Neurosurgeon: collaborative intelligence between the cloud and mobile edge Kang et al., ASPLOS’17
For a whole class of new intelligent personal assistant applications that process images, videos, speech, and text using deep neural networks, the common wisdom is that you really need to run the processing in the cloud to take advantage of powerful clusters of GPUs. Intelligent personal assistants on mobile devices such Siri, Google Now, and Cortana all fall into this category, and all perform their computations in the cloud. There’s no way, so the thinking goes, that you could do this kind of computation on the device with reasonable latency and energy consumption.
… the status quo approach used by web service providers for intelligent applications has been to host all the computation on high-end cloud servers.
What Neurosurgeon shows us is that the common wisdom is wrong! In a superbly written paper the authors demonstrate that by intelligent splitting of the computation between the cloud and the mobile device, we can reach solutions that are better for everyone:
- End-to-end latency reduced by up to 3.1x on average (and up to 40.7x!). That’s going to feel a whole lot more responsive!
- Mobile energy consumption reduced by 59.5% on average (and up to 94.7%). Hold on a minute – you’re telling me I can do more computation on the mobile device, and significantly reduce battery drain at the same time? Yep!
- Datacenter throughput at the cloud provider increased by 1.5x on average, and up to 6.7x. (That’s a huge win).
Let’s first build the case for why this kind of split computation might be interesting, and then take a look at how Neurosurgeon automatically finds the best split point for different kinds of DNN workloads. We’ll finish up with some of the evaluation results to back up those outlandish claims!
(Note that the major platforms have all been making moves to enable more deep learning to happen on mobile devices in general. Apple added deep learning developer tools to iOS 10, Facebook announced Caffe2Go last year for running deep learning models on mobile devices, and Google just announced TensorFlow Lite for Android.)
Moving data doesn’t come for free
The latest SoC mobile chips are pretty impressive. This study uses the Jetson TK1 mobile platform from NVIDIA which has a quad-core ARM processor and a Kepler mobile GPU. The combined power of hundreds of thousands of those is pretty impressive!
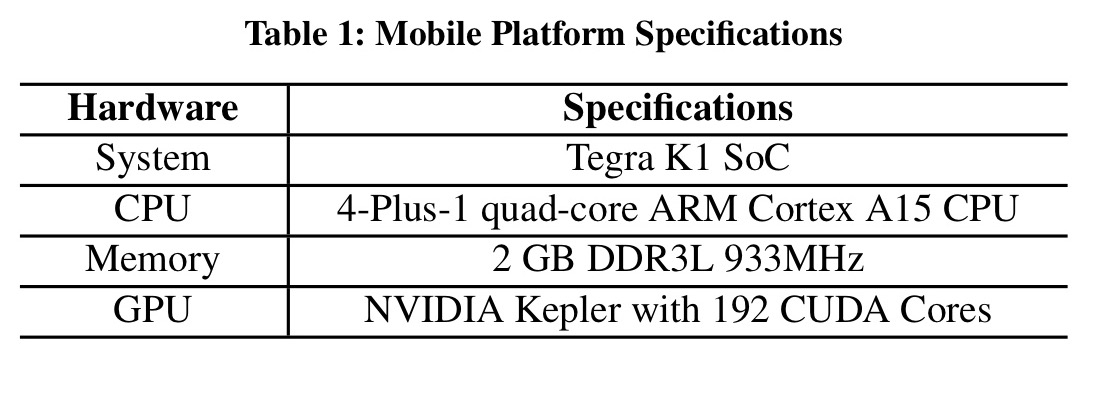
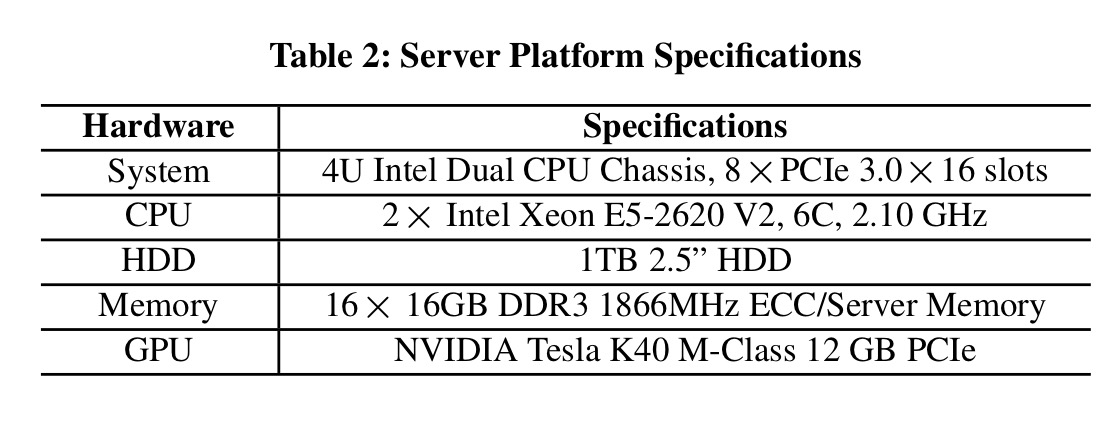
If you look at the server platform specification used for the study though, it’s clear that any single mobile device is still massively outgunned:
Let’s look at what happens for an image classification task using AlexNet (a deep CNN), given a 152KB input image. To begin with, we’ll just compare the current (all processing on the cloud approach) with an alternative that does all processing on the mobile device.
