Deconstructing Xen Shi et al., NDSS 2017
Unfortunately, one of the most widely-used hypervisors, Xen, is highly susceptible to attack because it employs a monolithic design (a single point of failure) and comprises a complex set of growing functionality including VM management, scheduling, instruction emulation, IPC (event channels), and memory management.
As of v4.0, Xen runs to 270Kloc, a plenty large enough codebase to harbour multiple security vulnerabilities. Needless to say, once the hypervisor is compromised you’re in trouble. At best you’re exposed to a denial of service attack (shutdown or crash the machine and all the VMs running on it), at worst every single VM is compromised. SGX, which we looked at again earlier this week can protect applications running in enclaves from a malicious hypervisor, but does nothing to protect against attacks against the hypervisor (and let’s face it, you’re not using SGX with your production workloads right now anyway).
The authors studied all 191 vulnerabilities published on the Xen Security Advisories list, of which 144 are directly related to the core hypervisor. From the 144:
- 62% lead to host denial-of-service attacks
- 15% lead to privilege escalation,
- 14% lead to information leaks, and
- 13% use the hypervisor to attack guest VMs.
As our security analysis demonstrates, the Xen core is fundamentally at risk. However, it is unclear how to effectively mitigate these threats.
Nexen is a deconstruction of Xen into multiple internal domains following the principle of least privilege. Enforcing separation between these domains is not easy since the hypervisor operates at the highest hardware privilege level – Nexen uses a same-privilege memory isolation technique we’ll look at shortly. A prototype implementation of Nexen mitigates 107 out of the 144 core hypervisor vulnerabilities, with very small performance overhead (on the order of 1.2%).
The overall design of Nexen looks like this:
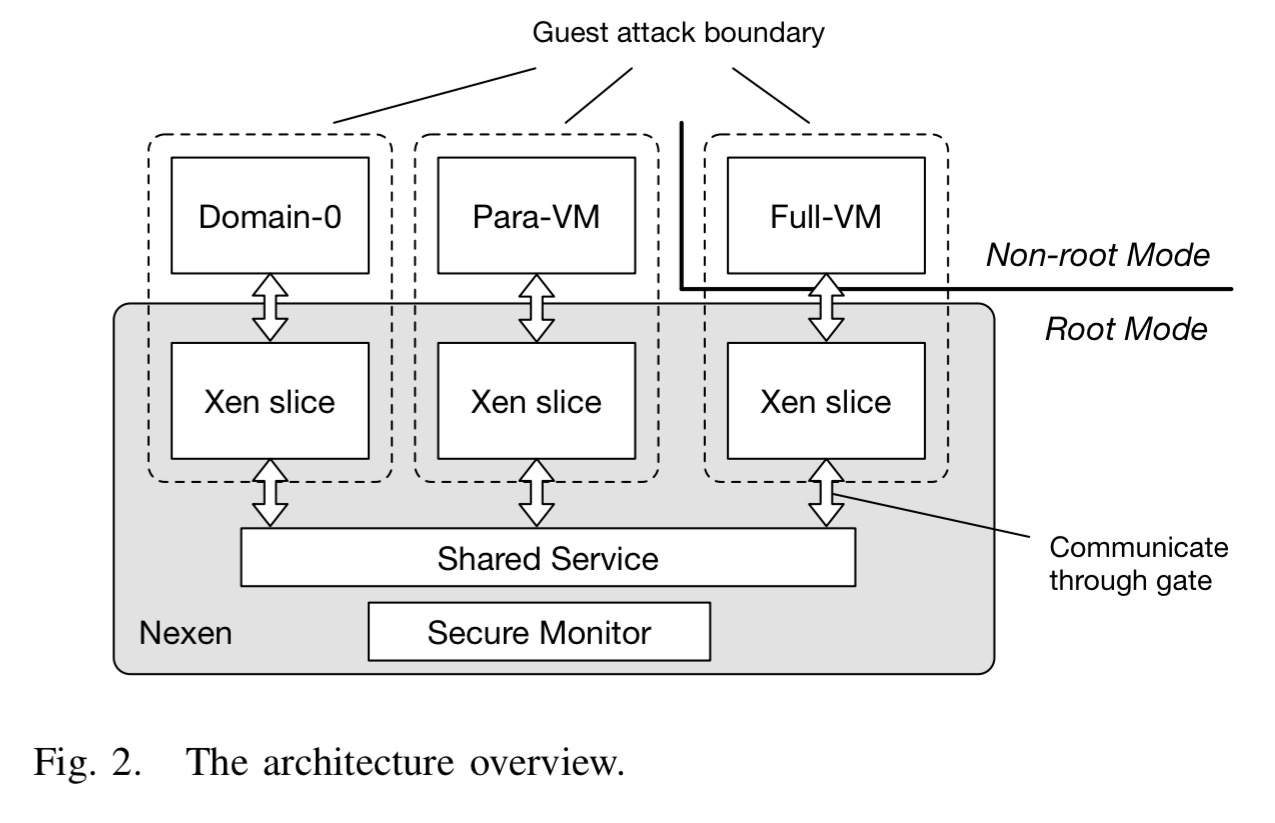
There is a minimal fully privileged security monitor running directly on the hardware. Each virtual machine is supported by its own fully sandboxed Xen slice. Xen slices share code but each has its own data. Errors inside one slice are not considered dangerous to the whole system or other VMs.
