To type or not to type: quantifying detectable bugs in JavaScript Gao et al., ICSE 2017
This is a terrific piece of work with immediate practical applications for many project teams. Is it worth the extra effort to add static type annotations to a JavaScript project? Should I use Facebook’s Flow or Microsoft’s TypeScript if so? Will they really catch bugs that would otherwise have made it to master?
TL;DR: both Flow and TypeScript are pretty good, and conservatively either of them can prevent about 15% of the bugs that end up in committed code.
“That’s shocking. If you could make a change to the way we do development that would reduce the number of bugs being checked in by 10% or more overnight, that’s a no-brainer. Unless it doubles development time or something, we’d do it.” – engineering manager at Microsoft.
(It’s amusing to me that this quote comes from a manager at the company where they actually develop TypeScript! You’d think if anyone would know about the benefits…. Big companies eh).
Let’s dig in.
The flame wars
Static vs dynamic typing is always one of those topics that attracts passionately held positions. In the static typing camp we have the benefits of catching bugs earlier in the development cycle, eliminating altogether some classes of bugs in deployed systems, improved things like code-assist and other tool support, and enabling compiler optimisations. In the dynamic typing camp we have cleaner looking code, and greater flexibility and code malleability.
JavaScript is dynamically typed.
Three companies have viewed static typing as important enough to invest in static type systems for JavaScript: first Google released Closure, then Microsoft published TypeScript, and most recently Facebook announced Flow.
Shedding some light through empirical data
Inspired by previous studies in other areas, the authors study historical bugs in real world JavaScript projects in GitHub.
The fact that long-running JavaScript projects have extensive version histories, coupled with the existing of static type systems that support gradual typing and can be applied to JavaScript programs with few modifications, enables us to under-approximately quantify the beneficial impact of static type systems on code quality.
In other words, if the developers had been taking advantage of TypeScript or Flow at the time, would the bug have made it past the type checker? If not, it’s reasonable to assume it would never have been committed into the repository in the first place.
Here’s an example of a trivial bug that type annotations can detect:

Through this process, we end up with an under-estimation of the total benefits that might be available through static type checking.
In the Venn diagram below, we see on the left the universe of bugs that can potentially be detected by a statically checked type system. Type checking may help catch some of these faster during development. On the right we see bugs that have made it into public repositories. Only a subset of these have clearly linked fixes / patches. This study looks at the intersection of type-system detectable bugs and those that have public fixes.

We consider public bugs because they are observable in software repository histories. Public bugs are more likely to be errors understanding the specification because they are usually tested and reviewed, and, in the case of field bugs, deployed. Thus, this experiment under-approximates static type systems’ positive impact on software quality, especially when one considers all their other potential benefits on documentation, program performance, code completion, and code navigation.
Finding bugs to study
The goal is to find a corpus of bugs to study that is representative of the overall class, and large enough to support statistical significance. Finding representative bugs is addressed by uniform sampling. The authors sample commits that are linked to a GitHub issue from a snapshot of all publicly available JavaScript projects on GitHub. Each is then manually assessed to determine whether or not it really is an attempt to fix a bug (as opposed to a feature enhancement, refactoring, etc.). For the commits that pass this filter, the parent provides the code containing the bug.
To report results that generalize to the population of public bugs, we used the standard sample size computation to determine the number of bugs needed to achieve a specified confidence interval. On 19/08/2015, there were 3,910,969 closed bug reports in JavaScript projects on GitHub. We use this number to approximate the population. We set the confidence level and confidence interval to be 95% and 5%, respectively. The result shows that a sample of 384 bugs is sufficient for the experiment, which we rounded to 400 for convenience.
At the end of the sampling process, the bug pool contained bugs from 398 different projects (two projects happened to have 2 bugs each in the corpus). Most of these bug fixing commits ended up being quite small: about 48% of them touched only 5 or fewer lines of code, with a median of 6.
Bug assessment process
To figure out how many of these bugs could have been detected by TypeScript and Flow, we need some rules for how far we’re prepared to go in adding type annotations, and long long we’re prepared to spend on it. A preliminary study on a smaller sample of 78 bugs showed that for almost 90% a conclusion could be reached within 10 minutes, so the maximum time an author was allowed to spend annotating a bug was set at 10 minutes.
