On the design of distributed programming models Meiklejohn, arXiv 2017.
Today’s choice is a lovely thought piece by Christopher Meiklejohn, making the case for distributed programming models. We’ve witnessed a progression in data structures from sequential (non-thread safe) to concurrent, to distributed (think CRDTs). Will the same thing happen with our programming models? And if so, what might they look like?
Distributed programming, while superficially believed to be an extension of concurrent programming, has its own fundamental challenges that must be overcome.
From sequential, to concurrent, to distributed
The core of most programming models in widespread use today is a von Neumann style model where computation revolves around mutable storage locations (variables) and programs progress in a set order with a single thread of execution.
Concurrent programming extends this to accommodate multiple sequential threads of execution. The threads may be executing in parallel on multiple processors, or a single processor may be alternating control.
Concurrent programming is difficult.
A lot of the difficulty comes in reasoning about whether or not the program is correct under all possible schedules…
Given multiple threads of execution, and a nondeterministic scheduler, there exists an exponential number of possible schedules, or executions, the program may take, where programmers desire that each of these executions result in the same value, regardless of a schedule.
The desirable property of confluence holds that the evaluation order of a program does not impact its outcome.
Many modern languages embed concurrency primitives directly into the language itself, it’s not something left solely to the libraries.
Isn’t distributed programming just concurrent programming where some of the threads happen to execute on different machines? Tempting, but no. Distribution is a true extension of concurrency in the same way that concurrency extends sequential.
On the surface, it appears that distribution is just an extension of concurrent programming: we have taken applications that relied on multiple threads of execution to work in concert to achieve a goal and only relocated the thread of execution to gain more performance and more computational resources. However, this point of view is fatally flawed.
Whereas the challenges of concurrent programming revolve around non-determinism, distributed brings with it a fundamentally different set of challenges (which brings to mind Peter Deutsch’s fallacies of distributed computing).
Distribution is fundamentally different from concurrent programming: machines that communicate on a network may be, at times, unreachable, completely failed, unable to answer a request, or, in the worst case, permanently destroyed. Therefore, it should follow that our existing tools are insufficient to solve the problems of distributed programming. We refer to these classes of failures in distributed programming as “partial failure”…
Distribution challenges
The core problem in distributed systems is the problem of agreement (aka consensus). It shows up in two forms:
- Leader election: the process of selecting an active leader amongst a group of nodes, and
- Failure detection: the processing of detecting that a node has failed and can no longer at as a leader.
Two impossibility results demonstrate why these problems are hard and set the boundaries for what is possible: the CAP theorem and the FLP result.
FLP tells us that in a truly asynchronous system, agreement is impossible in the presence of even a single failed process. We can’t distinguish between a very delayed response and a failure.
FLP is solved in practice via randomized timeouts that introduce non-determinism into the leader election process to prevent inifinite elections.
The CAP theorem says that when some of the processes in a system cannot communicate with each other (are partitioned), we have to sacrifice availability if we want to maintain linearizability (consistency).
Both CAP and FLP incentivize developers to avoid using replicated, shared state, if that state needs to be synchronized to ensure consistent access to it. Applications that rely on shared state are bound to have reduced availability, because they either need to wait for timeouts related to failure detection or for the cost of coordinating changes across multiple replicas of shared state.
What might distributed programming models look like?
With distributed programming becoming the new normal, “it is paramount that we have tools for building correct distributed systems.” Just as concurrency primitives made their way into the programming models themselves, will distribution primitives do the same?
… if an application must operate offline, a language should have primitives for managing consistency and conflict resolution; similarly, if a language is to adhere to a strict latency bound for each distributed operation, the language should have primitives for expressing these bounds.
