ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging – Mohan et al. 1992
This is part 5 of a 7 part series on (database) ‘Techniques Everyone Should Know.’
From Peter Bailis’ introduction to this paper in chapter 3 of the Redbook:
Another major problem in transaction processing is maintaining durability: the effects of transaction-processing should survive system failures. A near-ubiquitous technique for maintaining durability is to perform logging: during transaction execution, transaction executions are stored on fault-tolerant media (e.g., hard drives on SSDs) in a log. Everyone working in data systems should understand how write-ahead logging works, preferably in some detail. The canonical algorithm for implementing an “No Force, Steal” WAL-based recovery manager is IBM’s ARIES algorithm…In ARIES, the database need not write dirty pages to disk at commit time (“No Force”), and the database can flush dirty pages to disk at any time (“Steal”); these policies allow high performance and are present in almost every commercial RDBMS offering but in turn add complexity to the database.
ARIES stands for “Algorithm for Recovery and Isolation Exploiting Semantics.” It was designed to support the needs of industrial strength transaction processing systems. ARIES uses logs to record the progress of transactions and their actions which cause changes to recoverable data objects. The log is the source of truth and is used to ensure that committed actions are reflected in the database, and that uncommitned actions are undone. Conceptually the log is a single ever-growing sequential file (append-only). Every log record has a unique log sequence number (LSN), and LSNs are assigned in ascending order.
Log records are first written to volatile storage (e.g. in-memory), and at certain times – such as transaction commit – the log records up to a certain point (LSN) are written to stable storage. This is known as forcing the log up to that LSN. A system may periodically force the log buffers as they fill up.
The WAL protocol asserts that the log records representing changes to some data must already be on stable storage before the changed data is allowed to replace the previous version of that data on non-volatile storage… To enable the enforcement of this protocol, systems using the WAL method of recovery store in every page the LSN of the log record that describes the most recent update performed on that page.
Log records may contain redo and undo information. A log record containing both is called an undo-redo log record, there may also be undo-only log records and redo-only log records. A redo record contains the information to redo a change made by a transaction (if they have been lost). An undo record contains the information needed to reverse a change made by a transaction (in the event of rollback). This information can simply be a copy of the before/after image of the data object, or it can be a description of the operation that needs to be perform to undo/redo the change.
Operation logging permits the use of high concurrency lock modes, which exploit the semantics of the operations performed on the data. For example, with certain operations, the same field of a record could have uncommitted updates of many transactions.
(An example given later in the paper is operational logging of increment and decrement operations for a balance, vs. storing the absolute before/after values of the balance).
A compensation log record (CLR) is used to log the action of rolling back a change (for example, to a prior savepoint in a transaction). In ARIES, CLRs are redo-only log records.
Transaction status is also stored in the log, and no transaction can be considered complete until its committed status and all its log data are safely recorded on stable storage by forcing the log up to the transaction’s commit log record’s LSN. This allows a restart recovery procedure to recover any transactions that completed successfully but whose updated pages were not physically written to nonvolatile storage before the failure of the system. A transaction is not permitted to complete its commit processing until the redo portions of all log records of that transaction have been written to stable storage.
All of this logging is in aid of recovery from failure. There are three basic types of failure we need to concern ourselves with:
- Failure of a transaction (such that its updates need to be undone).
- Failure of the database management system itself – in this scenario we assume that volatile storage contents are lost and recovery must be performed using the nonvolatile versions of the database and log.
- Failure of media/device – in this scenario the contents of just that media are lost, and the lost data must be recovered using an image copy (archive dump) version of the lost data plus the log. Recovery independence is the notion that it should be possible to perform media recovery or restart recovery of objects at different granularities rather than only at the entire database level.
Forcing and stealing policies determine what we can assume about the relative consistency of the log and the database with respect to transaction status.