Each bug is assessed both with TypeScript (2.0) and with Flow (0.30). To reduce learning effects (knowledge gained from annotating with one system speeding annotation with the other), the type system to try first is chosen at random. The process is then to read the bug report and the fix and spend up to the allotted ten minutes adding type annotations. Sometimes the tools can detect the bug without needing any annotations to be added at all. Other times the report will make it clear that the bug is not type related – for example a misunderstanding of the intended application functionality. In this case the bug is marked as type-system undetectable.
We are not experts in type systems nor any project in our corpus. To combat this, we have striven to be conservative: we annotate variables whose types are difficult to infer with any. Then we type check the resulting program. We ignore type errors that we consider unrelated to this goal. We repeat this process until we confirm that b is ts-detectable because ts throws an error within the patched region and the added annotations are consistent (Section II), or we deem b is not ts-detectable, or we exceed the time budget M.
Details of the approach used to gradually add type annotations are provided in section III.D.
Does typing help to detect public bugs?
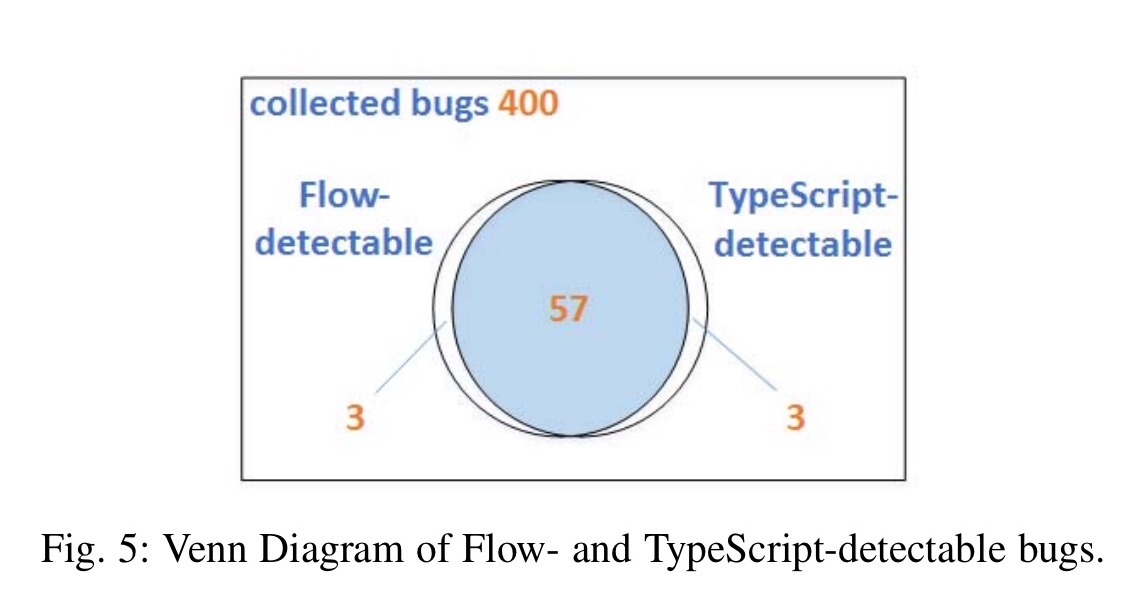
Of the 400 public bugs we assessed, Flow successfully detects 59 of them, and TypeScript 58. We, however, could not always decide whether a bug is ts-detectable within 10 minutes, leaving 18 unknown. The main obstacles we encountered during the assessment include complicated module dependencies, the lack of annotated interfaces for some modules, tangled fixes that prevented us from isolating the region of interest, and the general difficulty of program comprehension.
The 18 unknown bugs are then investigated to conclusion, at which point the score is 60 each for TypeScript and Flow.
Running the binomial test on the results shows that, at the confidence level of 95%, the true percentage of detectable bugs for Flow and TypeScript falls into [11.5%, 18.5%] with mean 15%.
Flow and TypeScript largely detect the same bugs:
Which is better: Flow or TypeScript?
The bugs that the two systems can detect largely overlap, with just 3 bugs that are only detected by TypeScript, and 3 that are only detectable by Flow.