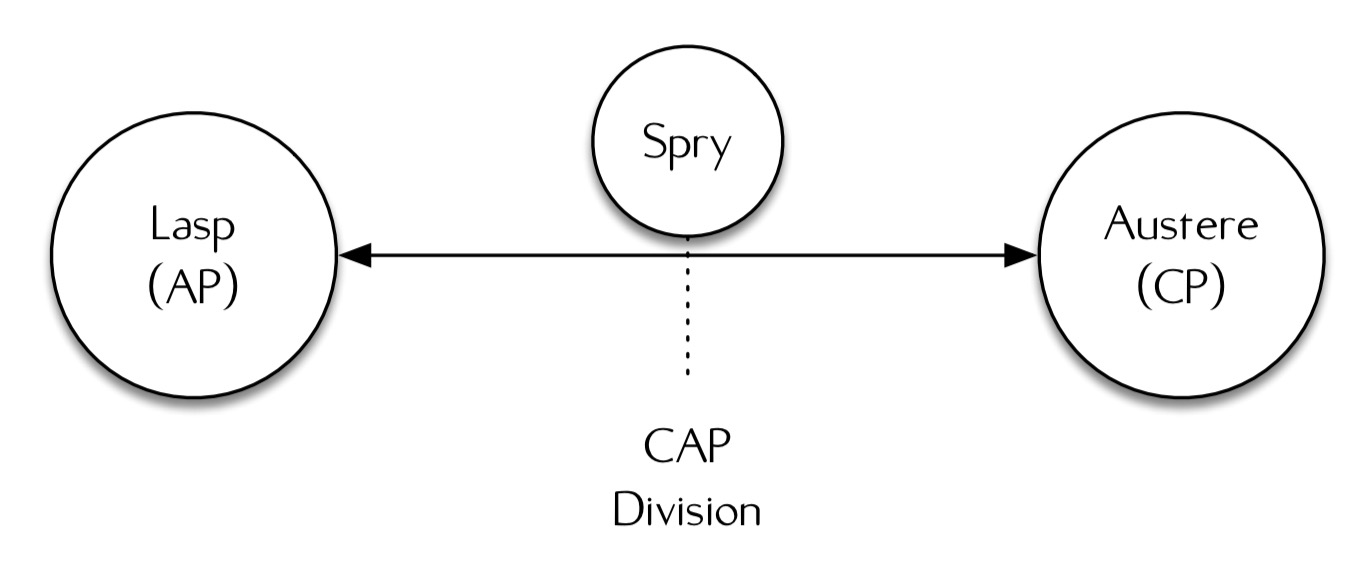
Any such distributed programming model must sit within the bounds specified by the CAP theorem. So at one end of the spectrum we have AP models, and at the other end we have CP models.
Lasp is an example of an AP model that sacrifices consistency for availability. In Lasp, all data structures are CRDTs, and therefore all operations must commute and all data structures must be expressible as bounded join-semilattices. This places restrictions on the kinds of data structures Lasp can support.
Austere (I couldn’t find a reference, sorry) is an example of a CP model that sacrifices availability for consistency. It uses two-phase locking before every operation, and two-phase commit to commit all changes. If a replica can’t be contacted, the system will fail to make progress.
Despite these differences, both of these models involve a datastore that tracks local replicas of shared state, and both are small extensions to the λ-calculus providing named registers pointing to locations in the datastore.
The “next 700” distributed programming models will sit between the bounds presented by Austere and Lasp: extreme availability where consistency is sacrificed vs. extreme consistency where availability is sacrificed.
(“next 700” is a lovely nod to Peter Landin’s classic paper ‘The next 700 programming languages‘)
What does it mean in practice to sit between these two extremes?
More practically, we believe that the most useful languages in this space will allow the developer to specifically trade-off between availability and consistency at the application level. This is because the unreliability of the network, dynamicity of real networks, and production workloads require applications to remain flexible.
Another alternative would be multiple languages, each making a different trade-off. This is closer to what happened with NoSQL datastores, but the industry has much less appetite for large numbers of programming languages than it does for large numbers of datastores. The main argument I see in favour of languages that choose a fixed point in the design space is that it should be easier to reason about the semantics of the resulting programs. Evidence shows that programmers find it very hard to reason correctly about availability and consistency under a single model, let alone when the system can be using multiple models at the same time. That said, on balance I agree with Meiklejohn’s conclusion that being able to make trade-offs within a single language is probably the best option. The convincing argument for me is that different parts of the same system clearly do have differing consistency requirements.
These trade-offs should be specified declaratively, close to the application code. Application developers should not have to reason about transaction isolation levels or consistency models when writing application code.
I’m not convinced developers can get away from reasoning about isolation and consistency even when those concerns are expressed declaratively (see e.g. ACIDRain for a recent counterpoint). But perhaps the point here is that developers shouldn’t have to write their own custom logic to do so.
Spry
Spry is an example of a design point in the space between CP and AP. (Though there doesn’t seem to be a whole lot in that GitHub repo…).
Spry is a programming model for building applications that want to tradeoff availability and consistency at varying points in application code to support application requirements.
The example given is of a CDN system where CA tradeoffs are made in both directions:
- content older than a given threshold will never be returned (consistency over availability)
- cached content will be returned if we can’t get the latest within a certain period of time (availability – and latency – over consistency)
Which puts me in mind of the PACELC formulation (in the case of a Partition, we can trade between Availability and Consistency, Else we can trade between Latency and Consistency).
In Spry, developers can add bounded staleness and freshness requirements via annotations. (We don’t get any source examples sadly, and the repo content is a little thin on the ground).

2 thoughts on “On the design of distributed programming models”
Comments are closed.