Incremental consistency guarantees for replicated objects Guerraoui et al., OSDI 2016
We know that there’s a price to be paid for strong consistency in terms of higher latencies and reduced throughput. We also know that there’s a price to be paid for weaker consistency in terms of application correctness and / or programmer difficulty. Furthermore, we know that latency matters. This has led to the use of mixed consistency models in some scenarios, but at the cost of increased application complexity.
For instance, in Gemini, operations are either Blue (fast, weakly consistent) or Red (slower, strongly consistent). For sensitive data such as passwords, Facebook uses a separate linearizable sub-system. Likewise, Twitter employs strong consistency for “certain sets of operations”, and Google’s Megastore exposes strong guarantees alongside read operation with “inconsistent” semantics. Another frequent form of differentiated guarantees appears when applications bypass caches to ensure correctness for some operations.
This paper introduces the idea of incremental consistency guarantees whereby an application receives both a preliminary (fast but possibly inconsistent) result and a final correct result that arrives later. When I read that in the abstract, I noted in the margin “sounds like a Promise, but with multiple futures” – and in fact that’s exactly how the idea is presented to the programmer, through a Promise extension called a Correctable.
Sounds intriguing in theory, but is this really a useful idea in practice? For that to be the case, the following would need to hold:
- The programming model is straightforward enough that we make a meaningful reduction in complexity
- You can actually do something useful with the preliminary results!
- The (time) gap between the preliminary and final results is meaningful in the overall context of an application
- The programming model is implementable in a practical manner
- The overheads of possibly doing extra work are not too high
Guerraoui et al. demonstrate that the answer is “yes” on all counts!
The Correctable API offers three ways to invoke an operation: invokeWeak, invokeStrong, and plain invoke. The first two forms allow the programmer to explicitly request just a weakly consistent or strongly consistent result respectively. The form of interest here though is invoke, which is the one that delivers multiple results with increasingly stronger consistency guarantees. Let’s start by looking at the central motivating question: “what use are preliminary results anyway?”
Is a preliminary result really useful?
One thing you could do with incremental consistency guarantees (ICGs) is return a best-effort response within some latency bound. If the strong result arrives in time you return it, otherwise you return the weaker result. Much more interesting though, is the idea of speculation:
The advantage of ICG is that applications can speculate on the preliminary view, hiding the latency of strong consistency and thereby improving performance. Speculating on preliminary responses is expedient considering that, in many systems, weak consistency provides correct results on expectation.
In other words, if you have to do work of some kind after receiving the result, then you can go ahead and do this work as soon as you receive the preliminary result (absent anything which would cause irreversible side-effects). When the final result comes in, if it is unchanged, you can now respond immediately. If it is changed, sometimes some of your speculative work can be reused, other times you may have to throw it away and start over – but in terms of response latency at least you have lost nothing in this case.
Consider a result that causes you to then need to go and fetch multiple dependent objects – these can be prefetched the moment the preliminary result comes in, ready for when the final result arrives.
There may also be application-specific scenarios that can take advantage of preliminary results. Consider thresholding on a monotonically increasing counter – if the preliminary result is already over the threshold, there’s no need to wait any longer.
In other scenarios, it may make sense to expose the preliminary result directly to an end-user, and revise it later.
Here are four examples from the paper where Correctables were used to improve application performance:
- An advertising system that needs to balance speed of ad-serving with freshness. In response to a ‘getAds’ call the preliminary results are used to fetch the actual ad content and media and post-process it (localization and personalization). If the final view corresponds to the preliminary view the ads can be delivered fast, otherwise the delta has to be fetched and processed and the result is delivered later.
- Online ticket sales – when a preliminary result (e.g. on a single local replica) indicates there is plenty of stock left, the purchase can go ahead immediately. If stock is low then instead we may need to wait for a final result (coordinating across replicas).
- A smartphone news reader for a news service replicated using primary-backup. A Correctable ‘getNews’ invocation could return three results, with the display updating on each: firstly from the local cache in the Smartphone; then from the closest backup replica, and finally from a more distant primary replica.
- Tracking transaction confirmations as they accumulate in a blockchain-based application. (“This is a use case we also implemented, but omit for space reasons”).
In some of these use cases, Correctables start to feel a little like a reactive stream approach. But it is always a finite stream in response to a single operation, and each result is a refinement of its predecessor.
What kind of benefit might we be talking about here?
The first question to answer here is whether there’s enough of a delay between preliminary and final results to get any meaningful speculative work done.