If we just examine latency, we can see that if a mobile GPU is available, doing all processing there gives the user the best experience. When processing on the cloud, only 6% of the time is spent computing, and about 94% of the time transferring data!
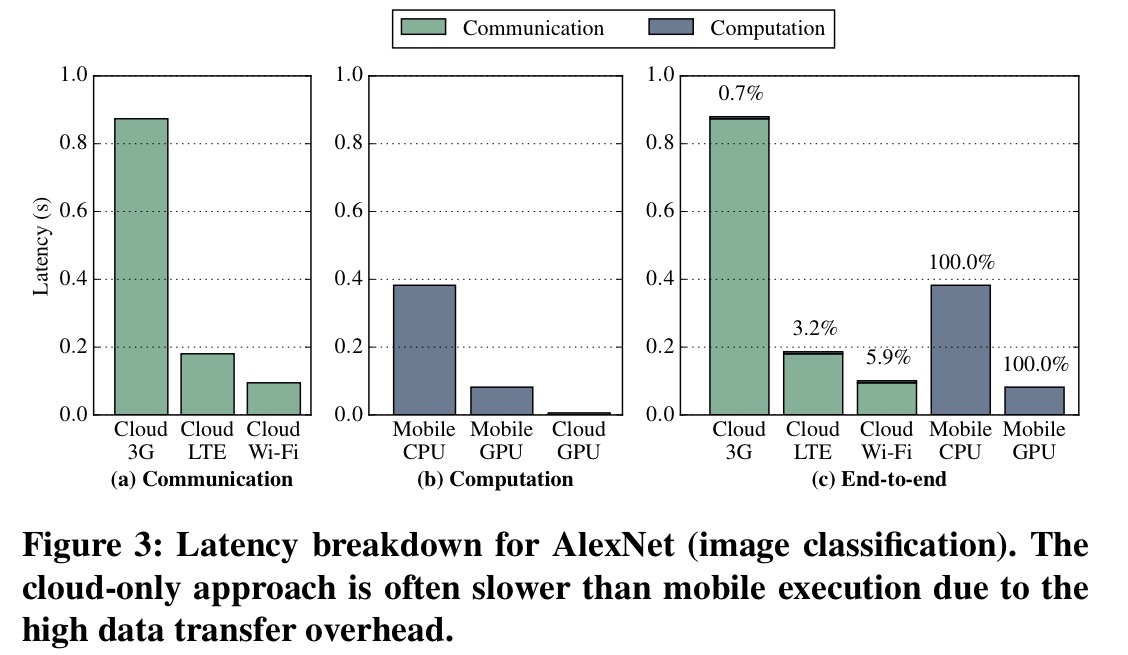
The mobile GPU achieves a lower end-to-end latency than the status quo approach using LTE and 3G, while the status quo approach using LTE and Wi-Fi performs better than mobile CPU execution.
