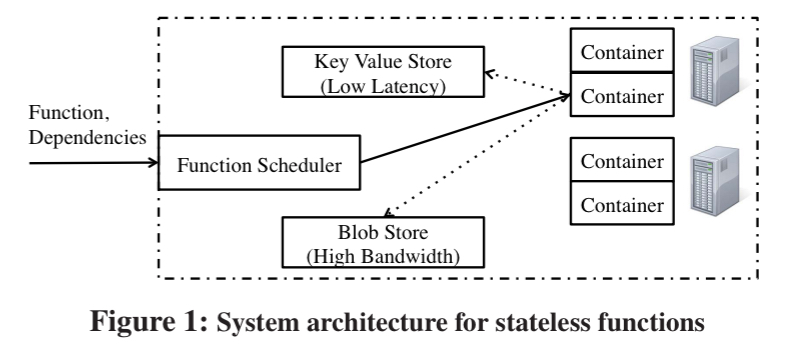
The architecture at the base level is very simple by design and just includes the basics needed to execute functions. More complex abstractions such as dataflow and BSP are implemented on top.
What makes this more tractable than in the past is that the benefits of colocation (of code and data) are diminishing. For example, on AWS EC2 writing to remote storage is faster than storing data on a single local SSD (though not than multiple SSDs). The gap between network bandwidth and storage I/O bandwidth continues to narrow though.
While the developer has no control of where a stateless function runs… the benefits of colocating computation and data – a major design goal for prior systems like Hadoop, Spark and Dryad – have diminished.
The PyWren prototype
It will probably come as no surprise to you to hear that the prototype is built on top of AWS Lambda. PyWren exposes a map primitive from Python on top of Lambda. On first encounter there’s a slightly weird thing going on whereby instead of having the users deploy Lambda functions directly, PyWren has just a single common Lambda function. PyWren works by serializing the user written Python functions using cloudpickle and storing the results in S3 buckets. The single PyWren Lambda function then loads both the data to be processed and the function to process it from S3, with the result being serialized back to S3 at a pre-specified key.
The stated reasons for doing it this way are:
- to eliminate the majority of user overhead from deployment, packaging, and code versioning.
- to mitigate the high latency for function registration
- to be able to execute functions that exceed Lambda’s code size limit
I would anticipate those advantages diminishing over time.
PyWren’s map API mirrors the existing Python API for parallel processing, and so integrates easily with existing libraries for data processing and visualization.
Calling
maplaunches as many stateless functions as there are elements in the list that one is mapping over.
The following benchmark results show the impact of using remote storage only and how that scales with worker counts.
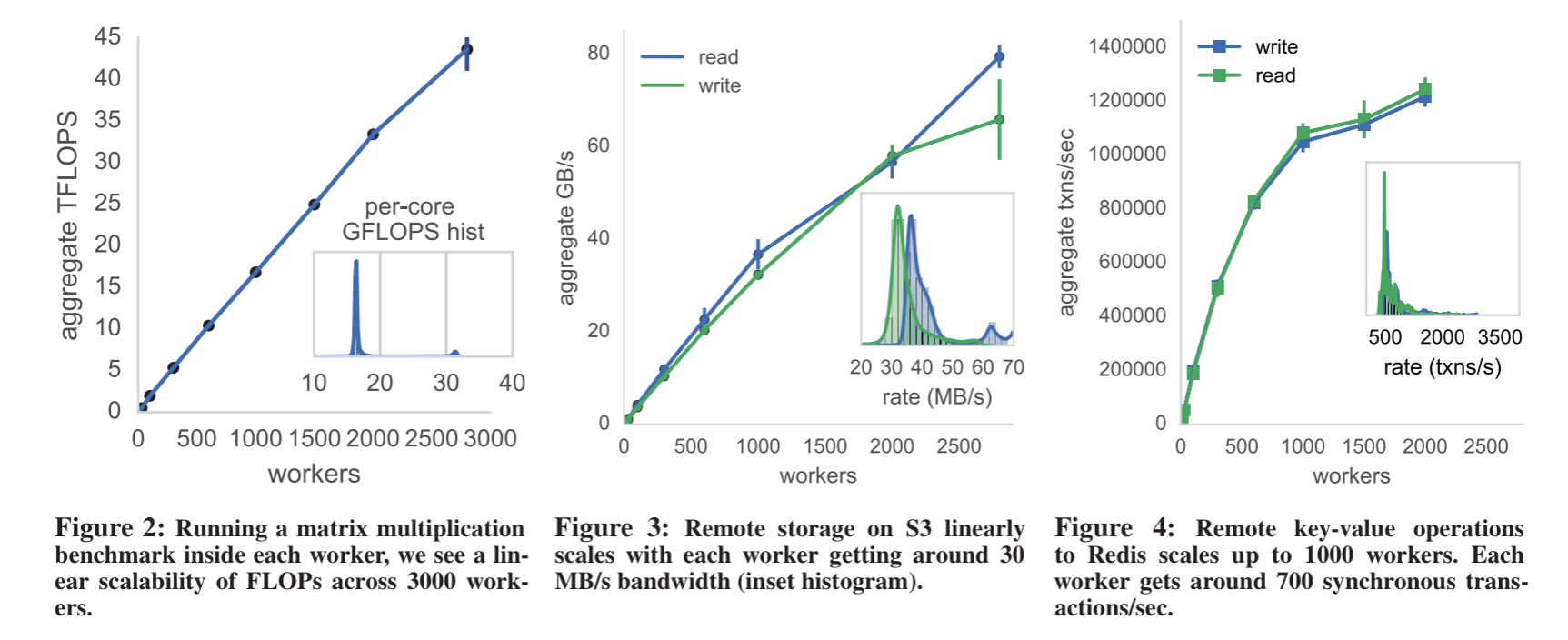
