Generic Attacks on Secure Outsourced Databases Kellaris et al. CCS 2016
Here’s a really interesting paper that helps to set some boundaries around what we can expect from encrypted databases in the cloud. Independently of the details of any one system (or encryption scheme), the authors look at what data it is possible to recover if you are able to observe (enough!) queries and their responses – even when both the queries and the responses are encrypted and opaque. They call this access leakage. You can even learn a lot from communication volume leakage – i.e. how much data is returned.
If a system leaks either access or volume information, then the authors show reconstruction attacks that are able to recover the secret attribute of every record in the database. And which systems leak either access or volume information? Every single system we know of to date!
We use our models to distinguish certain classes of outsourced (secure) database systems that have been proposed, and deduce that all of them exhibit at least one of these leakage sources.
The reconstruction attacks assume very little information on the part of the attacker, beyond being able to observe queries over a period of time:
These attacks are in a rather weak passive adversarial model, where the untrusted server knows only the underlying query distribution. In particular, to perform our attack the server need not have any prior knowledge about the data, and need not know any of the issued queries nor their results.
The saving grace here is that you do potentially need to observe a lot of queries. Say you wanted to recover social security numbers. According to a quick google search, there are about 1 billion possible SSNs. So the domain size, N for SSNs is 109. The reconstruction attack, in order to obtain the SSN for every record in the database, would need to see about N4 queries. 1036 is a very big number, that’s not going to happen. On the other hand, say you’re looking at the 518 datasets from the Texas Hospital Inpatient Discharge Public Use Data File (PUDF), and wanted to recover things like mortality risk (4 possible values), age group (22 possible values), and length of stay (365 possible values), well that it turns out is quite feasible. For dense datasets, the requirement on the number of queries also comes down, to a much more reasonable O(N2). Once you have observed enough queries, it doesn’t take long to reconstruct the values:
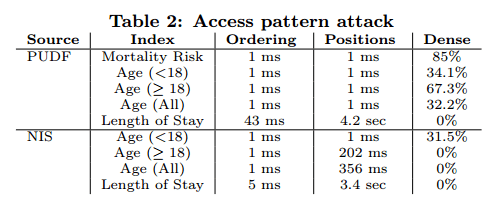
(NIS here is the 2009 HCUP Nationwide Inpatient Sample database).
In contrast to previous attacks on specific systems, our goal is to capture the fundamental leakage rather than the weaknesses of a specific implementation, database, or crypographic tool.
Different types of outsourced database systems
Atomic systems are those in which the database contains encrypted versions of records, and communication between a client and the database system consists of encrypted records, together with encrypted search keys. In a static system, the database is used for querying only (no updates). A non-static system allows updates. A non-storage-inflating system contains no additional encryptions of records or dummy records – most existing practical systems are non-storage inflating.
What gets leaked
Static, atomic, and non-storage inflating database system leak access pattern information.
This includes practical systems based on searchable symmetric encryption or on deterministic and order-preserving encryption.
Outsourced database protocols with fixed communication overhead leak the communication volume.
This includes “full-fledged” protocols based on FHE (Fully homomorphic encryption)or ORAM (Oblivious RAM) in the natural way.
How the reconstruction works (as best I can tell…)
This part of the paper is pretty terse. I’ll explain what I can…
When access pattern leakage is available
Given a typical system based on order-preserving encryption or on symmetric searchable encryption that leaks access patterns, then a reconstruction attack can proceed by determining a mapping from search key domain element to record. This relies on being able to define an ordering on search keys.
- Sample enough queries so that all subsets of indices (in the domain) that can match a query are returned with high probability.
- Deduce an initial estimate of ordering over the sets of returned records, in which they are sorted by search key. This is done using a greedy algorithm that really needs a bit more explanation (in the paper itself) for me to be able to grok it sufficiently to be able to explain it to you. Some of the seven sins are present here!
I shall present the author’s explanation with no further commentary, in the hope that you have more luck than I did!

- Once we have the ordering, if there is at least one record for every domain position (in the search key domain) then we are done. But if there are gaps, we still need to determine which positions are empty…
- This is done by ‘utilising the number of queries that include only the records at each position.’ This also requires a little more explanation! Pseudocode can be found in appendix B.
When only communication volume leakage is available
If there are n records, and N possible values in the domain of the search key (attribute to be recovered) then there are N(N+1)/2) distinct interval queries possible. Look at the number of queries ui that return 0 records, 1 record, 2 records, and so on. The result forms a system of n+1 quadratic equations, which can be factored into a form where the coefficients are u0…un. Solving the system of quadratic equations (using known algorithms) reveals the mapping from search key domain value to records.
Factorization might be slow for large numbers of records. Thus, we design a simple algorithm (in Appendix E) that checks the possible combinations […] in order to determine the correct values, and is faster than factorization in practice.
Are the constraints too artificial?
In reality queries are not uniform. However, we believe that our attacks represent a significant weakness that needs to be addressed, because (1) good systems should provide protection regardless of query distribution (2) uniform or almost uniform queries on a small subset of the domain are realistic, and when that happens our attacks apply, and (3) other than the assumption on the query distribution, our attack model is very weak. Our attacks show that secure outsourced databases should avoid being static non-storage-inflating, as well as with fixed communication overhead.

2 thoughts on “Generic attacks on secure outsourced databases”
Comments are closed.