All three Flow-detectable bugs that TypeScript fails to catch are related to concatenating possibly undefined or null values to a value of type string. Two of the three TypeScript-detectable bugs that Flow fails to detect are due to Flow’s incomplete support for using a string literal as in index. The remaining bug slips through the net due to Flow’s permissive handling of the window object.
Flow has builtin support for popular modules, like Node.js, so when a project used only those modules, Flow worked smoothly. Many projects, however, use unsupported modules. In these cases, we learned to greatly appreciate TypeScript community’s DefinitelyTyped project. Flow would benefit from being able to use DefinitelyTyped; TypeScript would benefit from automatically importing popular DefinitelyTyped definitions.
Yes, but what’s the cost of adding all those annotations?
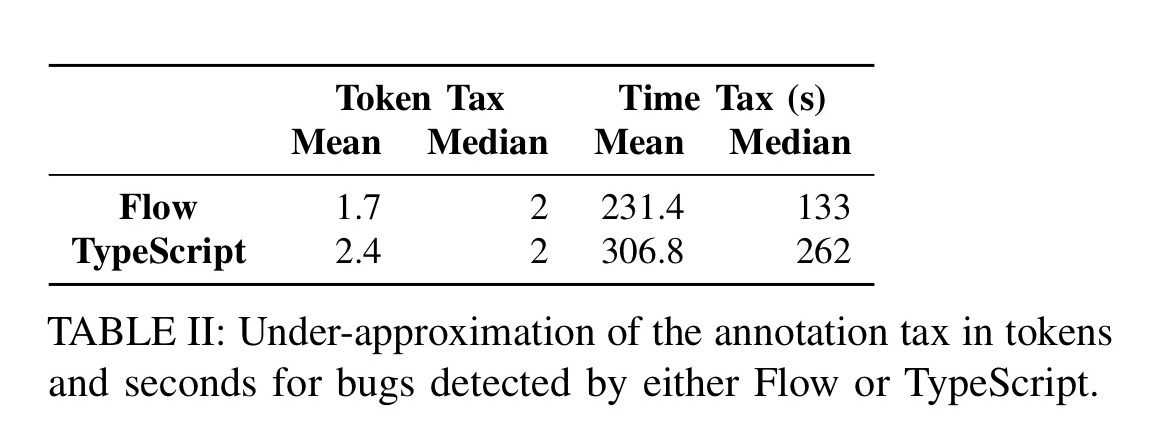
Another consideration, both when comparing TypeScript and Flow, and when deciding whether to use either, is the cost of adding the annotations in terms of time and ‘token pollution’ in the source code.
… on average Flow requires 1.7 tokens to detect a bug, and TypeScript 2.4. Two factors contribute to this discrepancy; first, Flow implements stronger type inference, mitigating its reliance on type annotations; second, Flow’s syntax for nullable types is more compact.
The authors also measured the time taken to add the required annotations, with Flow coming out on top:
Thanks to Flow’s type inference, in many cases, we do not need to read the bug report and the fix in order to devise and add a consistent type annotation, which leads to the noticeable difference in annotation time.
Over to you
Is a 15% reduction in bugs making it all the way through your development pipeline worth it to you? And if so, will you go with the Flow or settle for TypeScript? Flow’s lighter-weight approach may suit dynamic-typing advocates better, whereas TypeScript’s DefinitelyTyped library and approach may perhaps be more appealing to strong-typing advocates coming from other languages.
Whatever you decide, at least you now have some data points to help make a more informed decision.

«In the static typing camp we have the benefits of catching bugs earlier in the development cycle, eliminating altogether some classes of bugs in deployed systems, improved things like code-assist and other tool support, and enabling compiler optimisations. In the dynamic typing camp we have cleaner looking code, and greater flexibility and code malleability.»
Hi Adrian,
I think you’re missing some very important aspects offered by a “rich” typing discipline, that should also be considered when weighing the ins and outs of “static” typing vs “dynamic” typing (this distinction itself could be discussed BTW). By a rich typing discipline, I mean one relying on an expressive type system (featuring at least “sum” types, genericity, aka parametric polymorphism, and working extensively by inference, i.e. requiring no or almost no type annotation): in this situation, types are a *design tool*, they help you structure your program and thanks to inference, they don’t get in the way while giving strong support to refactoring (in the sense that the compiler tells you which parts of the code are impacted by an evolution). The main outcome is therefore not that types detect bug, which they can do for some kinds of bugs, but it is above all that they prevent them, in particular when your code evolves. Said otherwise, a “type error” could as well be called a “piece of code you forgot to adapt to (your modifications) of the data structures”.
