Writing parsers like it is 2017 Chifflier & Couprie, SPW’17
With thanks to Glyn Normington for pointing this paper out to me.
Earlier this year we looked at ‘System programming in Rust: beyond safety‘ which made the case for switching from C to Rust as the default language of choice for system-level programming. Today’s paper is in the same vein, but focuses on pragmatic incremental updates to existing C-based systems by looking at their use of parsing code. Why parsers? Because they are often manipulating untrusted data that can be controlled by a hacker…
Unfortunately, data parsing is often done in a very unsafe way, especially for network protocols and file formats… Today, many applications embed a lot of parsers that could be targeted: web browsers like Firefox or Chrome, media players (VLC), document viewers, etc..
There are many examples of parser related bugs and vulnerabilities (see e.g. Cloudbleed for a recent one), and they keep on coming.
After years of code auditing, publishing and teaching good practice and still finding the same problems, we must admit that current methods do not work.
If current methods aren’t working, what are we to do? Chifflier & Couprie have a two part solution for us:
- Change the programming language
- Use parser combinators as the sweet spot between hand-rolled parsers and the rigid output of parser generators
The goal is to take an existing C (or C++) program and replace its existing parser(s) with one(s) offering better security, without disturbing the rest of the application. And if you haven’t guessed yet, that better parser implementation is going to be written in Rust.
Finding a better programming language
The programming language you choose to use has a big impact on the security of the resulting software. “Mind your language(s): A discussion about languages and security” makes a strong case for this. That paper also opens with a quote that I can’t resist repeating here:
An unreliable programming language generating unreliable programs constitutes a far greater risk to our environment and to our society than unsafe cars, toxic pesticides, or accidents at nuclear power stations. Be vigilant to reduce that risk, not to increase it. – C.A.R Hoare
By using a safe programming language, responsibility for whole classes of security related issues moves from the developer to the compiler. In their search for a better language, the authors looked for:
- Strong typing, “because type safety is an essential quality for security.”
- The absence of garbage collection (due to concerns over performance and multi-threading)
- A memory model close to the low-level hardware, and ideally supporting zero-copy compatibility with C.
In the end, they settled on Rust for the following reasons:
- A managed memory model that prevents use-after-free and double-free flaws
- No garbage collection
- Thread-safety guaranteed by the compiler
- Strong typing
- Runtime efficiency
- Zero-copy data buffers
- Easy integration with C with minimal data conversions
- Clear marking of safe/unsafe parts of the code
- A good/large community: “it’s important to use a good language, but it is better to have active and helpful users.”
Embracing parser combinators
Changing the language is important, but it is not enough. Another component is required to help fix logical bugs, and make sure parsers are both easier to write and do not contain errors.
Many low-level parsers ‘in the wild’ are written by hand, often because they need to deal with binary formats, or in a quest for better performance. Often these end up with hard to maintain code. At the other end of the spectrum there are parser generators, which tend to produce parsers of good quality but still present challenges in writing the grammar and integrating context specific libraries.
In between these two choices lie parser combinators.
Parser combinators propose a middle ground between hand-written parsers and generated parsers. They are made of small functions that handle basic parts of a format, like recognizing a word in ASCII characters or a null byte. Those functions are then composed in more useful building blocks like the pair combinator that applies two parsers in sequence, or the choice combinator that tries different parsers until one of them succeeds.
The functions are completely deterministic and hold no mutable state. The deterministic behaviour of parser combinators simplifies writing the state machine that manages data accumulation.
The authors’ parser combinator library of choice for Rust is nom, written by the second author (see ‘Nom, a byte oriented, streaming, zero copy, parser combinators library in Rust,’ and https://github.com/Geal/nom).
The underlying idea of nom stems from Rust’s memory handling. Since the compiler always knows which part of the code owns which part of the memory, and Rust has a slice type (a wrapper over a pointer and a size) that represents data borrowed from somewhere else, it is possible to write a parser that will never copy input data. It will instead only return generated values or slices of its input data. This approach has the potential to make efficient parsers.
With stateless parsers that don’t need ownership of the input data, it becomes relatively easy to write the parser in nom, add unit tests in Rust, and then call into Rust from C.
Incremental adoption in existing systems
… it seems more reasonable and pragmatic to try to change only a small part of the initial software, without affecting the rest. For example, replacing a parser (ideally, only one function in the initial code) by its safe version, recoded in the new language.
For incremental adoption, integration into the host system needs to be as painless as possible. Fortunately, parser modules offer the triple benefits of a small interface to the rest of the system, normally not directly modifying the application’s state, and being high value targets for security upgrades. The recommended approach is as follows:
- Create and test the parser in a separate Rust project (so that it can be reused across multiple applications)
- In the Rust interface code, transform unsafe C types (e.g., pointers to void) to richer Rust types, and the revers when returning values to C.
- Ensure the Rust interface appears as a set of deterministic reentrant functions from the C side. If it is necessary to keep state around, it can be wrapped in a Box passed to the C code as an opaque pointer, with accessor functions provided.
- The simplest option is to make sure that the Rust part never owns the data to parse, by only working on and returning slices. In this way, the only important values moving across the interface are pointers and lengths.
That just leaves the small matter of the build system:
Integrating the Rust code in the build system is a large part of the work needed. While it is not especially hard, it requires fixing a lot of details, like passing the platform triplets between compilers, setting up the right paths for intermediary or final objects, ordering the build of components and linking them.
Case studies
The paper contains two case studies: replacing the FLV parser in the VLC media player, and writing a safe TLS parser for the Suricata IDS. This led to the Rusticata project (https://github.com/rusticata/rusticata), containing implementations of fast and secure parsers in Rust, together with a simple abstraction layer to use them in Suricata. Rustica is compiled as a shared library exposing C functions.
