Sieve: Cryptographically Enforced Access Control for User Data in Untrusted Clouds – Wang et al. 2016
Who owns your data? With cloud services, ‘your’ data is typically spread across multiple walled gardens, one per service. I’m reminded of a great line from “On the duality of resilience and privacy:”
It is a truth universally acknowledged that centralized cloud services offer the opportunity to monetize vast aggregates of personal data.
This is problematic for users, say the authors of Sieve, since they lose control over the storage of their data, and the ability to enumerate all of their data. It is also potentially problematic for the services themselves:
Data silos are problematic not only for users, but for applications whose value often scales with the amount of user data that is accessible to that application. For example, quantified self applications, which track a user’s health and personal productivity, work best when given data from a variety of sensors and environmental locations.
Sieve introduces a user-centric storage model, whereby a user’s entire data set resides in a single logically centralized cloud store (in a format whereby the cloud store cannot interpret it), and the user selectively discloses portions of the data to individual third-party applications. Of course, the minute you disclose a portion of your data to a third-party application, the very first thing I expect that application/service to do is cache it in its own data stores. So we end up in a situation whereby you have fragments of your data in multiple walled gardens – let’s assume stored in the clear – and you have a centralized encrypted store of your full data set. So how exactly does that make the situation any better? I can think of a few scenarios:
- It avoids the user having to repeatedly upload the same data to multiple services, instead they can just upload it once to Sieve, and then grant services access to read the portions of the data they need access to from there.
- There is a similar argument when it comes to updating data – you can update it once in Sieve, and have all services dependent on that data pick up the changes. Moving house? So much easier…
- The user retains control over all of their data. Suppose that instead of uploading all of their activity data to an activity tracking service, they upload it to Sieve and grant the tracking service access to it from there. Now the user wants to work with that data in another service – easy to do using Sieve, difficult or potentially impossible if the data is locked in a walled garden the user doesn’t control.
All of this relies on the services being able to understand / import data in some agreed upon format. Sieve relies on FOAF for human data, and RDF as the schema model for data about user objects. Another important element in Sieve is the ability to revoke access to services – this feature only really makes sense for services that need continual access to new data (e.g. the latest fitness tracking data set), since we must assume that data already seen by a service is cached locally by that service and we have no power to revoke it.
Sieve is a new acces control system that allows users to selectively expose their private cloud data to third party web services. Sieve uses attribute-based encryption (ABE) to translate human-understandable access policies into cryptographically enforceable restrictions. Unlike prior solutions for encrypted storage, Sieve is compatible with rich, legacy web applications that require server-side computation. Sieve is also the first ABE system that protects against device loss and supports full revocation of both data and metadata.
Sieve has three main components: a client GUI and SDK that client side applications can use to upload data and authorise access to it; a storage daemon that runs at the storage provider; and an import daemon that third-party applications can use to gain access to data stored in the Sieve system.
The basic flow is as follows:
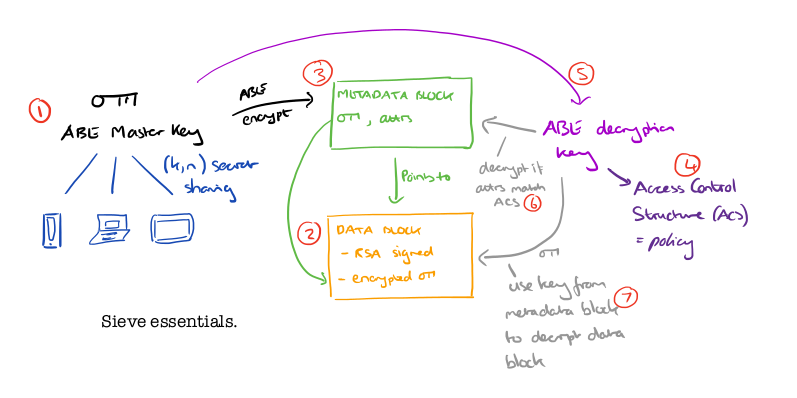
- The client has an ABE (Attribute Based Encryption) master key. This key is split across n devices, in such a way that at least k of them are needed in order to assemble the key (k,n secret sharing). By default k=2, which is equivalent to two-factor authentication.