Studies show that large load on a system and high inter-replica latencies give rise to large performance gaps among consistency models. To the best of our knowledge, however, there are no studies which consider a combination of incremental consistency models in a single operation…
Here are the results of studying a Cassandra cluster using a single request micro-benchmark, where ‘C’ is the vanilla Cassandra result time, and ‘CC preliminary’ and ‘CC final’ are the preliminary and final results returned by Correctable Cassandra respectively. R=N indicates a quorum size of N for reads.
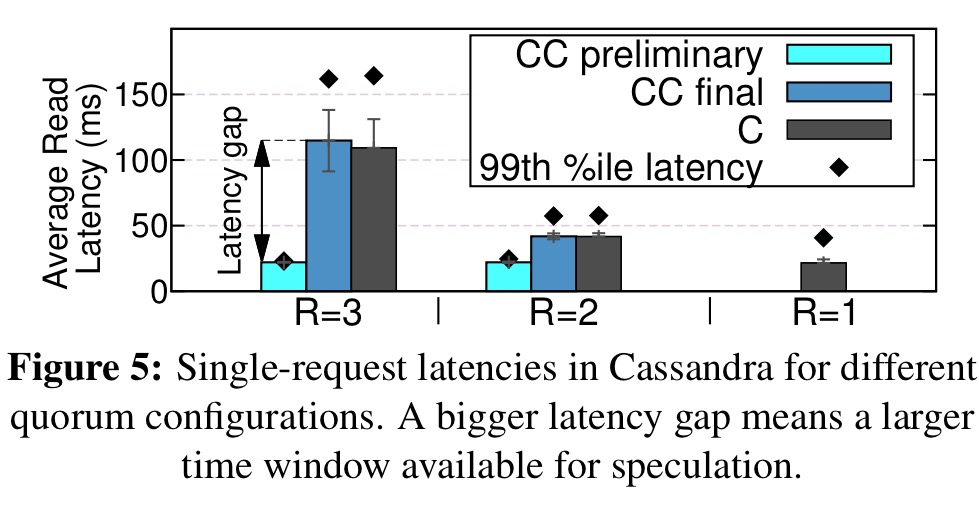
With R=2 the gap between preliminary and final is about 20ms, with R=3 it extends to 140ms.
Using the YCSB benchmark we can see that Correctable Cassandra also has meaningful latency benefits, at a cost of reduced overall throughput.

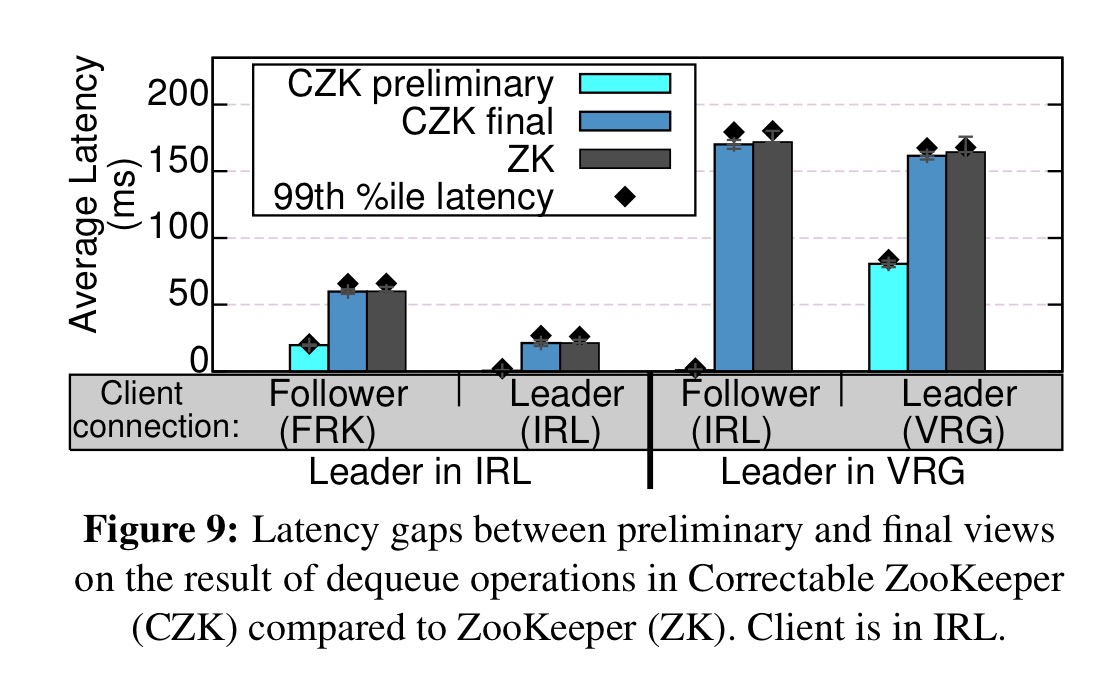
Latency gaps in a (albeit wide-area) ZooKeeper cluster are equally meaningful:
In a ‘Twissandra’ (Twitter clone on Correctable Cassandra) test application, ICG improved latency by up to 40% in return for a throughput drop of 6%.

