The Design and Implementation of the Wave Transactional Filesystem – Escriva & Sirer 2015
Since we’ve been looking at various combinations of storage and transactions, it seemed appropriate to start this week with the Wave Transactional Filesystem. Throughout the paper you’ll find this abbreviated as WTF, but my brain can’t read that without supplying the alternate meaning so I shall refer to it as Wave FS during this post except when quoting directly from the paper.
Distributed filesystems are a cornerstone of modern data processing applications… Yet current distributed filesystems exhibit a tension between retaining the familiar semantics of local filesystems and achieving high performance in the distributed setting. Often designs will compromise consistency for performance, require special hardware, or artificially restrict the filesystem interface.
The Wave Transactional Filesystem (Wave FS) is a distributed filesystem that provides a transactional model. A transaction can span multiple files and contain any combination of reads, writes, and seeks. The key to this is a file-slicing abstraction, on top of which both a traditional POSIX interface and a file-slice aware interface are provided.
A broad evaluation shows that WTF achieves throughput and latency similar to industry-standard HDFS, while simultaneously offering stronger guarantees and a richer API. A sample application built with file slicing outperforms traditional approaches by a factor of four by reducing the overall I/O cost. The ability to make transactional changes to multiple files at scale is novel in the distributed systems space, and the file slicing APIs enable a new class of applications that are difficult to implement efficiently with current APIs. Together, these features are a potent combination that enables a new class of high performance applications.
The basic idea is very easy to understand: file data is kept in immutable, arbitrarily-sized, byte-addressable, sequences of bytes called slices. Think of this like an old fashioned film reel containing a sequence of video frames. If a portion of the file is to be overwritten, the new bytes are written to a new slice (like recording a new take of a scene). We then go the the cutting room floor to splice the new slice into the original at the desired point. This is where the analogy breaks down a little, because Wave FS never changes the original bytes on disk. Instead information about the slices and splice-points is kept in metadata separate to the slices themselves. By reading the metadata and following the instructions there it is possible to reconstitute the current state of the file. A file in Wave FS is a sequence of slices and their associated offsets.
A worked example should help to make this clear. Let’s consider the history of a file foo, which we happen to write/update in 1MB chunks. The first write creates a 2MB slice, ‘A’.

Then we append 2MB to the end of the file by writing slice ‘B’ and updating the metadata.
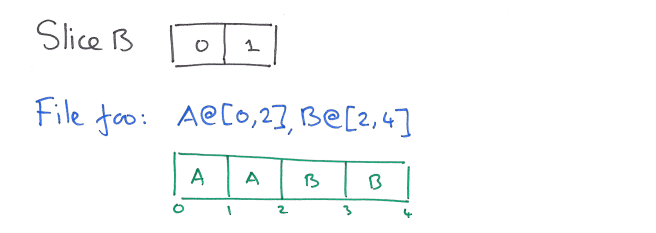
Another process overwrites 2MB in the center of the file:
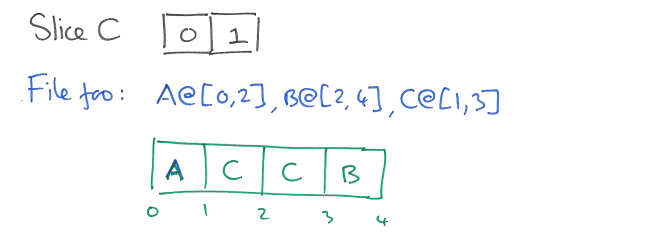
The next update overwrites the third MB:

And so does the final update:
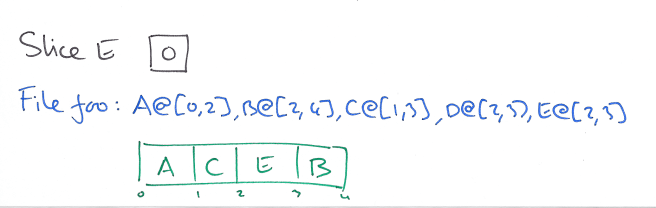
Compaction compresses the metadata, and garbage collection can later kick-in and delete slice D.
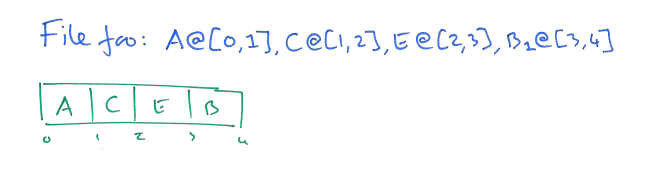
Thus we have immutable slices, and mutable metadata.
This representation has some inherent advantages over block-based designs. Specifically, the abstraction provides a separation between metadata and data that enables filesystem-level transactions to be implemented using, solely, transactions over the metadata. Data is stored in the slices, while the metadata is a sequence of slices. WTF can transactionally change these sequences to change the files they represent, without having to rewrite the data.
Custom storage servers hold filesystem data and handle the bulk of the I/O requests. They know nothing about the structure of the filesystem and treat all data as opaque slices. References to the slices and the metadata that describes how to reconstitute them into files is kept in HyperDex.
The procedures for reading and writing follow directly from the abstraction. A writer creates one or more slices on the storage servers, and overlays them at the appropriate positions within the file by appending their slice pointers to the metadata list. Readers retrieve the metadata list, compact it, and determine which slices must be retrieved from the storage servers to fulfill the read. The correctness of this design relies upon the metadata storage providing primitives to atomically read and append to the list. HyperDex natively supports both of these operations. Because each writer writes slices before appending to the metadata list, it is guaranteed that any transaction that can see these immutable slices is serialized after the writing transaction commits. It can then retrieve the slices directly. The transactional guarantees of WTF extend directly from this design as well: a WTF transaction will execute a single HyperDex transaction consisting of multiple append and retrieve operations.
To support arbitrarily large files and efficient operations on the list of pointers, partitions a file into fixed-size regions, each with its own list. Wave FS also implements transaction retry in its client library on top of HyperDex. This allows for example, an append operation to succeed even if the underlying file length has changed (the semantics of append depend on adding the bytes at the end, not at a certain index position).
The slice-aware alternative API provides yank, paste and append calls that are analogous to read, write, and append but operate on slices instead of bytes. There is also a punch verb that zeros out bytes and frees the underlying storage, as well as concat and copy functions built on these primitives.
Wave FS employs a locality-aware slice placement algorithm to improve disk locality for nearby file ranges, and uses replication to add a configurable degree of fault-tolerance.
To accomplish this, it augments the metadata list such that each entry references multiple slice pointers that are replicas of the data. On the write path, writers create multiple replica slices and append their pointers atomically. Readers may read from any of the replicas, as they hold identical data. The metadata storage derives its fault tolerance from the strong guarantees offered by HyperDex.

Sorry for adding another reference to a 30 year old system, but ..