Here’s the same analysis done for energy consumption:
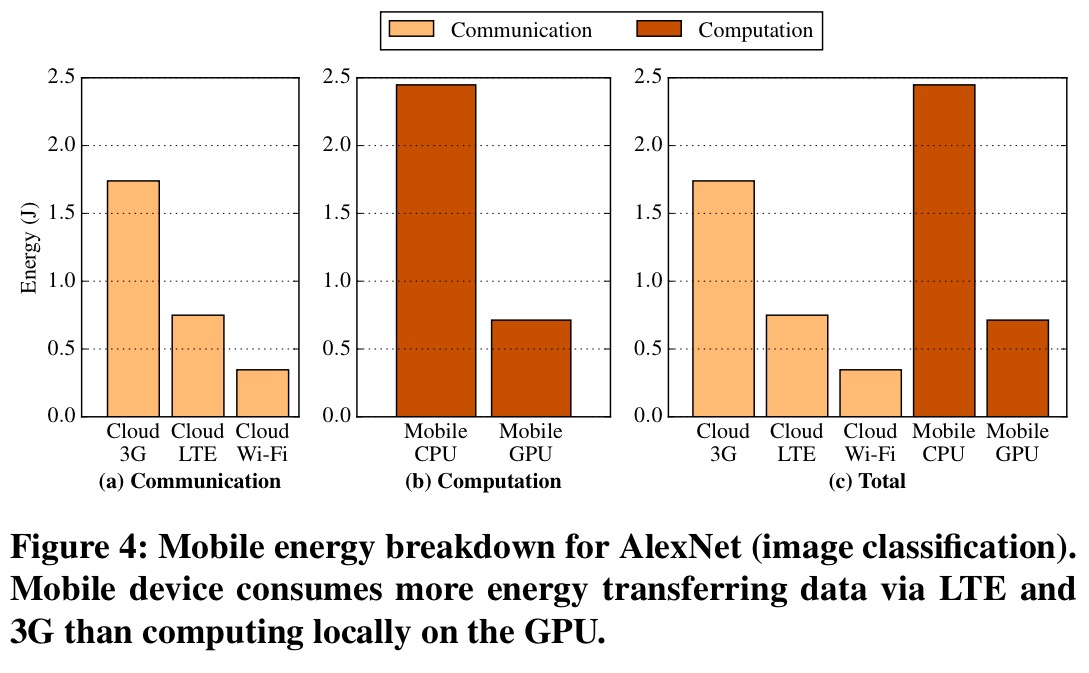
If you have Wi-Fi, the least battery drain is achieved by sending the data to the cloud for processing. And if you have a GPU, processing on the mobile device can use less energy than that required to transfer data over 3G or LTE networks.
Cloud processing has a significant computational advantage over mobile processing, but it does not always translate to end-to-end latency/energy advantage due to the dominating data transfer overhead.
The data transfer & compute requirements vary by network layer
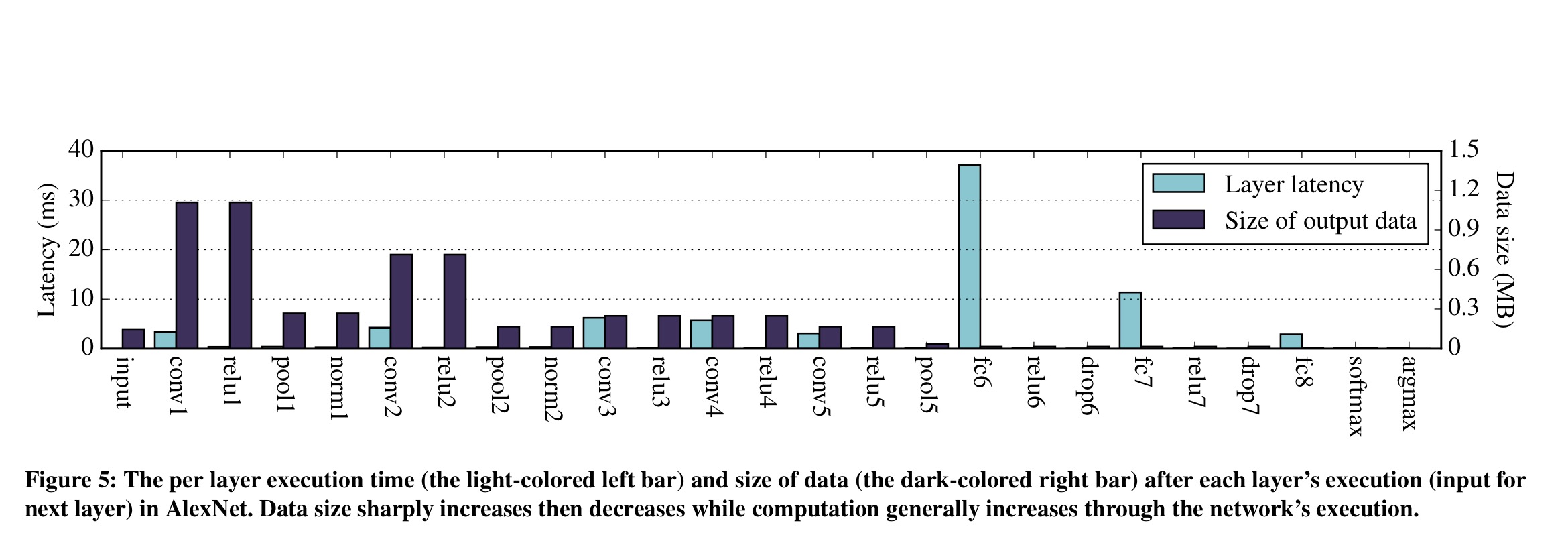
Is there an optimum point in-between the two extremes of everything done in the cloud vs everything done on the device? It seems there is a trade-off between the amount of data that we need to transfer, and the amount of