Best.
Absolutely, I also had the feeling that refactoring is overlooked in this blog. The actual measurement that should be done is: “take a very complex program that you did not write yourself and see how long it would take you to do a serious refactor/adaption of the code both in static and dynamic typing”. Now that would be interesting….
My very limited experience with this (in Haskell) was that type inference got in the way, and made it extremely difficult to fix certain refactorings, because when I modified the type of something deep in a stack of calls, type inference made there be errors all over the place.
My attempt at fixing this by actually adding type declarations to make the errors localized failed due to the type inferred by ghci not working in ghc (for some reason I can’t remember).
As somebody that is used to dynamic languages (Python, Ruby, Perl) and annotation typed languages (C, C++, Java), the types got in the way more than they did in any of those. They were less lexically noisy than in annotation typed languages (and somewhat more flexible), but they still got in the way in a way that made me end up giving up fixing my program. (This was a toy program I was writing for fun, and the debug cycle just ended up more painful than I was motivated to spend time on.)
Well compared to C/C++/Java, this doesn’t seem to make sense: rich-type inference (à la Hindley-Milner, e.g. Haskell or OCaml) encompasses these languages so anything you did in those languages, you can do in these (modulo the design philosophy: functional or OO; and modulo the development environment, such as ghci vs ghc here).
Now I’m interested in the writing of large programs that don’t fail for unexpected reasons (e.g. because I was lazy enough not to type the few letters on my keyboard that mandate the program to cast an int to a string or because I’m fool enough to use nullable types). In this setting, I think “dynamic” and weakly-typed languages lose their appeal. They can’t offer the assurance of not failing for unexpected rasons (as they catch foreseeable errors at runtime only) and they don’t support refactoring as well as with right typing.
The real added value is in my view that “dynamic” languages support dynamic extensibility (extending a program at runtime, for instance with dynamic binding in OO languages) but most of the time, you could avoid this. Of course, it’s not *that* important for non-critical applications, but as programs grow their user base and as they are reused (which is the case of some JS code), they may impact or be part of critical applications, and then the apparent freedom they offered at first becomes a problem.
Exactly, and that’s why I think using JSDoc with plain JavaScript is actually better than using TypeScript. It’s help you and your IDE. Ow, and in the first place, your functional code should be unit tested, catching all these ‘type’ bugs…
I don’t think that clojure fits against typescript and flow: it isn’t a JavaScript language and wasn’t a Google product. Perhaps you meant dart?
I did a double take when I first read that too! The authors are talking about closure (with an ‘s’), not Clojure: https://en.m.wikipedia.org/wiki/Google_Closure_Tools
I think generic programming (C++ Template, …) is the best of the both world.
Very nice article, thanks for sharing! Great to have the discussion supported by some data, but I feel the article barely scratches the surface. Further questions that come to my mind:
1. What are the benefits of type annotation to a language like Python? I tend to think that Python has a “saner” type system, e.g., you cannot add a number and a string. Things tend to crash loudly in case of type errors.
2. The dynamic typing camp usually argues that unit testing is the “real” way to test code and that once good unit testing is in place, compile-time type checking adds little value. What does the data say?
It would be great to see more papers on this topic but covering a larger spectrum of choices (flamewars?): non-template static (à la C) vs. template static (à la C++) vs. strict dynamic (à la Python) vs. loose dynamic (à la JavaScript).
I share both parts:
1. Being a long time strict type follower in C++, I fell in love with Python last few years and also think that most of type related issues will explode loud, making fixing of it a walk in the park. The only downside being that you need to hit this issue at runtime, but that what your unit tests are for, so 2.
Unfortunately, I haven’t seen any empirical evidences to support either of the statements.
Similar to DefinitelyTyped, Flow has flow-typed: https://github.com/flowtype/flow-typed. It doesn’t have as many libs as DefinitelyTyped, but still has many major ones, and has been growing. It makes an attempt to provide multi-version support as well.