- When the user wants to upload some new data, the data is signed with an RSA key (to prevent tampering), and then the signed data is encrypted using a newly generated symmetric key encryption key. The result is uploaded to the cloud storage provider, which returns a GUID for accessing the data block.
- The client creates a metadata block which contains the GUID, the symmetric encryption key used to encrypt (and decrypt) the data in the data block, and a set of metadata attributes describing the data. This data block is encrypted using the more expensive ABE encryption and uploaded to the cloud storage provider.
- If the user wants to grant access to their data to a new third-party service they write a policy (a boolean expression combining attribute comparisons) which is encoded as an Access Control Structure (ACS). An example policy might be
(fileType='medicalRecord' AND year>2010 AND doctor='John') - A new ABE decryption key is generated using the associated ACS, and given to the third-party service.
- The third-party service can now decrypt metadata blocks which have attributes matched by the ACS.
- Using the GUID and symmetric encryption key from the decrypted metadata block, the third-party service can find and decrypt the data block.
A web service caches its ABE (decryption) key, and it may also cache symmetric keys and GUIDs, to avoid repeated fetches and decryptions of metadata blocks. Caching makes revocation tricky, since a user that wants to revoke a service’s access rights cannot force the service to delete cached keys. An honest storage provider can refuse access requests from deprivileged third parties, but if the storage provider is compromised, it can leak data that is
encrypted with ostensibly revoked keys that are still in the wild.
Sieve deals with this issue by re-encrypting the data and metadata blocks with new keys not shared by the party whose privileges are revoked. The re-encryption happens at the cloud provider, without placing the burden of re-encryption on the client. “The storage provider learns nothing about the old encryption key, the new encryption key, or the underlying cleartext; the user avoids the need to download, re-encrypt, and re-upload data from personal devices.”
So how on earth does the sieve daemon at the cloud provider manage to re-encrypt data blocks without decrypting them first? The secret is the use of an additively key homomorphic encryption function for the symmetric key encryption of data blocks. Additive key homomorphism means that for two keys k and k’, F(k,x).F(k’,x) = F(k+k’,x). For an object encrypted by k, the client generates a re-keying token δ = -k + k’, where k’ represents the new encryption key. The client sends δ to the storage provider which then encrypts the data block using this key. The result is the same as if the original data had been encrypted with k’, since F(-k+k’,x).F(k,x) = F(-k+k’ + k,x) = F(k’,x), but the server never learns either k or k’.
Metadata blocks are encrypted with ABE encryption though, so we need to use a different tactic for them…
Each user device maintains an integer counter called the epoch counter. The counter is initialized to zero, and represents the number of revocations that the user has performed. When a user device generates a new ABE key, Sieve automatically tags the key with an epoch attribute that is set to the current value of the epoch counter. The epoch attribute is a standard ABE attribute.
After reencrypting the data block using homomorphic encryption the user increments the epoch counter and then generates a new metadata block for each re-encrypted object, inserting the new k. The new metadata block is uploaded, and a new ABE key which encodes the new epoch value in its ACS is sent to any non-revoked web services.
Sieve also supports relabeling of objects (adding, removing, or updating attributes). Relabeling is very similar to the process for revocation:
To implement relabeling, a user’s Sieve client performs three actions. First, the client replaces the old metadata block on the storage server with a new one that contains a new symmetric key and is ABE-encrypted using the new attributes. Second, the client uses homomorphic encryption to re-encrypt the object under the new symmetric key on the storage server. Finally, the client updates storage-based references to the object, ensuring that the references adhere to the object’s new access policy.
Is Sieve Practical?
To answer this question, we integrated Sieve with two applications. The first was Open MHealth, an open-source web service that allows users to analyze their health data. We also integrated Sieve with Piwigo, an open-source online photo manager. We show that the integrations were straightforward, and that the end-to-end application pipelines can handle realistic workloads.
The integration with Open mHealth required 200 lines of code to be changed, and the integration with Piwigo required approximately 250 lines of code to be added. Importing a weeks worth of data to mHealth took 469ms, and uploading / downloading a 375KB photo in Piwigo took approximately 6 seconds in each direction.