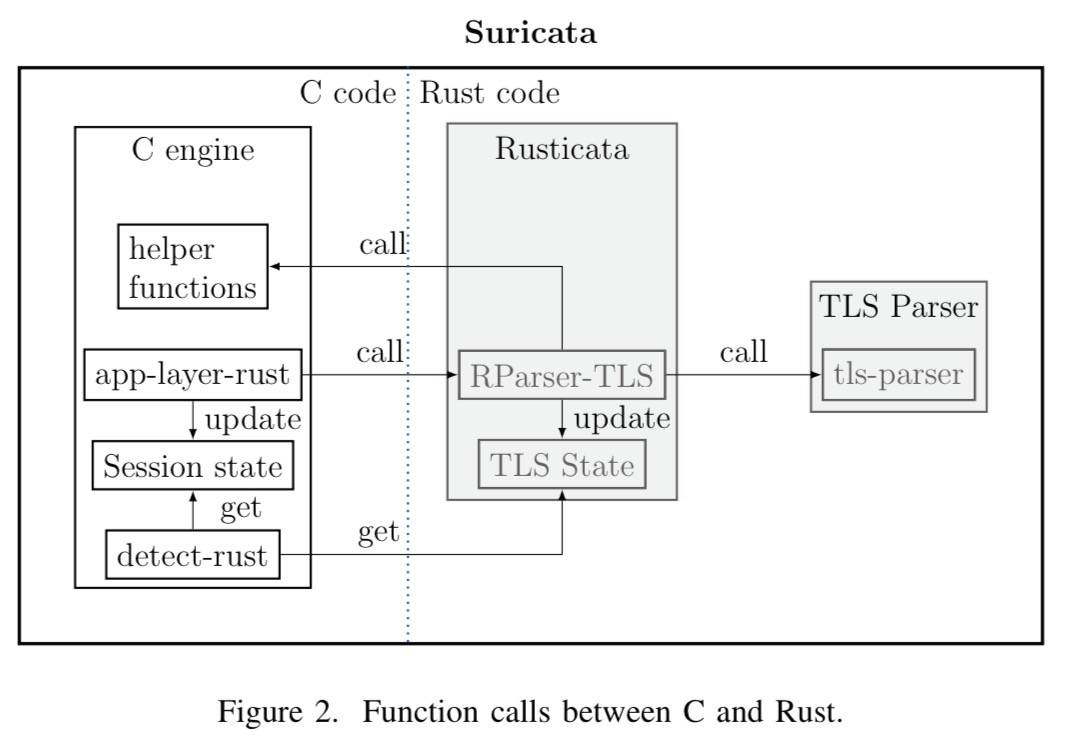
To avoid duplicating support functions such as logging, alerting, and so on, pointers to the requisite C functions are wrapped and passed to the Rust code.
For an interesting comparison to the Rustica TLS parser effort, see ‘Not quite so broken TLS‘ that we looked at last on The Morning Paper last year.
The appendix contains an interesting analysis of the code generated by Rust compiler. Most things look good, but of note is the fact that the Rust code has no protection activated for the stack:
Admittedly, the generated code is supposed not to contain any overflow thanks to the compiler checks, but it is a bit sad that a well-established function integrated to LLVM is not used, even if the integration causes some difficulties (tracked in Rust issue #15179). That also means that a Rust library loaded from a C executable will provide ROP gadgets. Hopefully, the library supports ASLR, but this is not satisfactory, and could be improved in the future

Here is a great talk by one of the authors (Couprie) about writing parsers with nom.
You might want to use Nim
Hi, on this topic of parsing and security, you may want to have a look at langsec.org. I’m sure you will find many papers of interest there ;)
Thanks and keep up the good work!
The first trendy nonsense paper review of this season.
The Wikipedia article, https://en.wikipedia.org/wiki/Parser_combinator, cites a paper from 1989 as the first to use parser combinators, but I remember seeing it in the mid 1980s; will have to track down an earlier paper.
Combinators used to be used to promote functional languages, Miranda was trendy, then Haskell and so on.
Rust is the current academic friendly language to suggest as a replacement for C. Putting a date in the title means this paper will date even faster than most of its ilk.
For something that really is new and interesting in the world of parsing, check out Kegler’s work on Marpa: https://jeffreykegler.github.io/Ocean-of-Awareness-blog/
Can Haskell, Miranda and so on be used to implement GC-free, zero-copy parsers?
Miranda, Haskell et al were where all the interesting garbage collection work was done back in the 80s.
I think the paper authors are fanboys of Rust and cherry picked some ‘advantages’ to make the choice appear rational.
(I can’t seem to reply to your comment directly, so I’ll reply from here.)
You didn’t answer my previous question, so I’ll assume that Haskell and Miranda are not suitable for writing GC-free, zero-copy parsers that integrate with C with low overhead.
This means these languages were never credible candidates for “incremental updates to existing C-based systems”, which is what this paper is about.
So I’m curious why you even brought them up?
The two part system you mentioned I feel would help, but we need to be more mindful of these issues with the increase of data, and data processing. Security is going to become a bigger issue as Programming Language software development as well as Software Engineering development are going to keep growing and developing as technology always will, I love the visuals you used in this blog to drive home the point your trying to convey. I love this blog btw.
“Strong typing, “because type safety is an essential quality for security.””
Is there any evidence to support this position, or is it just a way to inject a type-system preference into the article?
I’m typing this comment into a form that uses JavaScript. Is it inherently insecure, because it lacks this “essential quality”?
No problem, JS is strongly typed as well, just not statically typed. (that would be type script).
Wikipedia seems to disagree with you.
https://en.wikipedia.org/wiki/Strong_and_weak_typing
Parsing by example
https://parsimony-ide.github.io/