computation that we need to do. A natural way of splitting DNN computations is at layer boundaries. If we take AlexNet and plot the size of the output data at each layer, and the amount of computation that takes place at each layer (shown here as latency when computing on the mobile device), you get a chart that looks like this:
Here’s a sketch to make what’s going on a little clearer to see:
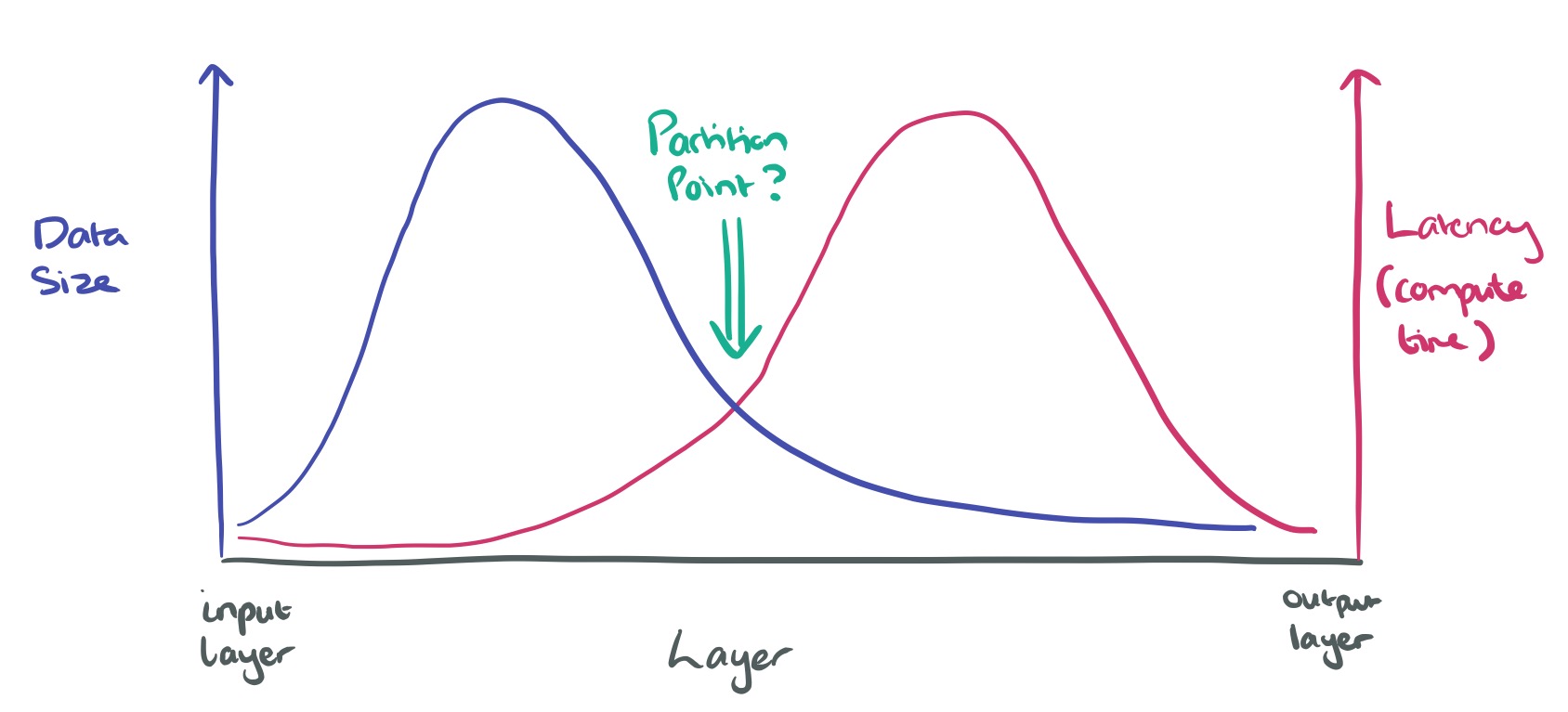
In the early convolutional layers, the volume of data output by each layer rises sharply, before falling away towards the middle and end. The amount of computation however increases towards the latter half of the network stack – fully-connected layers are up to one magnitude slower than the convolution layers.