If a page modified by a transaction is allowed to be written to the permanent database on nonvolatile storage before that transaction commits, then the steal policy is said to be followed by the buffer manager… Steal implies that during normal or restart rollback, some undo work might have to be performed on the non-volatile storage version of the database. If a transaction is not allowed to commit until all pages modified by it are written to the permanent version of the database, then a force policy is said to be in effect. Otherwise, a no-force policy is said to be in effect. With a force policy, during restart recovery, no redo work will be necessary for committed transactions.
The combination of no force and steal policies offers the highest performance. This means that on recovery we many have to undo changes that have been made in the database but are not yet commited, and we may have to redo changes that have been committed but not yet made in the database. We want to support logical undo – that is, we should be able to undo change even if the underlying physical organisation of a database has altered since the change was originally made.
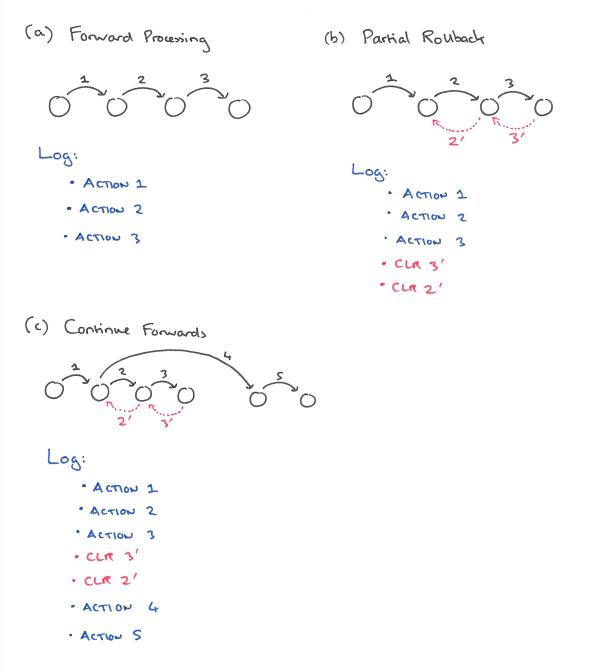
Besides logging, on a per-affected page basis, update activities performed during forward processing of transactions, ARIES also logs, typically using compensation log records (CLRs), updates performed during partial or total rollbacks of transactions during both normal and restart processing… In ARIES, CLRs have the property that they are redo-only log records. By appropriate chaning of the CLRs to log records written during forward processing, a bounded amount of logging is ensured during rollbacks, even in the face of repeated failures during restart of nested rollbacks.
In the following example, a transaction performs three actions before performing a partial rollback by undoing actions 3 and 2. It then starts going forward again and performs actions 4 and 5.
ARIES uses a single LSN on each page to track the page’s state. Whenever a page is updated and a log record is written, the LSN of the log record is placed in the page_LSN field of the updated page. This tagging of the page within the LSN allows ARIES to precisely track, for restart- and media-recovery purposes, the state of the page with respect to logged updates for that page.
ARIES also takes periodic checkpoints that identify the active transactions, their states, and the LSNs of their most recently written log records as well as the dirty data in the buffer pools.
Transactions synchronously write their prepare record to the log, including the list of update-type locks (IX, X, SIX etc.) held by the transactions. Locks are logged so that they can be reacquired during recovery. Once the prepare record is written, read locks can be released. Once a transaction enters the in-doubt state, it is committed by writing an end record and releasing its locks. It is rolled back by writing a rollback record, rolling back the transaction to its beginning, discarding the pending actions list, releasing its locks, and then writing the end record.
Whether or not the rollback and end records are synchronously written to stable storage will depend on the type of two-phase commit protocol used. Also, the writing of the prepare record may be avoided if the transaction is not a distributed one or is read-only.
We now have enough background to look at how ARIES does system restart recovery. Recovery takes place in three phases or passes over the log: an analysis pass, a redo pass, and an undo pass.
