Hardware is the new software Baumann, HotOS’17
This is a very readable short paper that sheds an interesting light on what’s been happening with the Intel x86 instruction set architecture (ISA) of late. We’re seeing a sharp rise in the number and complexity of extensions, with some interesting implications for systems researchers (and for Intel!). We’re also seeing an increasing use of microcode blurring the role of the ISA as the boundary between hardware and software.
We argue that these extensions are now approaching software-like levels of complexity, yet carry all the attendant drawbacks of a hardware implementation and the slow deployment cycle that implies. We suspect that the current path may be unsustainable, and posit an alternative future with the ultimate goal of decoupling new ISA features from the underlying hardware.
(Note, the author is from Microsoft Research, not from Intel).
The old days: steady and contained growth
The 386 reference manual listed 96 instructions. New instructions were steadily added over time in areas such as floating point support, vector extensions, crypto accelerators, 64-bit, and so on. Crucially though:
… past system designers could, for the most part, ignore such changes… With the notable exception of 64-bit mode and virtualisation extensions, OS developers on x86 were occasionally given tweaks to improve performance or correct glaring shortcomings, but otherwise ignored. Even 64-bit mode didn’t substantially increase architectural complexity…
Why buy a new CPU?
With the slowing of Moore’s law, Intel’s traditional two year tick-tock development model is also slowing down. This presents an obvious question:
… absent improvements in microarchitecture they [CPUs] won’t be substantially faster, nor substantially more power efficient, and they will have about the same number of cores at the same price point as prior CPUs. Why would anyone buy a new CPU?
If you put yourselves in Intel’s shoes for a moment, you can see why this might be troubling. What else can you do to make buying a new CPU attractive?
One reason to which Intel appears to be turning is features: if the new CPU implements an important ISA extension – say, one required by software because it is essential to security – consumers will have a strong reason to upgrade.
In other words, upping the pace of extension release is likely to be a deliberate Intel strategy to keep us buying. As a result…
… the last two years have seen a dramatic and rapid increase in ISA complexity (e.g., seen in the size of the architecture manual in the figure below), with more extensions on the way.
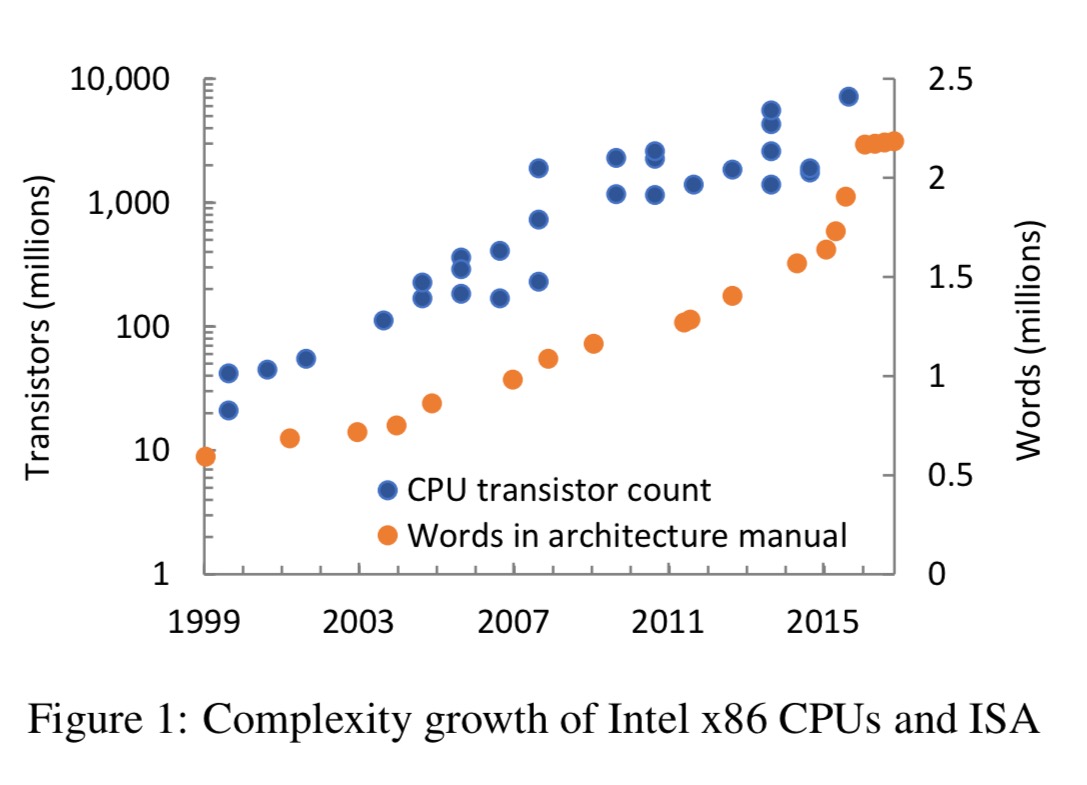
The chart above still follows Moore’s law (note the log-scale on the left-hand axis) with the recently announced slow down in release cadence yet to appear. Using words in the manual as a proxy for complexity, we can also see a big jump in the 2015-16 period due to the extensions introduced with Skylake.
