Building Consistent Transactions with Inconsistent Replication – Zhang et al. 2015
Is there life beyond ‘beyond distributed transactions?’ In this paper, Zhang et al. introduce a layered approach to supporting distribution transactions, showing that a Transactional Application Protocol can be built on top of an Inconsistent Replication protocol (TAPIR). This direction is similar in spirit to the work of Bailis et al. in Bolt-on Causal Consistency who show that causal consistency can be layered on top of eventual consistency.
Using TAPIR, the authors build a key-value store (how many KV stores does the world need? ;) ) called TAPIR-KV. We’ve all been trained to believe that there’s a heavy price to pay for distributed transactions, and hence any system with low latency requirements must abandon them. But what we think we know, ain’t necessarily so…
We also compare TAPIR-KV with three widely-used eventually consistent storage systems, MongoDB, Cassandra, and Redis. For these experiments, we used YCSB+T [16], with a single shard with 3 replicas and 1 million keys. MongoDB and Redis support master-slave replication; we set them to use synchronous replication by setting WriteConcern to REPLICAS SAFE in MongoDB and the WAIT command for Redis. Cassandra uses REPLICATION FACTOR=2 to store copies of each item at any 2 replicas.
(These systems would of course offer lower latency if they were configured to use asynchronous replication, but even so…)
[Figure 14] demonstrates that the latency and throughput of TAPIR-KV is comparable to these systems. We do not claim this to be an entirely fair comparison; these systems have features that TAPIR-KV does not. At the same time, the other systems do not support distributed transactions – in some cases, not even single-node transactions – while TAPIR-KV runs a distributed transaction protocol that ensures strict serializability. Despite this, TAPIR-KV’s performance remains competitive: it outperforms MongoDB, and has throughput within a factor of 2 of Cassandra and Redis, demonstrating that strongly consistent distributed transactions are not incompatible with high performance.
(When I look at figure 14, it looks more like throughput within a factor of 3 when comparing to Redis, but the main point still holds.)
It can be confusing navigating all of the claims and counter-claims of various distributed data stores. The PACELC model gives us one way to think about this. In the event of a partition, how does a system trade-off between availability and consistency? And in the absence of a partition, how does a system trade-off between latency and consistency? TAPIR requires connectivity to a majority of replicas (f+1 out of a total of 2f+1) to make progress – favouring consistency over availability for those on the minority side. For the majority partition (the whole system, if there are no partitions), TAPIR shows that the trade-off between latency and consistency may not be as severe as we have been led to believe, which supports the provision of simpler programming models for application developers.
Distributed storage systems provide fault tolerance and availability for large-scale web applications. Increasingly, application programmers prefer systems that support distributed transactions with strong consistency to help them manage application complexity and concurrency in a distributed environment. Several recent systems reflect this trend, notably Google’s Spanner system, which guarantees linearizable transaction ordering.
We’d like to provide this simpler model without paying a heavy cost in coordination.
Modern storage systems commonly partition data into shards for scalability and then replicate each shard for fault-tolerance and availability. To support transactions with strong consistency, they must implement both a distributed transaction protocol – to ensure atomicity and consistency for transactions across shards – and a replication protocol – to ensure transactions are not lost (provided that no more than half of the replicas in each shard fail at once). As shown in Figure 1, these systems typically place the transaction protocol, which combines an atomic commitment protocol and a concurrency control mechanism, on top of the replication protocol (although alternative architectures have also occasionally been proposed).
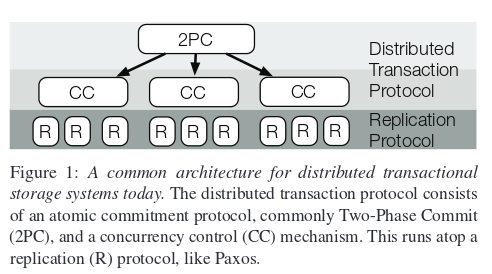
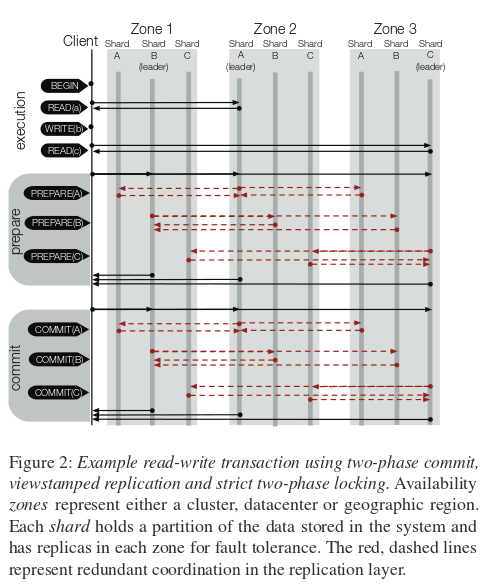
The key insight is that this layering introduces redundancy: the replication protocol enforces a serial ordering of operations across replicas in each shard, and the transaction protocol enforces a serial ordering of transactions across shards. Some of the coordination in the replication layer is redundant given the coordination that occurs in the transaction layer. The authors illustrate this with an example from Spanner: in the figure below, the red dashed lines represent redundant coordination in the replication layer.