In the light of this, let’s look at what happens if you consider all possible layer splits with AlexNet (i.e., process the first n layers on the mobile device, and then transfer the output of the nth layer to the cloud where processing continues, before finally transferring the output of the last layer back to the mobile device).
Here you can see the results for both latency and energy consumption, with the best split on each count marked with star.
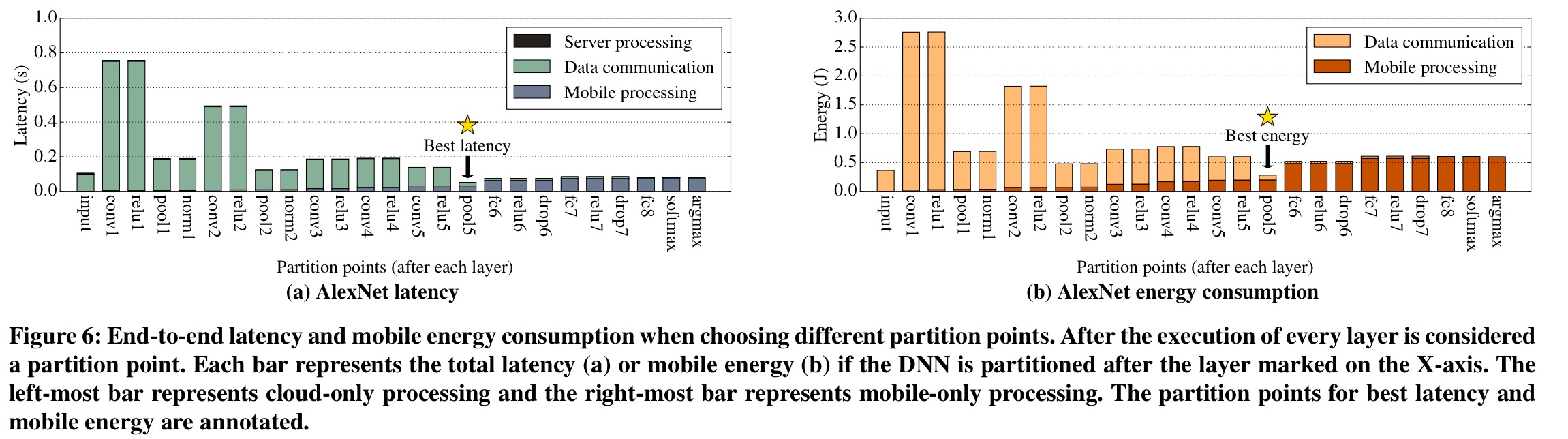
Partitioning at layer granularity can provide significant latency and energy efficiency improvements. For AlexNet using the GPU and Wi-Fi, the best partition points are between the intermediate layers of the DNN.
This is all just for AlexNet of course. Do the results generalise to other network architectures typically used in image, video, speech, and text processing with DNNs? The authors performed the same analysis with a variety of networks as shown in the following table.
