BigDebug: Debugging primitives for interactive big data processing in Spark – Gulzar et al. ICSE 2016
BigDebug provides real-time interactive debugging support for Data-Intensive Scalable Computing (DISC) systems, or more particularly, Apache Spark. It provides breakpoints, watchpoints, latency monitoring, forward and backward tracing, crash monitoring, and a real-time fix-and-resume capability. The overheads are low for a tool of this nature – less than 24% for record-level tracing, 19% for crash monitoring, and 9% for an on-demand watchpoint. The tool and manual are both available online at http://web.cs.ucla.edu/~miryung/software.html.
Debugging challenges with Apache Spark
Currently, developers do not have an easy means to debug DISC applications. The use of cloud computing makes application development feel more like batch jobs and the nature of debugging is therefore post-mortem. Developers are notified of runtime failures or incorrect outputs after many hours of wasted computing cycles on the cloud. DISC systems such as Spark do provide execution logs of submitted jobs. However, these logs present only the physical view of Big Data processing, as they report the number of worker nodes, the job status at individual nodes, the overall job progress rate, the messages passed between nodes, etc. These logs do not provide the logical view of program execution e.g., system logs do not convey which intermediate outputs are produced from which inputs, nor do they indicate what inputs are causing incorrect results or delays, etc. Alternatively, a developer may test their program by downloading a small subset of Big Data from the cloud onto their local disk, and then run the DISC application in a local mode. However, using a local mode, she may not encounter the same failure, because the faulty data may not be included in the given data sample.
A running case study in the paper resolves around Alice and her program to analyse logs from election polling.

It works fine when run with a subset of the data on Alice’s own machine, but crashes when run against the billions of logs in the full dataset.
Though Spark reports the task ID of a crash, it is impossible for Alice to know which records were assigned to the crashed executor and which specific entry is causing the crash. Even if she identifies a subset of input records assigned to the task, it is not feasible for her to manually inspect millions of records assigned to the failed task. She tries to rerun the program several times but the crash is persistent, making it less probable to occur due to a hardware failure in the cluster.
Crash culprits and remediation
Using BigDebug, Alice is instead provided with the specific record that causes the crash: “312-222-904 Trump Illinois 2015-10-11”. She can see that the date is not in the format her program expects, causing a crash at line 4 in the program.
When a crash occurs at an executor, BIGDEBUG sends all the required information to the driver, so that the user can examine crash culprits and take actions as depicted in Figure 8 [below]. When a crash occurs, BIGDEBUG reports (1) a crash culprit—an intermediate record causing a crash (2) a stack trace, (3) a crashed RDD, and (4) the original input record inducing a crash by leveraging backward tracing…

The user can elect to either skip the crash culprit record, correct it, or supply a code fix so that it can be processed. While waiting for user resolution, BigDebug continues processing the remaining records so that throughput is not affected. Only once an executor reaches end of task does it wait for the user. If there are multiple crash culprits, BigDebug lets them all accumulate and only waits at the end of the very last executor.
The last executor on hold then processes the group of corrected records provided from the user, before the end of the stage. This method applies to the pre-shuffle stage only, because the record distribution must be consistent with existing record-to-worker mappings. This optimization of replacing crash-inducing records in batch improves performance.
If the user elects to provide a code fix, a repair function is provided by the user that is then run on the offending records to transform them in such a way that processing can continue. Alternatively, BigDebug supports a Realtime Code Fix feature that allows the user to supply a new function that will be used to process all records. The function is compiled using Scala’s NSC library and shipped to each worker.
Tracing
In the general case, after seeing a record that causes a particular executor to fail, Alice will want to understand the provenance of that record – how it relates to the original input sources. BigDebug is able to issue a data provenance query on the fly, implemented through an extension of Spark’s RDD abstraction called LineageRDD.
Provenance data is captured at the record level granularity, by tagging records with identifiers and associating output record identifiers with the relevant input record identifier, for a given transformation. From any given RDD, a Spark programmer can obtain a LineageRDD reference and use it to perform data tracing—i.e., the ability to transition backward (or forward) in the Spark program dataflow, at the record level. BIGDEBUG instruments submitted Spark programs with tracing agents that wrap transformations at stage boundaries. These agents implement the LineageRDD abstraction and have two responsibilities: (1) tag input and output records with unique identifiers for a given transformation and (2) store the associations between input and output record identifiers as a data provenance table in Spark’s native storage system.
Based on this information, BigDebug supports a goBackAll() query which given a result record returns all source input records that were used to compute it. Likewise goNextAll() returns all result records that a starting record contributes to. (There are also single-step goBack() and goNext() operations).
Breakpoints
A traditional breakpoint pauses the entire application execution at the breakpoint. For a Spark program, this would manifest as each executor processing its data until it reached the breakpoint in the DAG, and then pausing to wait for user input. BigDebug doesn’t do this, since it results in reduced throughput and wasted resources across the cluster. Instead, simulated breakpoints allow the user to inspect intermediate results at a breakpoint, and to resume execution from that point even though the program is still running in the background. BigDebug supports this by spawning a new process when a breakpoint is hit, which records the transformation lineage at the breakpoint.
When a user requests intermediate results from the simulated breakpoint, BIGDEBUG then recomputes the intermediate results and caches the results. If a user queries data between transformations such as flatmap and map within the same stage, BIGDEBUG forces materialization of intermediate results by inserting a breakpoint and watchpoint (described next) API call on the RDD object to collect the intermediate results.
If the user then resumes computation, BigDebug will jump to the computation that has been proceeding in the background. For step over support, a new workflow begins from the nearest possible materialization point.
The user can also apply a temporary fix at a breakpoint, saving the time and costs of restarting the whole job from the beginning:
To save the cost of re-run, BIGDEBUG allows a user to replace any code in the succeeding RDDs after the breakpoint. If a user wants to modify code, BIGDEBUG applies the fix from the last materialization point rather than the beginning of the program to reuse previously computed results. Assuming that a breakpoint is in place, a user submits a new function (i.e., a data transformation operator) at the driver. The function is then compiled using Scala’s NSC library and shipped to each worker to override the call to the original function, when the respective RDD is executed.
Watchpoints
On-demand watchpoints can be created with a user-supplied guard function. The guard function acts as a filter and a watchpoint will retrieve all matching records. It is possible to update the guard function to refine it while the program is executing. The NSC library is used to compile the guard at the driver node, and then it is shipped to all executors.
Latency alerts
In big data processing, it is important to identify which records are causing delay. Spark reports a running time only at the level of tasks, making it difficult to identify individual straggler records—records responsible for slow processing. To localize performance anomalies at the record level, BIGDEBUG wraps each operator with a latency monitor. For each record at each transformation, BIGDEBUG computes the time taken to process each record, keeps track of a moving average, and sends to the monitor, if the time is greater than k standard deviations above the moving average where default k is 2.
Breakpoints, watchpoints, and latency alerts are all implemented as instrumented Spark programs under the covers, which make calls to the BigDebug API.