Unfortunately, a simple decomposition of all functionality into slices is untenable because subsets of functionality interact across slice boundaries. High frequency privilege boundary crossing cause high performance degradation. So we create a single, slightly more privileged shared service domain—but still not as privileged as the security monitor. Deciding what to place in per-VM slices and the shared services domain is non-trivial and one of the key contributions of this work.
Xen Slices communicate with the shared service domain module through carefully controlled gates. All of this looks nice as a modular design of course, but the key point is that the domain boundaries need to be enforced – every single domain runs at the highest privilege of the system, ring 0 of the root mode. The monitor needs to be tamper-proof, but without creating high overheads or forcing large changes to the Xen code base. The secret to pulling this off is nested MMU virtualization.
Nested MMU virtualization works by monitoring all modifications of virtual-to-physical translations (mappings) and explicitly removing MMU modifying instructions from the unprivileged component – a technique called code deprivileging.
All mapping pages are marked as read-only. Thus any unexpected modifications to page table can be detected by traps. The removal of any modifying instructions from higher level domains is enforced through a binary scan (checking for both aligned and unaligned privileged instructions – attention to detail!). Restricting control of the core MMU to just the monitor greatly reduces the TCB (Trusted Compute Base) for memory management.
On top of the monitor, components such as the scheduler and domain management are placed in the shared service, while functions relating only to one VM live in the Xen slices. The security monitor does not have its own address space, it is shared by all internal domains – but as we’ve seen no-one is able to tamper with its data. The shared service and every Xen slice have their own address spaces. The overall memory access permissions are arranged like this:
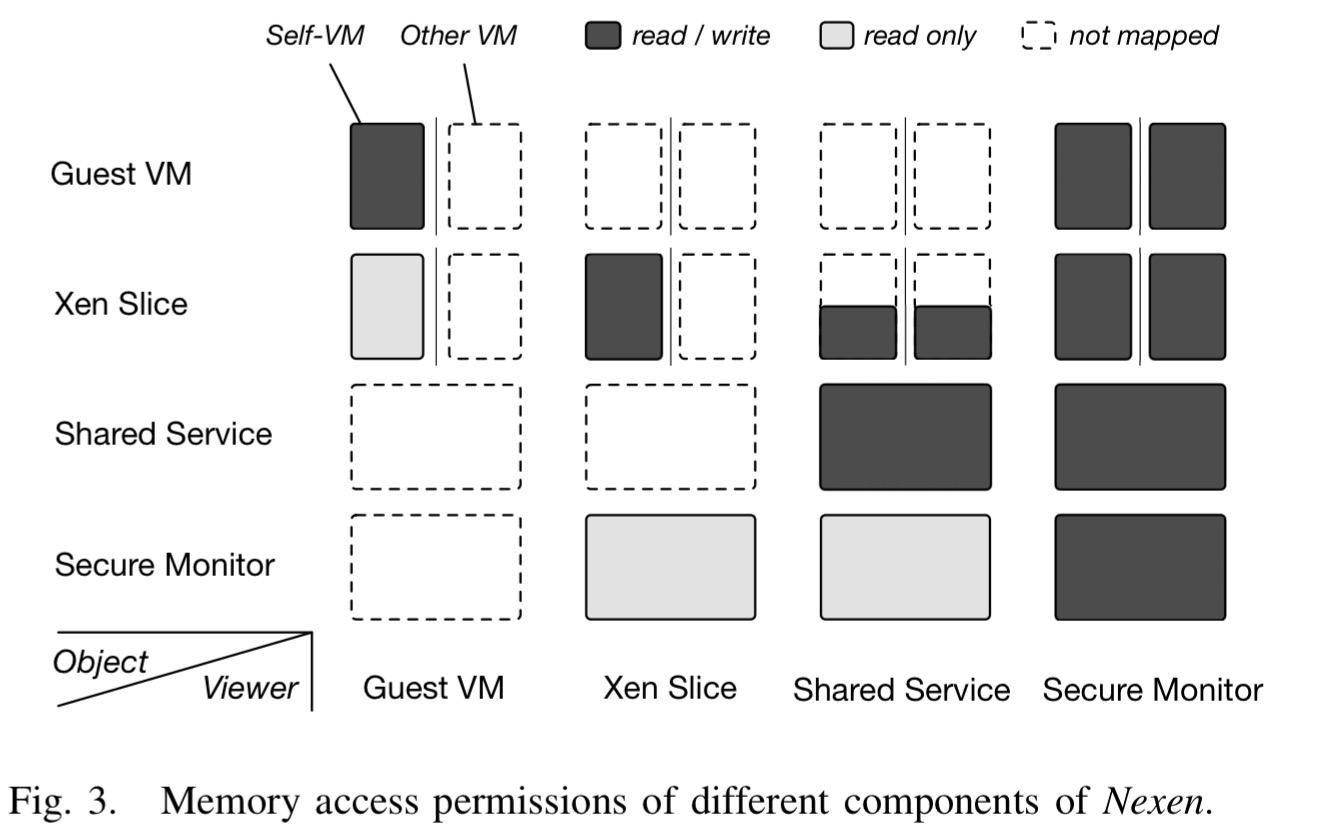
If an internal domain wants to execute a privileged instruction, it has to do so by requesting the monitor to perform the instruction on its behalf (recall that no privileged instructions are allowed above the monitor). This allows the monitor to, well, monitor, such requests and prevent unauthorized or malicious use. For calls between internal domains, Nexen provides a secure call gate. It guarantees that:
- it is not possible to switch to another internal domain without calling the gate
- requests cannot be forged – each call gate is bound to both its return address and its domain type argument