For the computer vision networks with convolutional layers, we see partitioning opportunities in the middle of the DNN. The ASR, POS, NER, and CHK networks (ASR and NLP applications) only have fully-connected layers and activation layers though. For these networks there only exist opportunities for partitioning the computation at network extremities.
The best way to partition a DNN depends on its topology and constituent layers. Computer vision DNNs sometimes have better partition points in the middle of the DNN, while it is more beneficial to partition at the beginning or the end for ASR and NLP DNNs. The strong variations in the best partition point suggest there is a need for a system to partition DNN computation between the mobile and cloud based on the neural network architecture.
How Neurosurgeon works
The best partition point for a DNN architecture varies according to a number of factors – some static, such as the model architecture, and some dynamic such as available network connectivity, datacenter load, and maybe available mobile battery life too.
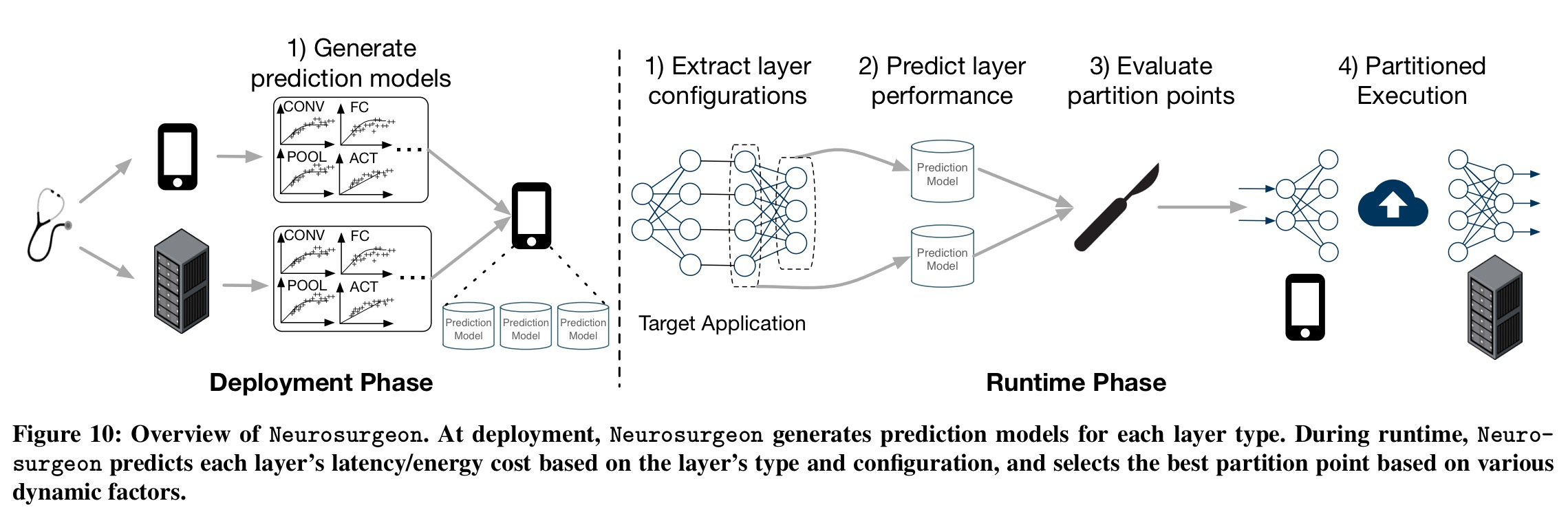
Due to these dynamic factors, there is a need for an automatic system to intelligently select the best point to partition the DNN to optimize for end-to-end latency or mobile device energy consumption. To address this need, we present the design of Neurosurgeon, an intelligent DNN partitioning engine.
Neurosurgeon consists of a one-time deployment phase in performance prediction models (latency and energy) are built for the mobile device(s) and the server for a variety of layer types and configurations (convolution, local and pooling, fully-connected, activation, and normalization). This phase is independent of any particular DNN application. Using the prediction models, Neurosurgeon can estimate the latency and energy consumption of a DNNs layers without needing to execute the DNN.
The set of prediction models are stored on the mobile device and later used to predict the latency and energy costs of each layer.
