Polaris: Faster Page Loads Using Fine-Grained Dependency Tracking – Netravali et al. 2016
Yesterday we looked at Shandian which promised faster web page load times, but required a modified client-side browser. Today we’re sticking with the theme of reducing page load times with Polaris. Unlike Shandian, Polaris works with unmodified browsers, and in tests with content from 200 sites out of the top Alexa 500 it is able to reduce load times by 34% at the median, and 59% at the 95th percentile.
To load a page, a browser must resolve the page’s dependency graph. The dependency graph captures “load-before” relationships between a page’s HTML, CSS, JavaScript, and image objects.
Consider a browser parsing an HTML file that encounters a script tag. It has to halt the parsing and rendering of the page to download the linked .js file and evaluate it as this may alter the downstream HTML, or define JavaScript state required by later script files.
Synchronously loading JavaScript files guarantees correctness, but this approach is often too cautious. For example, if
first.jsandsecond.jsdo not modify mutually observable state, the browser should be free to download and evaluate the files in whatever order maximizes the utilization of the network and the CPU. However, pages do not expose such fine-grained dependency information to browsers…
(Yes, “ tags can be marked with async or defer attributes, but by default they have neither. In the test corpus of 200 popular sites, this accounts for 98.3% of all scripts…).
The Scout tool is used to load a page offline and produce a fine-grained dependency graph that is much more detailed than those produced by prior frameworks. “For 81% of the 200 real-world pages that we examined, our new graphs have different critical paths than those of graphs from prior work.”
Polaris is a dynamic client-side scheduler that uses the dependency graphs created by Scout to reduce page load times:
When a user makes a request for a Polaris-enabled page, the server returns a scheduler stub instead of the page’s original HTML. The scheduler stub includes the Polaris JavaScript library, the page’s fine-grained dependency graph (as generated by Scout), and the original HTML. The Polaris library uses the Scout graph, as well as dynamic observations about network conditions, to load objects in an order that reduces page load time.
Scout
Given simply lexical dependency information, then:
- A script tag might read CSS style properties from the DOM tree, so CSS evaluation must block JavaScript execution
- A script tag might change downstream HTML, so when a browser encounters such a tag it must block or transfer HTML parsing to a speculative thread
- Two script tags that are lexically adjacent might exhibit a read/write dependency on JavaScript state. Thus browsers must execute the script tags serially…
Scout finds out the true dependencies, not just the potential ones. It captures three types of data flows involving the JavaScript heap and the DOM state belonging to HTML and CSS:
- Write/read dependencies: one object produces state that another object consumes. E.g. a global variable created by
a.jsand later read byb.js. - Read/write dependencies: one object must read a piece of state before the value is updated by another object. For example, JavaScript code reading a DOM value before the value is changed by the HTML parser. “Any reordering of object evaluations must ensure value equivalence for DOM queries – regardless of when a JavaScript file is executed, its DOM queries must return the same results.”
- Write/write dependencies: two objects update the same piece of state, and we must preserve the happens-before relationship. For example, CSS files update DOM state, changing the rules which govern a page’s visual presentation. The CSS specification states that if two files update the same rule, the last writer wins.
…once we know the DOM dependencies and JavaScript heap dependencies for a
scripttag, the time at which the script can be evaluated is completely decoupled from the position of thescripttag in the HTML – we merely have to ensure that we evaluate the script after its fine-grained dependencies are satisfied. Similarly, we can parse and render a piece of HTML at any time, as long as we ensure that we have blocked the evaluation of downstream objects in the dependency graph.
The content of web pages is recorded using Mahimahi. Scout then rewrites each JavaScript and HTML file in the page adding instrumentation to log the fine-grained data flows across the JavaScript heap and the DOM. The page is then loaded in a regular browser and the log is used to generated the dependency graph.
For a given page, a web server may generate a different dependency graph for different clients… The server-side logic must run Scout on each version of the dependency graph. We believe that this burden will be small in practice, since even customized versions of a page often share the same underlying graph structure (with different content in some of the nodes).