We’ve used several type defs from flow-typed. It’s convenient, but can be a mixed-bag at times. It can be extremely difficult to write *useful* type defs for JS libs that were created without types in mind. So, some of the flow-typed defs are either overly strict or overly permissive. YMMV, but still a great resource. The flow-typed maintainers have been very responsive in accepting PRs we’ve submitted as well.
You have a good point about Flow-Typed being available as well. I wrote about it when I was evaluating TypeScript vs Flow (http://patrickdesjardins.com/blog/typescript-vs-flow-part-1-of-3-who-they-are) The problem is that the ratio is about 1:10. Also, many very used library, like JQuery-UI, are not supported by Flow. I found that you fall short very fast with Flow. I wish both of them could be “transferable” or had used the same definition file.
Lol, the debate seems not to have progressed far in the 20 years when I last took part. But by now I think I can guess why.
I ran this page through an XHTML verifier, which found 58 errors. (“How is that relevant?”)
But he never said XHTML verifier…?
Hi TL, about your question concerning the relevance of finding bugs in XHTML vs JS, I think you can use one of the examples of the article about the sum of an integer and string. It might not be as relevant for HTML since the browser compensates and still, in that case, render something that might (or could) not be broken. However, 3+0 being “30” will be problematic in every case in JavaScript — why running a chance to let that slip in?
There is significant progress around typing in the last 20 years. Lots of big projects rely on Java and more and more big JavaScript project migrate to typed language as well. It’s always a matter of scale (term of lines of code and people involved). It’s getting easier and less cumbersome and with Typescript and Flow you have a structural or nominal way to do it. Always good to have many options :)
Hi Patrick, I nearly mentioned the problem of, shall we call it, “nuisance overloading” where the language tries to guess what you wanted and gets it wrong. But then I suppose type inference that can resolve overloading would end up in the same place unless you first coerce things appropriately. As I see it, that issue is really about a questionable choice in language semantics. (Javascript have a few of those, hasn’t it?)
Concerning practical experiences, it would be interesting to hear about experiences with Haskell and relatives in the financial industry. They seem to have gotten a foothold there.
Great article. You may want to look into flow-typed. It is flows analog to DefinitelyTyped.
https://github.com/flowtype/flow-typed
Do the guys really compare apples to apples?
The measurement on effort and costs is made to type annotate those defects that are type annotation (TA) detectable … but if I would know where do I need to TA, then I would not write the bug on a first place.
Comparesement need to be made to TA effort introduction to all 400 bugs under investigation.
Flow: 133s * 400 = 887 minutes
TS: 262s * 400 = 1747 minutes
In reality those figures will be higher, as the mean value estimation is done on simple 59/58 bugs and likely the remaining ones will require more effort, but let’s keep it like it is.
Now the effort to fix bugs without TA:
Flow: 59 * 10m = 590 minutes
TS: 58 * 10m = 580 minutes
In reality this effort will be lower, as authors do not share the mean value for a fix and use 10 minutes as top cut, but let’s keep it as it is.
So, the overall overhead effort to find type related bugs using the
Flow: 887 / 590 = 1.5 === 50% more effort is required
TS: 1747 / 580 = 3.0 === 200% more effort is required
Based only on the figures above, my conclusion will be that TA are not beneficial for overall development effort.
I think you’ve missed a couple of very important things:
– Without TA you would release those bugs into production, at best that’s harmful to developer pride but at worst your application could break in such a way that it harms your customers and costs your company significant revenue.
– Without TA you also have to find the bug in your code once you’ve identified that it exists, this might be obvious or it might not so you could spend a long time looking for it.
It’s naive to only consider the time taken to implement TA without actually considering the consequence of the bugs rather than just the time taken to fix them after they are released into production.
And, I think you are treating all production bugs as equally bad when they are not.
There will always be bugs, so the issue then is this: is it worth the time to eliminate bugs that really don’t have an obvious and/or severe effect, given that the those bugs will be caught in your CI environment?
From the data above, it seems not. And, the fact that the world has survived for 20 years without strongly typed JavaScript is a strong indicator that everything is just fine without going to all the extra effort to squash bugs that don’t matter.
TS has a significant advantage over Flow because of its larger community.
There’s more tooling suppport, more articles/blogs/etc for help, DefinitelyTyped has more coverage, more libraries include type definitions for TS.
>> The authors also measured the time taken to add the required annotations <<
Can adding annotations be automated?