Overheads
The following charts show the results of an evaluation of BigDebug’s scalability and overheads (click for larger view):
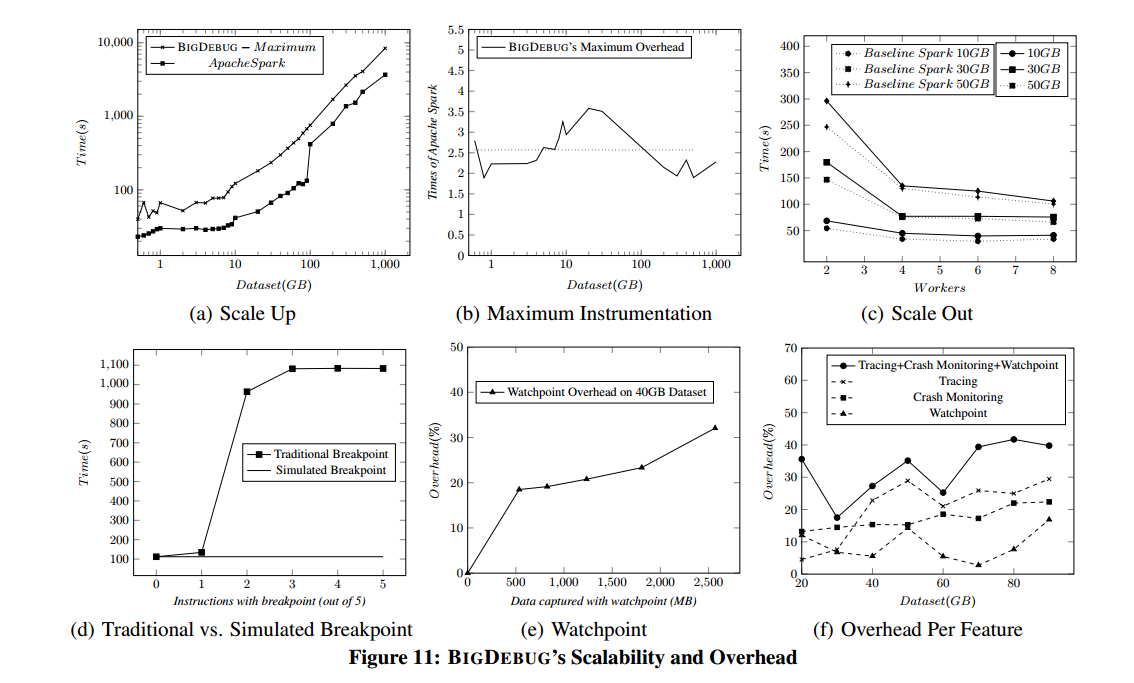
We can see that (a) even with maximum instrumentation (breakpoints and watchpoints on every line) the running time of BigDebug grows steadily in proportion to the base Spark runtime even as data sizes grow to 1TB; (b) the worst case overhead for this maximal instrumentation is 2.5x for word count – with latency measurement disabled it is 1.34x; (c) BigDebug does not affect the scale-out property of Spark; (d) simulated breakpoints have almost 0 overhead when used to pause and then resume; (e) on-demand watchpoint overhead varies with the amount of data captured, for 500MB of transferred data, it is 18%; (f) the combined overheads for tracing, crash monitoring, and watchpoints are in the 30-40% range. This can be reduced by selective use of individual features.

2 thoughts on “BigDebug: Debugging primitives for interactive big data processing in Spark”
Comments are closed.