An analysis of 200 sites from the Alexa top 500 showed that Scout finds 30% more edges at the median, and 118% more edges at the 95% percentile than existing dependency analysis tools (Klotski, WProf).
Those additional edges have a dramatic impact on the characteristics of dependency graphs. For example, adding fine-grained dependencies alters the critical path length for 80.8% of the pages in our corpus.
Polaris
Polaris is written completely in JavaScript and can be run on unmodified commodity browsers. It combines the dependency graph produced by Scout with observations about current network conditions to determine the dynamic critical path for a page.
The dynamic critical path, i.e. the path which currently has the most unresolved objects, is influenced by the order and latency with which network fetches complete; importantly, the dynamic critical path may be different than the critical path in the static dependency graph.
To load a page using Polaris, a web server is configured to respond to page requests with the Polaris scheduler stub HTML. This contains four components:
- The scheduler itself, as inline JavaScript code
- The Scout dependency graph, as a JavaScript variable inside the scheduler
- DNS prefetch hints to indicate that the scheduler will be contacting certain hostnames in the near future. “DNS hints allow Polaris to pre-warm the DNS cache in the same way that the browser does during speculative HTML parsing.”
- The page’s original HTML, broken into chunks by Scout as determined by Scout’s fine-grained dependency resolution.
Across the 200 sites in test corpus, the schedule stub increased page size by 36.5KB (3%) at the median.
Since modern browsers limit a page to at most six outstanding requests to a give origin, Polaris maintains per-origin priority queues.
With the exception of the top-level HTML (which is included in the scheduler stub), each object in the dependency graph belongs to exactly one queue. Inside a queue, objects that are higher in the dependency tree receive a higher priority, since those objects prevent the evaluation of more downstream objects. At any given moment, the scheduler tries to fetch objects that reside in a dynamic critical path for the page load. However, if fetching the next object along a critical path would violate a per-origin network constraint, Polaris examines its queues, and fetches the highest priority object from an origin that has available request slots.
How well does it work?
… we demonstrate that Polaris can decrease page load times across a variety of web pages and network configurations: performance improves by 34% and 59% for the median and 95th percentile sites, respectively. Polaris’ benefits grow as network latencies increase, because higher RTTs increase the penalty for bad fetch schedules. Thus, Polaris is particularly valuable for clients with cellular or low-quality wired networks. However, even for networks with moderate RTTs, Polaris can often reduce load times by over 20%.

A closer look at three sites, Apple, ESPN, and Weather.com shows the impact the dependency graph has on the benefits that Polaris can bring:
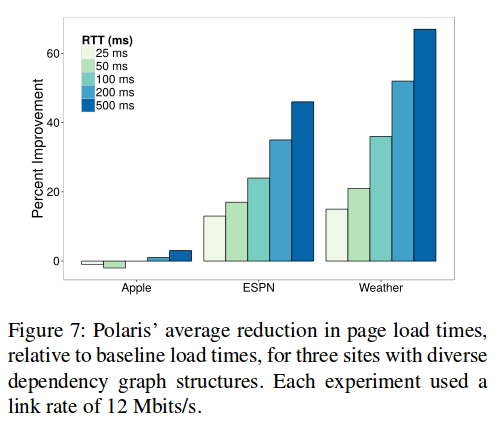
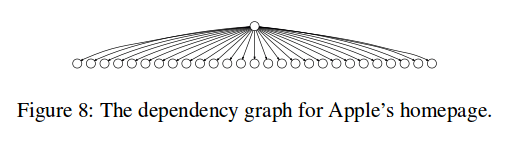
Apple’s home page has a flat dependency graph such that once the top-level HTML is loaded, all other objects can be fetched and evaluated in an arbitrary order. For low RTTs, this makes Polaris slower than the baseline.
Weather.com has a much more complex dependency graph, which enables Polaris to beat the baseline handsomely.
Polaris was also tested in conjunction with SPDY and found to be complementary: load times using Polaris over SPDY are 2.05%-4.03% faster than those with Polaris over HTTP/1.1.