At runtime, Neurosurgeon dynamically determines the best partition point. First it analyses and extracts the DNN architecture’s layer types and configurations, then it uses the prediction model to estimate the latency and energy consumption for each layer on the mobile device and on the cloud. Using these predictions, combined with the current network conditions and datacenter load level, Neurosurgeon selects the best partition point. It can be tuned to optimised either for best end-to-end latency or best mobile energy consumption (or of course, any point in-between).
Neurosurgeon in practice
Neurosurgeon is evaluated using the 8 DNNs we saw earlier in table 3, across Wi-Fi, LTE, and 3G mobile wireless connections with both CPU-only and GPU mobile platforms. Across all of the benchmarks and configurations, Neurosurgeon finds a partitioning that gives latency speedups within 98.5% of the optimal speedup available.
Across all benchmarks and configurations, Neurosurgeon achieves a latency speed-up of 3.1x on average, and up to 40.7x over the status quo (all cloud) approach.
When it comes to energy consumption, Neurosurgeon achieves on average a 59.5% reduction in mobile energy, and up to 94.7% reduction over the status quo.
The following example shows how Neurosurgeon adapts its partitioning decisions over time as network conditions change, giving lower and much more predictable latency than the status quo approach:
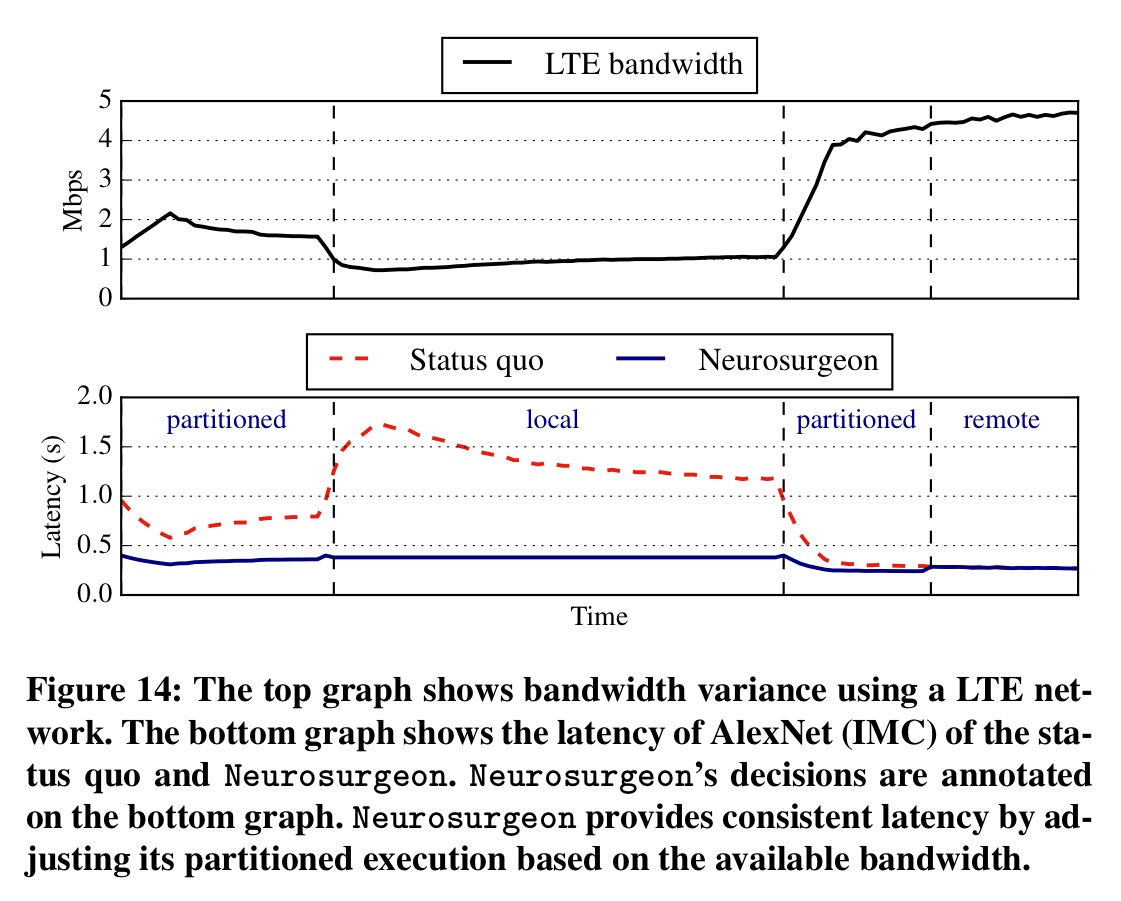
Neurosurgeon also periodically pings the cloud servers to provide an estimate of load in the datacenter. When the datacenter load is high it can backoff the load it sends there by opting to do more processing on the mobile device. In this way, “Neurosurgeon consistently delivers the best latency regardless of the variation in server load.”
