Existential Consistency: Measuring and Understanding Consistency at Facebook – Lu et al. 2015
At the core of this paper is an analysis of the number of anomalies seen in Facebook’s production system for clients of TAO, which is impressively low under normal operation (0.0004%) – to interpret that number of course, we’ll have to dig into what’s being measured and how the system is designed. Related to our recent theme of ‘understanding what’s going on in your distributed system,’ the paper also describes a real-time consistency monitoring and alerting system that has proved to be a good early-warning indicator of problems. Let’s look at the real-time monitoring system first, and then come back to the results of the offline consistency analysis.
Consistency monitoring
The basic idea is to track the consistency of reads both at a global and a regional (cluster) level. A rise in the number of inconsistencies is a strong indicator that something unexpected is happening in the system.
Our practical consistency analysis is designed to operate in real-time and to be lightweight. As a consequence it does not trace all operations on a given object, and thus does not give insights into how often principled consistency models are violated. Instead, it uses injected reads to track metrics that are designed to mirror the health of different parts of the replicated storage.
The metric is termed φ(P)-consistency, and is actually very simple. A read for the same data is sent to all replicas in P, and φ(P)-consistency is defined as the frequency with which that read returns the same result from all replicas. φ(G)-consistency applies this metric globally, and φ(R)-consistency applies it within a region (cluster). Facebook have been tracking this metric in production since 2012.
φ(P)-consistency’s usefulness derives from how it quickly approximates how convergent/divergent different parts of the system are. Increases in network delay, replication delay, misconfiguration, or failures all cause a drop in φ(P)-consistency. An increase in the write rate of the system will also cause a drop in φ(P)-consistency rate, because there will be more writes in flight at any given time. These types of changes can be detected within minutes by our φ-consistency metrics.
The metrics are tracked independently for several different types of data that have different access patterns. If φ(R)-consistency rates increase only for a specific region, this is a good indicator of problems in that region. “In addition, from experience, we have found that certain types of data are more sensitive to operational issues than others. We use their φ(G)-consistency levels as early warning systems.”
One of the sensitive families of data we have found are the objects that store photo comments. Intuitively, this makes sense because of user behavior. When a user uploads a photo, their friends may comment on the photo in interactive conversations. These conversations trigger a series of changes on the same object, which will need to be invalidated multiple times over a relatively short time period. The same object is read by all users who want to view the photo. This effect is exaggerated by users who have a large social graph, and those users’ photos, in particular, produce highly consistency-sensitive objects. Figure 10 (see below) displays the spike in φ(G)-inconsistency rate for photo comment keys after a site event that led to a substantial delay in site-wide invalidations. The rate eventually stabilized at 10%, meaning that about 10% of all photo-comment requests had a chance of returning different values depending on which caching tier the user was assigned to. The plot also shows the φ(G)-inconsistency rates for an aggregation of all objects(“All Objects”) is far less sensitive than photo comment keys.
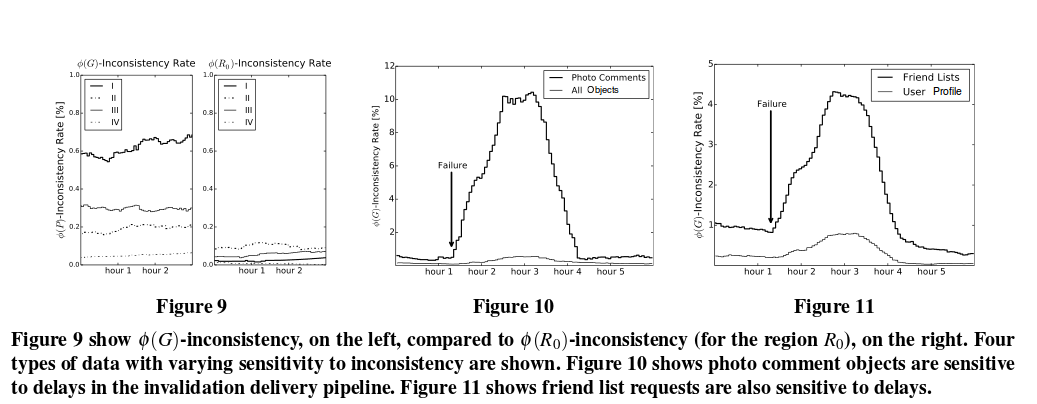
φ(P)-consistency can tell you that there is a problem, but does not help in pinpointing where the problem is. So Facebook also measure φ(S:P)-consistency. For two sets of replicas S and P, it measures the frequency with which requests to s ∈ S return a value equal to the most common value returned by p ∈ P. For example, this metric is often used to compare a given cache tier against the global result which makes it straightforward to identify problematic cache tiers and has proven especially useful for debugging consistency errors.