See https://github.com/Microsoft/dts-gen
Without type information the intention of the developer that wrote the code is less clear so the code is less maintenable.
In the example about addNumbers the developer must find out if the method was created to add number as integers or numbers as strings, or even worse if the method was intended to do what it does and it was used wrong.
If you create your vegetable garden, you may ask yourself why must I plant my vegetables in separated beds (= to type) instead of mixing them all (= not to type).
Maybe you don’t like making separate beds in your vegetable garden – waste of time.
In the case of a small vegetable garden, do whatever you like.
But, if your gardening area is big enough to create raised beds and paths, you should be crazy if you plant herbs and potatoes in the same bed.
Creating beds and paths means extra work, but the real gardener knows why he does it.
I don’t think the conclusion fits the test.
“both Flow and TypeScript are pretty good, and conservatively either of them can prevent about 15% of the bugs that end up in committed code.”
Isn’t what was tested. It reduces them by 15% in an environment that is not already using unit tests.
It should be repeated in 3 groups: 1 uses TDD (or BDD), 1 uses ad-hoc unit tests and the last one without any unit tests.
Unit tests also benefit by the type system. Whole classes of things no longer need to be tested for, so tests are written faster. In my opinion you can view the compile-time type check as a set of automatically generated unit tests. In my experience refactoring is also eased by the type system, another TDD time win, although that is highly language dependent. So, you’d have to measure the matrix on both code quality and productivity: TDD, TDD with types, ad-hoc tests, ad-hoc tests with types, and no tests or types and no tests but types.
Programming types are completely useless bullshit. There is nothing wrong with JavaScript until paid corporate zombies say so. Corporate specs are designed to lock in naive developers, which consume and resell bullshit artificial concepts that bring no real value. Instead of solve explicit long term problems that real developers have, they create more problems in order to maintain market dominance. Why not just insert useful methods to ES5? NO, let’s just break 20 years of powerful language cognition with a new shitty sugar syntax that are not backward compatible. Why not make JS better, NO, let’s just make it bigger and sell it as “modern”.
So, we’re just ignoring the findings of the paper then?
This article completely misses the point. Static types help to write correct code from the start, especially with modern IDEs and smart autocompletion. With Python I always had to look at the source definition to find what the @*(#*@ this reference is.
So a Python programmer has to expend a lot of time simply to write commitable code and it STILL has type bugs afterwards.
Well, you’ll be excited to learn that modern python has optional static types! (https://docs.python.org/3/library/typing.html) They work quite well and have extensive IDE support. Also, modern Python IDEs already did a good job of autocomplete, type inference, refactoring, etc. Not perfect, but quite excellent.
Indeed.
And this says nothing of the pain and wasted development time that would be avoided if a basic sanity check (i.e., compilation) were done in the IDE, before even attempting to run code that can’t possibly work. I can’t count the number of hours lost hunting for some tiny typo in some JavaScript code that, if Java, would have been clearly marked as an erroneous line of code and corrected in 2 seconds.
JavaScript is a dead end design, no matter what you try to tack on afterwards.
For anyone who says “but we’re stuck with it” — no we’re not. The day WebAsm gets GC/DOM interop is the day JavaScript begins a slow but sure decline to obsolescence.
So, I guess you’re advocating not writing any front end code until the day 5 years from now when a substantial portion of clients can support web assembly along with the necessary tooling support?
I didn’t see any mention of linting in your analysis or other comments.
I can’t help wonder what the linting rules (if any) were for those projects with bugs at that time and/or if a set of linting rules on a project would have a similar/worse/better impact on reducing bugs.
In my experience, adding linting rules to an existing project will sometimes immediately highlight questionable code and find bugs.
I would love to see a linter thrown into the mix as an alternative tool in a future analysis like this.
So a Python coder has to expend a portion of clip simply to compose commitable code and it STILL has type bugs afterwards. My very limited experience with this (in Haskell) was that type inference got in the room, and made it extremely difficult to fix sure refactorings, because when I modified the type of something rich in a pile of calls, type inference made there be errors all over the spot.
JavaScript is growing explosively and is now used in large mature projects even outside the web domain. JavaScript is also a dynamically typed language for which static type systems, notably Facebook’s Flow and Microsoft’s TypeScript, have been written.