We use BigHouse to compare the achieved datacenter throughput between the status quo and Neurosurgeon. The incoming DNN queries are composed evenly of the 8 DNNs in the benchmark suite. We use the measured mean service time of DNN queries combined with the Google web search query distribution for the query inter-arrival rate.
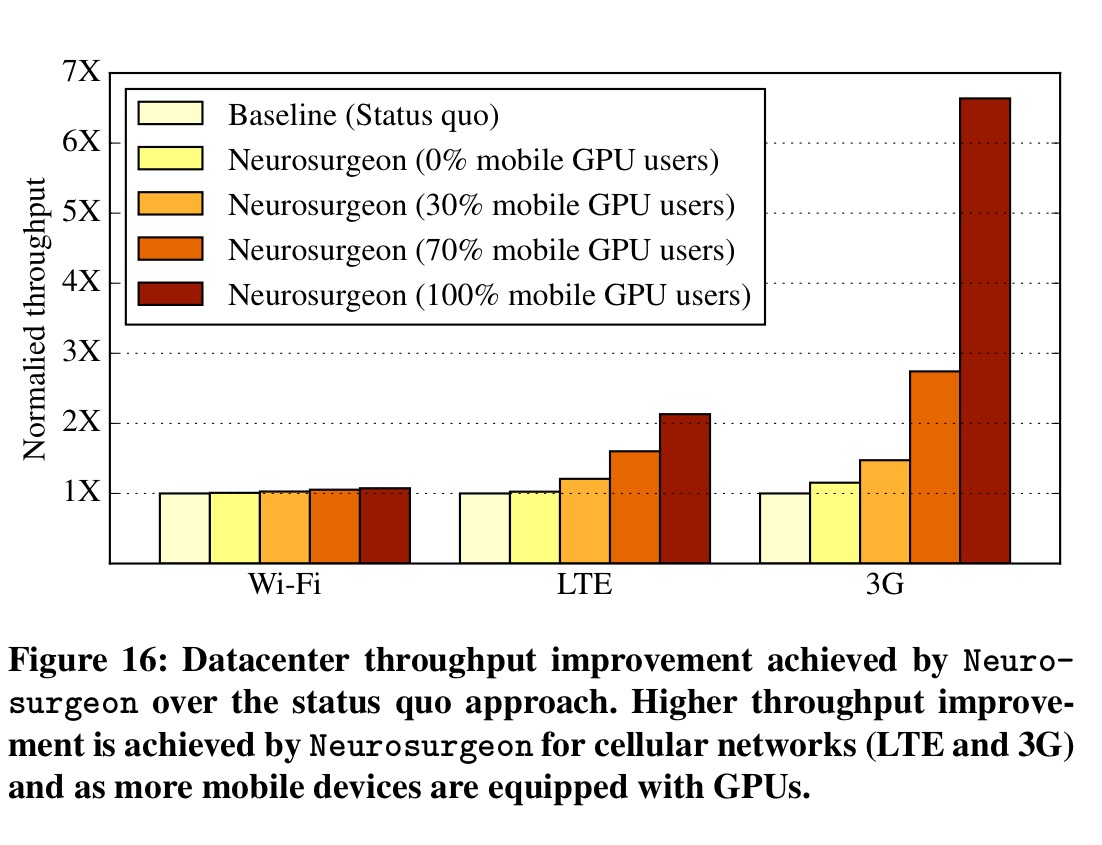
With mobile clients connected over Wi-Fi, Neurosurgeon achieves a 1.04x throughput improvement, but as connection quality deteriorates and Neurosurgeon elects to do more processing on-device, datacenter throughput increases by 1.43x for LTE, and 2.36x for 3G.

You will find that -> https://www.usenix.org/node/196268 – has the same theme. Thought you should know.