The φ(P)-consistency checker monitors inconsistency rate in real time and alarms when there is a spike in inconsistency. These alarms are often the first indication of a problem. Engineers use the φ(P)-consistency checker together with other consistency monitoring systems to further investigate root causes.We consider a study of these systems, and how they work interactively to be interesting future work.
Quantifying Anomalies for TAO Clients
So that’s the online analysis, let’s now take a look at the offline analysis of TAO clients that Facebook conducted. The team gathered 12 days of trace data between August 20th and 31st, 2015 (so very recent – not sure how that fits with the March 26th 2015 submission deadline but hey-ho…), capturing 1 in every 1 million requests to end up with a trace containing 2.7B entries.
We designed a set of algorithms to identify anomalies for three consistency models: linearizability, per-object sequential consistency, and read-after-write consistency. Consistency models provide guarantees by restricting the set of possible executions. The basic idea of these algorithms is to identify when a traced execution violates these restrictions,i.e., it is not possible in a system that provides the checked consistency guarantee. Each checker does this by maintaining a directed graph, whose vertices represent the state of an object, and whose edges represent the constraints on the ordering between them. We check for anomalies by checking that the state transition order observed by reads is consistent with these constraints.
(Per-object sequential consistency here = monotonic reads, and read-after-write is also known as read-your-writes). The analysis only concerns single object consistency:
The biggest limitation to our analysis is that it cannot give insights into the benefits of transactional isolation. Transactional isolation is inherently a non-local property and so we cannot measure it accurately using only a sample of the full graph. This unfortunately means we cannot quantify the benefits of consistency models that include transactions, e.g., serializability and snapshot isolation, or the benefit of even read-only transactions on other consistency models. For instance, while our results for causal consistency bound the benefit of the COPS system, they do not bound the benefit of the COPS-GT system that also includes read-only transactions.
So with that said, the linearizability checker looks at all of the operations to one object sorted by invocation time. It outputs all of the anomalous reads (i.e. reads that return results that could not have occurred in a linearizable system). The weaker model checkers are built as add-ons to the linearizability checker, and each operates only on the anomalies found by it.
The results are broken down into anomalies for reads of vertices, and anomalies for reads of edges.
We see a very low percentage of requests to vertices, around 0.00039% [3,628 in total], violate linearizability. Most of these anomalies are stale read anomalies, i.e., the read did not see the most recent update. A smaller number of them are total order anomalies… The source of stale reads is typically replication lag that includes master to slave wide-area replication and asynchronous cache invalidations up the cache hierarchy.While this replication is still ongoing a read may return an older, i.e., stale, version that it would not in a system with stronger consistency. The replication lag can thus be considered the vulnerability period during which anomalies may occur. The effect of increasing replication lag, and thus an increasing vulnerability period is shown in the read-after-write results. Replication lag increases from the cluster to the region and to then global level and we see an increase from 519 to 1,558, and to 3,399 anomalies.
Why such a low anomaly rate: (a) there is a relatively low volume of writes, and (b) by design the system provides read-your-writes consistency within a cluster:
In general, the low percentage of anomalies is primarily due to the low frequency of writes, and the locality of requests to an object. Both of these factors decrease the likelihood of having a read occur during the vulnerability window after a write. The low frequency of writes—i.e., only 1 in 450 operations was a write—directly decreases the likelihood a given read will be during a vulnerability period. The locality of requests to an object also decreases the likelihood of anomalous behavior because Facebook’s clusters provide read-after-write consistency, i.e., there is no vulnerability window within a cluster. Our results mostly validate this claim as we see approximately 1 in 1.8 million requests not receive per-cluster read-after-write consistency. The few exceptions are likely due to cache machine failures.