(Out of interest, I calculate that with 2 million words, and an average reading rate of 200wpm, it would take about a month of full-time reading – at 40 hr weeks – just to do one pass of the manual!).
The following table summarises recent ISA extensions together with the number of new instructions they introduce.
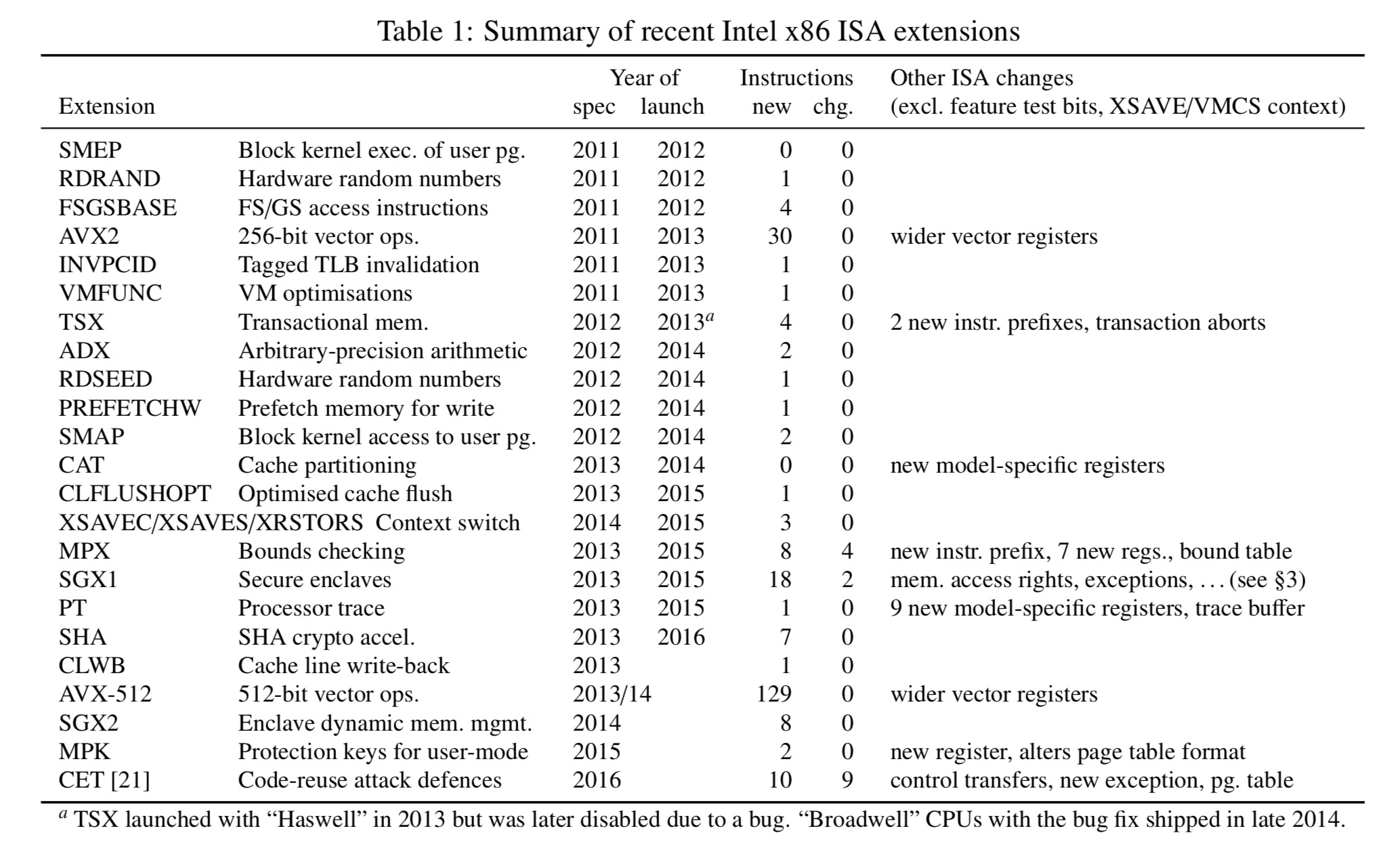
The complexity increase is not just from the number of new instructions though, but more critically, from the interactions with existing instructions:
These [more recent] extensions introduce new system-level functionality, often change the semantics of existing instructions, and exhibit complex interactions with other extensions and prior architectural features.