TAPIR eliminates the redundancy by layering TAP/IR, where IR is an inconsistent replication protocol.
Despite IR’s weak consistency guarantees, TAPIR provides linearizable read-write transactions and supports globally-consistent reads across the database at a timestamp the same guarantees as Spanner. TAPIR efficiently leverages IR to distribute read-write transactions in a single round-trip and order transactions globally across partitions and replicas with no centralized coordination… Our experiments found that TAPIR-KV had: (1) 50% lower commit latency and (2) more than 3× better throughput compared to systems using conventional transaction protocols, including an implementation of Spanner’s transaction protocol, and (3) comparable performance to MongoDB and Redis, widely-used eventual consistency systems.
The IR Protocol
IR provides fault-tolerance without enforcing any consistency guarantees of its own. Instead, it allows the higher-level protocol, which we refer to as the application protocol, to decide the outcome of conflicting operations and recover those decisions through IR’s fault-tolerant, unordered operation set.
IR provides two different modes for operations: consensus and inconsistent. Inconsistent operations can execute in any order and persist across failures; consensus operations also execute in any order and persist across failures, but return a single consensus result.
From the client’s perspective (implementation of a higher-order application protocol), the client invokes either InvokeConsensus or InvokeInconsistent. For a consensus operation, if the replicas return conflicting or non-matching results then a decide callback provided by the client will be invoked which must return a single consensus result.
A replica provides ExecConsensus and ExecInconsistent operations. To ensure convergence replicas occassionally synchronize:
Similar to eventual consistency, IR relies on the application protocol to reconcile inconsistent replicas. On synchronization, a single IR node first upcalls into the application protocol with Merge, which takes records from inconsistent replicas and merges them into a master record of successful operations and consensus results. Then, IR upcalls into the application protocol with Sync at each replica. Sync takes the master record and reconciles application protocol state to make the replica consistent with the chosen consensus results.
IR does not require synchronous disk writes – guarantees are maintained even if clients or replicas lose state on failure. A successful operation is simply one that returns a result to the application protocol, and an operation set is the set of all successful operations for an IR replica group. An operation X is visible to an operation Y if one of the replicas executing Y has previously executed X. Given these definitions, IR provides the following three guarantees:
- Fault tolerance – every operation in the operation set is in the record of at least one replica in any quorum of at least f+1 non-failed replicas.
- For any two operations in the operation set, at least one is visible to the other
- The result returned by a consensus operation is in the record of at least one replica in any quorum. If the result has been explicitly modified by an application protocol Merge, then the result of the merge will be recorded instead.
See the full paper for details of the IR protocol and a correctness proof sketch. It builds on four sub-protocols: operation processing, replica recovery/synchronization, client recovery, and group membership change. These protocols draw heavily on Viewstamped Replication and also incorporate some ideas from Fast Paxos and Speculative Paxos.
The TAPIR Protocol
To correctly and efficiently enforce higher-level guarantees on top of IR, an application protocol must have certain properties:
- Invariant checks must be performed pairwise.
- Application protocols must be able to change consensus results: “Inconsistent replicas could execute consensus operations with one result and later find the group agreed to a different consensus result.”
- Application protocols should not expect operations to execute in the same order.
- Application protocols should use cheaper inconsistent operations whenever possible rather than consensus operations.
TAPIR applies these principles to provide high-performance linearizable transactions on top of IR.
Using IR, TAPIR can order a transaction in a single round-trip to all replicas in all participant shards without any centralized coordination. TAPIR is designed to be layered atop IR in a replicated, transactional storage system.
The transaction processing guarantees are provided through a combination of IR function implementations, a transaction processing protocol, and a coordinator recovery protocol. The decide callback for TAPIR is straightforward: if a majority of replicas returned PREPARE_OK then it commits the transaction. On the replicas, the merge operation considers transactions with PREPARE_OK status that are not yet committed. It runs an optimistic concurrency control check and aborts any transactions that conflict with other previously prepared or committed transactions, those that do not conflict are merged with PREPARE_OK.
TAPIR’s sync function runs at the other replicas to reconcile TAPIR state with the master records, correcting missed operations or consensus results where the replica did not agree with the group. It simply applies operations and consensus results to the replica’s state: it logs aborts and commits, and prepares uncommitted transactions where the group responded PREPARE-OK.
TAPIR maintains the following three properties given up to f failures in each replica group and any number of client failures:
- Isolation. There exists a global linearizable ordering of committed transactions.
- Atomicity. If a transaction commits at any participating shard, it commits at them all.
- Durability. Committed transactions stay committed, maintaining the original linearizable order.
Full details of the TAPIR protocols and a proof sketch can be found in the paper. For this write-up, I’ve chosen to focus on the central idea of layering a consistent application protocol on top of an inconsistent replication protocol, in order to eliminate redundant coordination.

The code for TAPIR is now available: https://gitlab.cs.washington.edu/syslab/tapir Check it out if you are interested in our paper!