For edges the anomaly rate is roughly double that for vertices – about 1 in 150,000 requests. This correlates with the higher frequency of updates to edges.
The rate of the different types of anomalies for edges is double what we observed for vertices, with the notable exception of total order violations, and per-user session violations.We see a rate of total order violations that is more than ten times the rate we see with vertices and we see no per-user session violations.We are still investigating the root cause of both of these differences.
60% of all observed edge anomalies are related to ‘like’ edges:
The high update and request rate of “likes” explains their high contribution to the number of overall anomalies. The high update rate induces many vulnerability windows during which anomalies could occur and the high request rate increases the likelihood a read will happen during that window. The top 10 types (of edges) together account for ~95% of the anomalies. These most-anomalous edge types have implications for the design of systems with strong consistency…
The primary benefits of stronger consistency are the elimination of anomalous behaviour that is confusing to users, and a simpler programming model. Figure 8 below shows the potential improvement in anomaly reduction that a variety of consistency models would bring in the Facebook context:
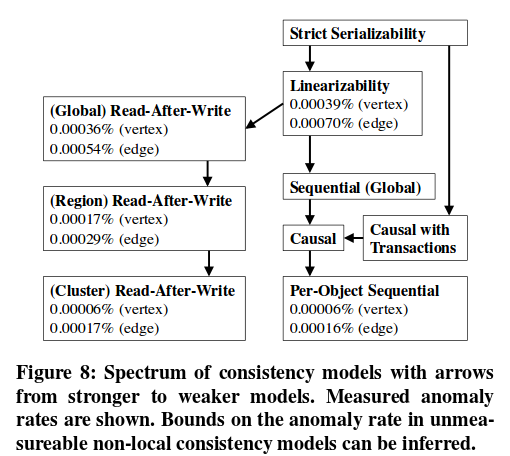
Our observed values for linearizability, per-object sequential consistency, and read- after-write consistency are shown in the spectrum. In addition, the relationship between different consistency models is shown by arrows pointing from a model A to another model B when A is is strictly stronger than B. These relationships allow us to bound the effect of non- local consistency models that we cannot write checkers for, namely (global) sequential consistency, and causal consistency. For instance, because causal is stronger than per-object sequential it would eliminate anomalies from at least 0.00006% of vertex requests and because it is weaker than linearizability it would eliminate anomalies from at most 0.00039% of vertex requests. We also show strict serializability and causal consistency with transactions in the spectrum. Our results give lower bounds for the anomalies each of these models would prevent. We cannot provide upper bounds for them, which we discuss further as a limitation later in this section.
Since a small number of edge types account for a large percentage of the anomalies, there is potential to build systems that only apply stronger consistency where needed (hmm, where have I heard that idea before? ;) ):
This points to two interesting directions for future research into systems with stronger consistency: (1) build system were non-anomalous types have negligible overhead or (2) provide stronger consistency for a small subset of a larger system.While the latter would not prevent all anomalies, it would allow incremental deployment of these systems and significantly reduce the rate of anomalies. Interestingly, such a subsystem that does provide linearizability is used within Facebook for a small set of object types, e.g., passwords.
Overall though, one key finding is that TAO is highly consistent in practice: 99.9% of reads to vertices returned results allowed under the consistency models studied.
Another key finding was that there were anomalies under all of the consistency models we studied. This demonstrates that deploying them would have some benefit. Yet, we also found that these anomalies are rare. This suggests the overhead of providing the stronger models should be low for the trade-off to be worthwhile.
As well as a design that explicitly provides read-your-writes consistency within a cluster, another possible reason for the low anomaly rate is that applications that see larger numbers of anomalies have self-elected to use a different solution:
Our principled consistency analysis found fewer anomalies than we initially expected. Upon reflection, we surmise that it is due primarily to sensitive applications avoiding eventually consistent TAO. Sometimes sensitive applications—e.g., the login framework—mark reads as “critical” in TAO, which then provides linearizability by forcing requests to go through the master-root cache. Other times, sensitive applications will build their own infrastructure to exactly match their consistency needs.

2 thoughts on “Existential Consistency: Measuring and Understanding Consistency at Facebook”
Comments are closed.