- switches of control flow and address space are atomic
A gate keeper controls all exits from VMs to the hypervisor, and entries from the hypervisor to VMs. Switching between Xen slices is explicitly forbidden since there is no legitimate reason to ever want to do this.
The monitor and slicing services provide an isolation and code integrity foundation, the next challenge is to use these mechanisms to deconstruct Xen in such a way as to maximize the value of least-privilege while minimizing cross-domain interactions. Three principles are followed to guide this process.
- Avoid inserting dangerous functionality into the shared service!
- Avoid runtime communication – guests should not be able to actively invoke shared services
- Separate mechanism from policy: “Complex calculation and decision making can be processed by untrusted code, but the final security sensitive operation must be performed by trusted code.“
Here are the placement decisions and rationale for some of the key components (not an exhaustive list):
- Scheduler – fully inside the shared service, with interfaces for a guest to yield, sleep, or wake its VCPU.
- Event channel – delivers events between guest VMs, the hypervisor, and hardware. Each event channel bucket is placed in the owning VM’s Xen slice. Event sending is proxied through the shared service.
- Memory management – the allocator is only used during booting and domain building so it lives in the shared service. Xen slices are allowed to manage their bound VM’s memory mapping update.
- Code emulation and I/O – emulation code is run in each VM’s Xen slice.
Protection afforded by Nexen
An attacker cannot escalate memory access privilege – either directly writing to a protected memory region or updating the page table in an attempt to gain access will result in a page fault. Nexen kill’s the attackers Xen slice and VM in this case.
An attacker cannot abuse privileged instructions – these have been removed from per-VM slices, so the attacker must reuse those in the security monitor. Sanity checking on calls prevents misuse. If a malicious context is forged causing a jump to the instruction the attacker will stop lose execution control for a while before executing the monitor and sanity checking kicks in again.
An attacker cannot trick the monitor into giving extra priviliges – requesting operation for which the attacker does not have privileges will be rejected, and pretending to be another internal domain is fooled by the unique id number mapped in the read-only region of each domain’s address space.
An attacker cannot fool Xen – Nexen reuses a lot of Xen code, but all memory and instruction invariants and policies are strictly enforced by the security monitor.