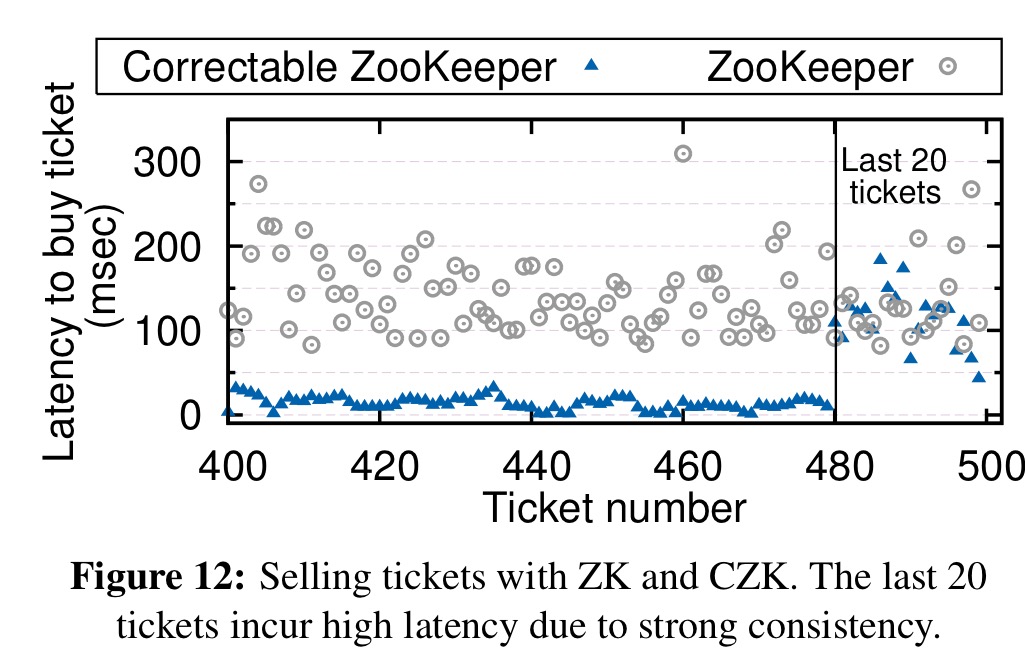
In the ticket selling application, it is clear to see the big advantage of Correctable ZooKeeper when tickets are plentiful:
Is it practical to implement?
The Correctable interface itself is a straightforward extension of the Promise idea. Behind the interface, we need bindings to different underlying backing stores.
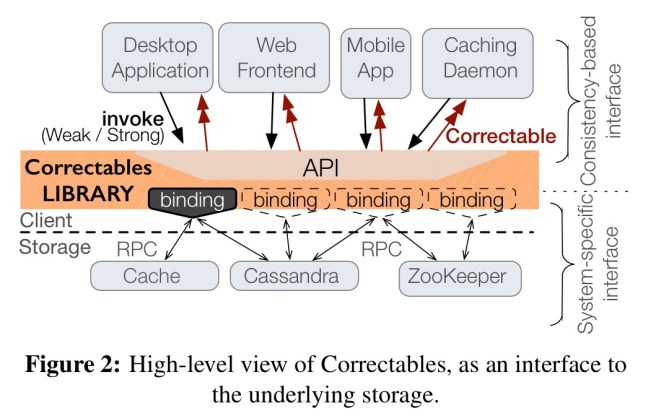
A given binding establishes:
- A concrete configuration of the underlying stack (e.g., Memcache on top of Cassandra)
- The consistency levels offered by the stack
- The implementation of any storage specific protocol (e.g. for coherence or for choosing quorums).
Here’s a simple binding implementation for talking to primary-backup storage engine:

On first glance, ICG might seem to evoke large bandwidth and computation overheads. Indeed, if the invoke method comprises multiple independent single consistency requests, then storage servers will partly redo their own work… With server-side support however, we can minimize those overheads.
An example is to hook into the coordination mechanism of the underlying consistency protocols. A good initial guess can be made from the local replica, before coordinating. Bandwidth for final results can also be saved by only sending a confirmation when they are unchanged from previously sent preliminaries. The authors modified both Cassandra and ZooKeeper to efficiently support ICG using this approach. (The benefits of these enhancement are included in the results earlier).

What’s going on here seems to have parallels (no pun intended) with pipelining in a CPU e.g. the ability to proceed with useful work whilst waiting on the confirmation of an earlier assumption