In our research group we have had students use PyWren for applications as diverse as computational imaging, scientific instrument design, solar physics, and object recognition. Working with heliphysicists at NASA’s Solar Dynamics Observatory, we have used PyWren for extracting relevant features across 16TB of solar imaging data for solar flare prediction. Working with applied physics colleagues, we have used PyWren to design novel types of microscope point-spread functions for 3d superresolution microscopy. This necessitates rapid and repeat evaluation of a complex physics-based optical model inside an inner-loop.
Beyond simple functions: dataflow and BSP
The next step beyond a simple parallel map, is a parallel map with a single global reduce stage running on one machine. This suits a number of classical machine learning workloads, and can handle learning problems up to 2TB in size.
BSP algorithms can be implemented by adding data shuffles across stages using high bandwidth remote storage. The authors use both PySpark and PyWren to run a word count program over a dataset of 83.68M product reviews split into 333 partitions. PyWren is 17% slower (about 14s), but this doesn’t count the 5-10 minutes needed to start the Spark cluster. The shuffle intensive Daytona sort benchmark is more challenging for PyWren.
Finally using low-latency, high throughput key-value stores like Redis, RAMCloud, we can also implement parameter server style applications in PyWren. For example, we can implement HOGWILD! stochastic gradient descent by having each function compute the gradients based on the latest version of the shared model.
Prototype limitations
- You need to fit within the existing Lambda resource limits. Under current Lambda constraints this is enough to fill up the function’s 1.5GB of memory in around 40 seconds. Assuming the same time to write results back out you have up to 80 seconds of I/O time, and therefore about 220 seconds of compute.
- The pricing works out at about 2x that of on-demand instances, if you assume 100% utilisation of those instances.
- There is no opportunity to influence the scheduling
- Debugging is harder, relying on AWS CloudWatch logs.
- Large shuffle intensive workloads are not easily supported
- It takes about 20-30 seconds to launch a function in the absence of caching – setting up the Python runtime, downloading the code to run from S3 etc..
- Applications requiring access to specialized hardware (GPU, FPGA) aren’t supported in Lambda at the moment.
Despite all of these, the list of applications that have been successfully deployed using PyWren (as we looked at earlier) is still quite impressive.

Speed of deployment and ease of use coupled with good enough runtime performance is SQL :P