There is a clear boundary between those attacks Nexen can and can not prevent. Attacks with their key steps happening in Xen slices can mostly be prevented. This is because Xen slice is a sandbox that can be sacrificed. Exceptions are those trying to crash or leak information to a guest VM with Iago attacks. They do not try to harm the hypervisor or other VMs so sandboxing does not work for them. The gate keeper guards interactions between the hypervisor and VMs. Part of attacks that takes effect in a guest VM can be prevented. However, verifying data corrupted by an Iago attack requires recomputing, which the gate keeper is incapable of.
Of the 144 Xen hypervisor vulnerabilities in the report, Nexen can defend against 96 of them on the Intel x86 platform, and if an equivalent implementation was created for ARM and AMD processors, the architecture would also defend against a further 17 vulnerabilities specific to those processor types. In total, Nexen prevents 107 out of the 144 vulnerabilities.
Here’s an illustrative sample of reported vulnerabilities and how Nexen stops them.
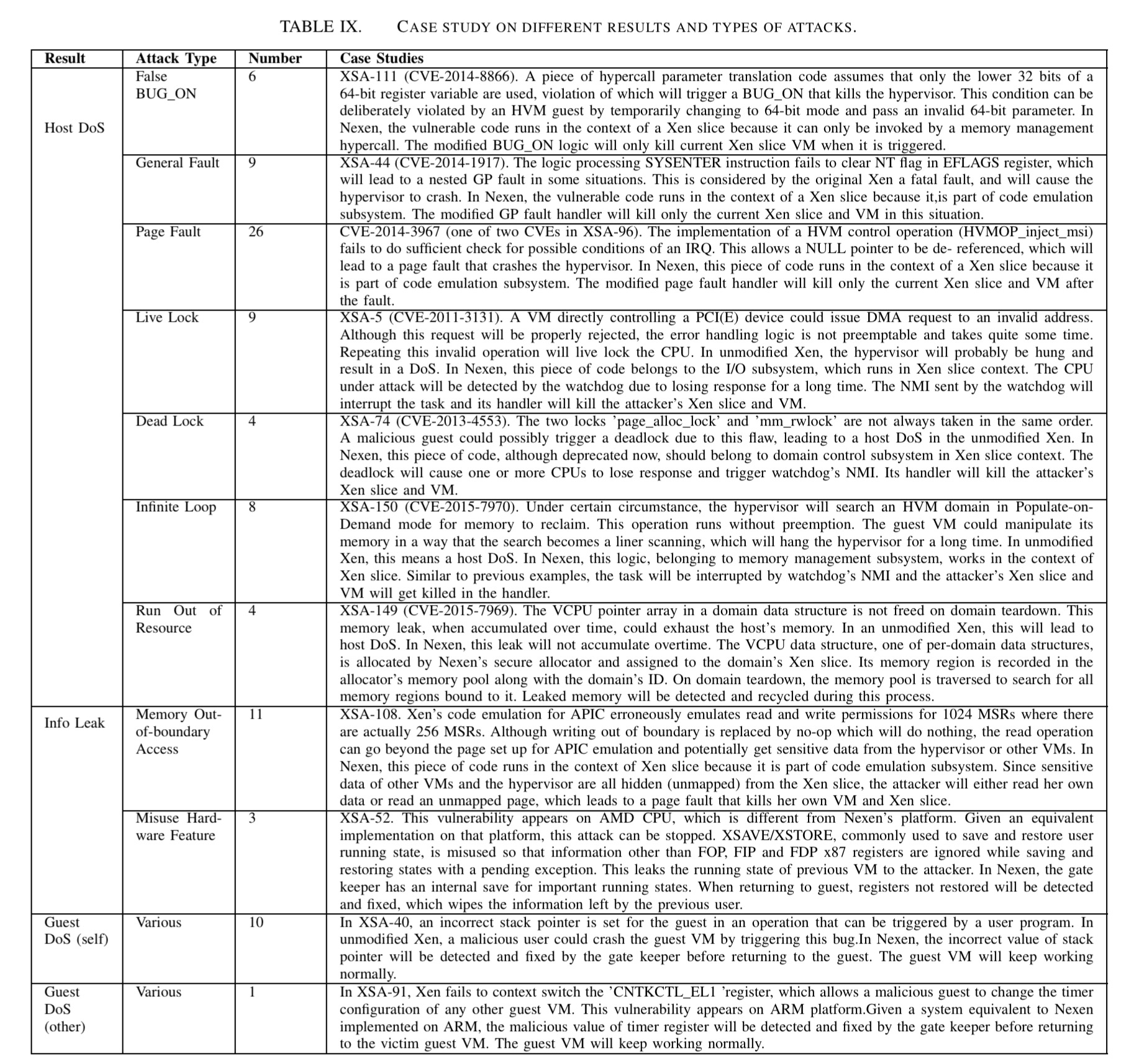 (Click for larger view)
(Click for larger view)
The current main achilles heel of Nexen is the shared service – if a logic error in this component is found and exploited then the hypervisor may still be compromised. Here are a selection of attacks that even Nexen cannot currently prevent:
[ ]((https://blog.acolyer.org/wp-content/uploads/2017/03/deconstrucing-xen-table-x.jpeg) (Click for larger view)
]((https://blog.acolyer.org/wp-content/uploads/2017/03/deconstrucing-xen-table-x.jpeg) (Click for larger view)
Performance overhead
For CPU intensive applications, Nexen has almost no overhead. For memory intensive tasks, the overhead is less than 1%.