SGX and CET examples
Baumann cites the SGX and CET extensions as prime examples. We’ve looked at SGX several times previously on The Morning Paper of course.
The compelling combination of features, along with strong physical security (memory encryption), has made SGX attractive to researchers and practitioners alike… However, SGX introduces substantial complexity: 26 instructions described by nearly 200 pages of English/pseudocode specification.
Of those 200 pages, nearly 20 are devoted to documenting SGX interactions with prior architectural features. And it turns out one of those interactions threatens to undermine the very security which SGX seeks to provide. This was new to me, despite having read a number of papers on systems exploiting SGX. If you’re interested, it’s worth chasing the reference here to dip into “Preventing page faults from telling your secrets” (CCS’16). The attack relies on a side-channel under the OS’s control (and hence assumed under the control of an attacker in the SGX threat model): page faults. By inducing a page fault on nearly every instruction, enough information is leaked that 27% on average and up to 100% of the secret bits from encryption keys in OpenSSL and libgcrypt can be recovered (demonstrated attacks).
Perhaps ironically, the best of the known mitigations exploits a seemingly-unintended interaction with the transactional-memory extension: transactions abort rather than page fault, so the OS cannot observe transactional enclave memory accesses.
The CET (control-flow enforcement technology) extension sounds pretty cool to be honest. It defends against code-reuse attacks such as ROP by maintaining a shadow stack and indirect branch tracking. The shadow stack contains just return addresses and is not accessible to normal code. On a return, the addresses from the regular and shadow stacks are popped and compared – if they don’t match, there’s trouble afoot!
CET promises to add strong defenses to unsafe C/C++ code, at the cost of substantial architectural complexity… the main complexity arises from feature interaction. Control transfer in x86 is already very complex, including many forms of call and return, such as near and far calls to a different segment or privilege level. In total, nine instructions (some with many variants, such as JMP) are modified by CET.
Can we sustain this pace?
We’re seeing a high rate of change accompanied by rapid growth in complexity of systems-level features with complex interactions. Yet ,”a faithful implementation of x86 semantics is essential for x86-compatible processors, virtual machines, emulators, JIT compilers, dynamic translators, disassemblers, debuggers, profilers, and so on.”
… we have to question whether the core x86 promise of indefinite backwards compatibility across many implementations is sustainable.
When improvements come via new instructions, exploiting gains takes longer
The first SGX spec. was published in 2013, the first CPUs implementing it didn’t ship until 2015, and server-class CPUs with SGX support were still to appear as of early 2017. Add on the time for sufficient deployment, and we’re talking about a decade from initial spec. to widespread availability. At some point in this cycle, software developers will be able to start developing for SGX with a reasonable assumption of its availability.
This represents a difficult tradeoff for software developers; prior ISA extensions have also taken a long time to deploy, but they have generally only served to accelerate existing functionality; with a feature like SGX, the developer is faced with a stark choice: wait indefinitely for security, or deploy now without it.
Add this software lag, and we could be looking at well in excess of a decade for general exploitation of new features.
The boundary between hardware and software is blurring
A careful reading of Intel patents suggests that SGX instructions are implemented entirely in microcode. If new ISA features are new microcode, that opens up the possibility of supporting them on existing CPUs. For example, perhaps (poorer performing?) versions of (many?) new instructions could be implemented this way, making a faster path for adoption of new features. The licensing and revenue model for this is an open question (as is the interaction with the desire to sell new CPUs).
… now more than ever before it’s time to rethink the notion of an instruction set. It’s no longer the boundary between hardware and software, but rather just another translation layer in the stack.

The tile of this paper is quite big. The trend which he mentioned in the paper is 100% fact. But the example which added into the CPU based on one factor ” No software can be trusted” is quite good argue point.
Add more and more function will make the CPU complex and maintian the General-Propose CPU as before, this sound a dead end. How to fix this, not mentioned yet.
And the number of “only 1-or-2 instructions” enhancement-sets is getting out of hand – with some variant CPUs (ultramobile, mobile, desktop, server) of the same age not providing the same set of extensions, it is becoming a combinatorial nightmare.
Reblogged this on Art of Geekiness.
in modern amd64 platforms, how many transistors do you think are wasted implementing “backwards compatible” modes other than 64-bit “long mode”?