The Analysis Pass
During the analysis pass, ARIES scans the log from the first record of the last checkpoint to the end. The purpose of the scan is to obtain information about the dirty pages and in-flight transactions as of the end of the log. The analysis pass determines:
- The starting point (redo LSN) for the following redo pass
- The list of transactions to be rolled back in the undo pass
- The LSN of the most recently written log record for each in-progress transaction
The only log records written during this phase are end records for transactions that had totally rolled back before system failure, but for whom end records are missing.
The Redo Pass
The purpose of the redo pass is to restore the database to its state as of the time of the system failure.
…during the redo pass, ARIES repeats history, with respect to those updates logged on stable storage (i.e. in the log), but whose effects on the database pages did not get reflected on nonvolatile storage before the failure of the system. This is done for the updates of all transactions, including the updates of those transactions that had neither committed nor reached the in-doubt state of two-phase commit by the time of the system failure (i.e., even the missing updates of the so-called loser transactions are redone).
A log record’s update will be redone if the affected page’s LSN is less than the log record’s LSN. The redo pass also obtains the locks needed to protect the uncommitted updates of those distributed transactions that will remain in the in-doubt (prepared) state at the end of restart recovery.
The Undo Pass
In the third and final pass, the undo pass, all loser transactions’ updates are rolled back in reverse chronological order, in a single sweep of the log.
This is done by continually taking the maximum of the LSNs of the next log record to be processed for each of the yet-to-be-completely-undone loser transactions, until no transaction remains to be undone… When a non-CLR is encountered for a transaction during the undo pass, if it is an undo-redo or undo-only log record then its update is undone. In any case, the next record to process for that transaction is determined by looking at the ‘Previous LSN’ field of that non-CLR. Since CLRs are never undone, when a CLR is encountered during undo, it is used just to determine the next log record to process.
Checkpoints
Periodic checkpoints are taken to reduce the amount of work that needs to be performed during restart recovery. Checkpoints can be taken asynchronously while transaction processing is still going on. These are called fuzzy checkpoints. To take a fuzzy checkpoint a begin checkpoint record is written to the log, and then when all information has been gathered an end checkpoint record will be written including within it the contents of the transaction table etc..
Once the end checkpoint record is constructed, it is written to the log. Once that information reaches stable storage, the LSN of the begin checkpoint record is stored in the master record which is kept in a well-known place on stable storage. If a failure were to occur after the end checkpoint record migrates to stable storage, but after the begin checkpoint record migrates to stable storage then that checkpoint is considered an incomplete checkpoint.
ARIES does not require that any dirty pages be forced to nonvolatile storage during a checkpoint. The assumption is that the buffer manager is continuously writing out dirty pages in the background.
It is also possible to take checkpoints during the different stages of restart recovery processing. For example, by taking a checkpoint at the end of the analysis pass, we can save some work if a failure were to occur during recovery.
Media Recovery
We assume that media recovery will be required at the level of a file or some such entity. A fuzzy image copy (also called a fuzzy archive dump) operation involving such an entity can be performed concurrency with modifications to the entity by other transactions. With such a high concurrency image copy method, the image copy might contain some uncommitted updates…
The begin checkpoint record LSN for the most recent complete checkpoint is noted when the fuzzy image copy starts – this is known as the image copy checkpoint. All updates logged in log records with LNSs less than this are assumed to have been externalized to nonvolatile storage by the time the copy operation began. Hence, the image-copied version of the entity should be at least as up to date as of that point in the log. This point is called the media recovery redo point.
When media recovery is required, the image-copied version of the entity is reloaded and then a redo scan is initiated starting from the media recovery redo point. During the redo scan, all the log records relating to the entity being recovered are processed and the corresponding updates are applied, unless the information in the image copy checkpoint record’s dirty pages list, or the LSN on the page makes it unnecessary.
It is the page-oriented logging that provides recovery independence amongst objects.

In ARIES, CLRs have the property that they are re-try just log records. By proper chaning of the CLRs to log records composed amid forward handling, a limited measure of logging is guaranteed amid rollbacks, even notwithstanding rehashed disappointments amid restart of settled rollbacks.