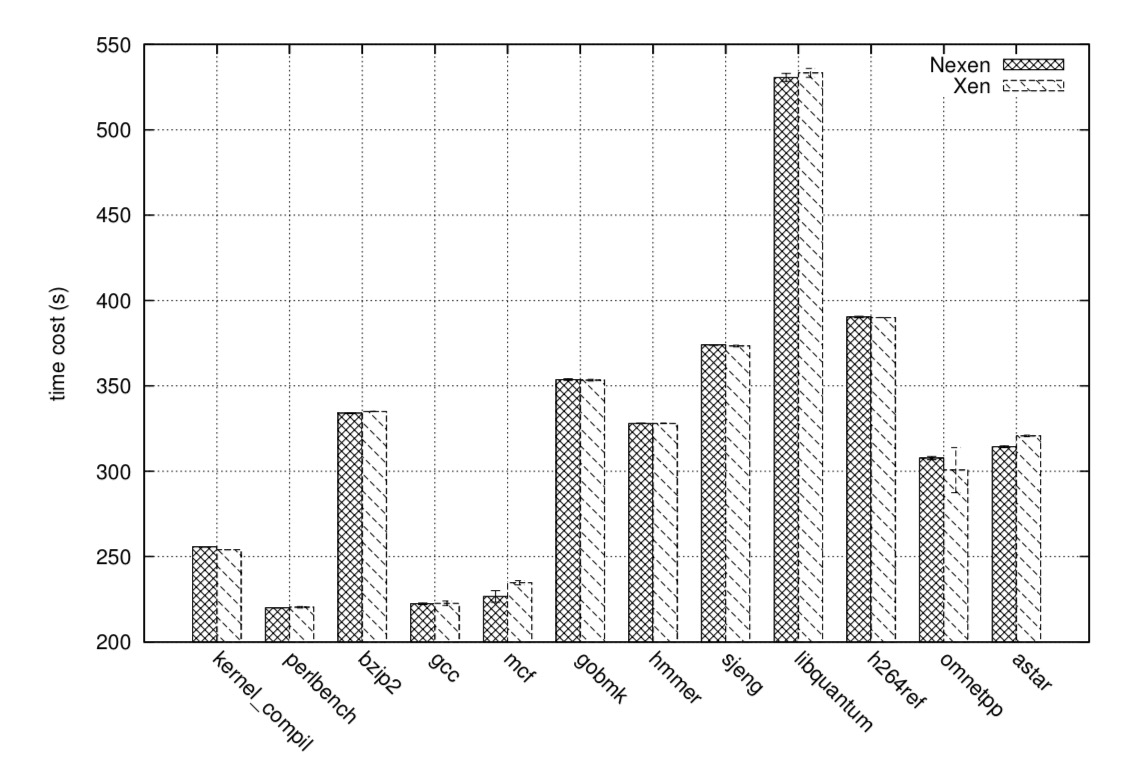
For network I/O the hypervisor is out of the critical path and their is extremely low overhead (about 0.02%). The average overhead in file system I/O is about 2.4%.
Overall, the average overhead of Nexen is about 1.2%. Nexen mainly adds to the latency of VMExits and MMU updates.

{kind=link}
See DJ Bernsteins comments on least privilege https://cr.yp.to/qmail/qmailsec-20071101.pdf