Failure Sketching: A Technique for Automated Root Cause Diagnosis of In-Production Failures – Kasikci et al. 2015
Last week was the 25th ACM Symposium on Operating System Principles and the conference has produced a very interesting looking set of papers. I’m going to dedicate the next couple of weeks to reviewing some of these, starting with a selection that continue the theme of last week – understanding what’s going on in production systems.
First up is ‘Failure Sketching.’ By combining some up-front static analysis with dynamic instrumentation, Kasikci et al. show that it is possible to produce automated sketches of the root causes of failures. When evaluated against a set of known bugs in a wide-range of software, failure sketches were very accurate at pinpointing the cause (the thing that the developers ultimately changed in order to fix the bug). To keep the dynamic instrumentation portion at an acceptably low overhead, the authors use the new Intel Processor Trace (PT) facility:
Our design employs Intel PT, a set of new hardware monitoring features for debugging. In particular, Intel PT records the execution flow of a program and outputs a highly-compressed trace (~0.5 bits per retired assembly instruction) that describes the outcome of all branches executed by a program. Intel PT can be programmed to trace only user-level code and can be restricted to certain address spaces. Additionally, with the appropriate software support, Intel PT can be turned on and off by writing to processor-specific registers. Intel PT is currently available in Broadwell processors, and we control it using our custom kernel driver. Future families of Intel processors are also expected to provide Intel PT functionality.
To diagnose root causes of bugs, developers rely on being able to reproduce them. Practitioners report that it can take weeks to fix hard-to-reproduce concurrency bugs…
The greatest challenge though, is posed by bugs that only recur in production and cannot be reproduced in-house. Diagnosing the root cause and fixing such bugs is truly hard. In [57], developers noted: “We don’t have tools for the once every 24 hours bugs in a 100 machine cluster.” An informal poll on Quora [54] asked “What is a coder’s worst nightmare,” and the answers were “The bug only occurs in production and can’t be replicated locally,” and “The cause of the bug is unknown.”
And if we’re going to talk about root causes, it would help to have a definition:
Intuitively, a root cause is the gist of the failure; it is a cause, or a combination of causes, which when removed from the program, prevents the failure associated with the root cause from recurring. More precisely, a root cause of a failure is the negation of the predicate that needs to be enforced so that the execution is constrained to not encounter the failure.
Failure sketching automatically produces a high-level execution trace (called a failure sketch) that includes the statements that lead to a failure, and the differences between the properties of failing and successful program executions. Our evaluation shows that these differences, which are commonly accepted as pointing to root causes, indeed point to the root causes of the bugs we evaluated.”
We define an ideal failure sketch to be one that: 1) contains only statements that have data and/or control dependencies to the statement where the failure occurs; 2) shows the failure predicting events that have the highest positive correlation with the occurrence of failures.
To be usable in practice, a failure sketching tool needs to provide a combination of high accuracy in pinpointing root causes, and low overhead. The author’s design and implementation achieves these goals:
We evaluated our Gist prototype using 11 failures from 7 different programs including Apache, SQLite, and Memcached. The Gist prototype managed to automatically build failure sketches with an average accuracy of 96% for all the failures while incurring an average performance overhead of 3.74%. On average, Gist incurs 166× less runtime performance overhead than a state-of-the art record/replay system.
Beyond just low overhead, another nice aspect of the hardware support is that it is not necessary to perturb the software being diagnosed (I’m sure we’ve all experienced the dreaded print statement that ‘inexplicably’ changes the runtime behaviour of a program so that the bug no longer occurs…):
To reduce overhead, existing root cause diagnosis techniques rely on special runtime and hardware support that is not readily available. Solutions that perturb the actual behavior of production runs nondeterministically may mask the bug frequently but not always, and thus make it harder to diagnose the root cause and remove the potential for (even occasional) failure.
System Overview
The authors’ system for building failure sketches is called Gist. It has three main components, a static analyzer and failure computation engine, and a runtime for tracking production runs. The Gist workflow is as follows:
- Gist takes as input a program (source code and binary) and a failure report – e.g. a stack trace. (With a system that automatically collects error and exception information, it’s easy to see how this first step could be automated).
- Gist then performs a static analysis of the program code in order to determine what the possible causes might be:
Gist computes a backward slice by computing the set of program statements that potentially affect the statement where the failure occurs. Gist uses an interprocedural, path-insensitive and flow-sensitive backward slicing algorithm.
- Gist now instructs its runtime (embedded in user endpoints in the datacenter) to instrument the program and gather additional traces. The purpose of this tracing is to refine the slice and get a more accurate view of the information that will be pertinent in determining the root cause.
Gist then uses these traces to refine the slice: refinement removes from the slice the statements that don’t get executed during the executions that Gist monitors, and it adds to the slice statements that were not identified as being part of the slice initially. Refinement also determines the inter-thread execution order of statements accessing shared variables and the values that the program computes. Refinement is done using hardware watchpoints for data flow and Intel Processor Trace (Intel PT) for control flow.
- The failure sketch engine gathers information from failing and successful runs.
- Gist determines the difference between the failing and successful runs, and produces a failure sketch for the developer to use.
Gist incurs low overhead, so it can be kept always-on and does not need to resort to sampling an execution, thus avoiding missing information that can increase root cause diagnosis latency. Gist operates iteratively: the instrumentation and refinement continues as long as developers see fit, continuously improving the accuracy of failure sketches. Gist generates a failure sketch after a first failure using static slicing. Our evaluation shows that, in some cases, this initial sketch is sufficient for root cause diagnosis, whereas in other cases refinement is necessary.
Use of Hardware Support
As described earlier, Intel PT can be programmed to trace only user-level code, and restricted to certain address-spaces. The authors wrote a custom kernel driver so that Gist can control it at runtime. Gist uses hardware support for both control flow and data flow tracking.
At the high level, Gist identifies all entry points and exit points to each statement and starts and stops control-flow tracking at each entry point and at each exit point, respectively. Tracing is started to capture control flow if the statements in the static slice get executed, and is stopped once those statements complete execution. We use postdominator analysis to optimize out unnecessary tracking.
For data flow, Gist uses the hardware watchpoints present in modern processors (e.g. x86 has 4). They enable tracking the values written to and read from memory locations with low overhead.
First, Gist tracks the total order ofmemory accesses that it monitors to increase the accuracy of the control flow shown in the failure sketch. Tracking the total order is important mainly for shared memory accesses from different threads, for which Intel PT does not provide order information. Gist uses this order information in failure sketches to help developers reason about concurrency bugs. Second, while tracking data flow, Gist discovers statements that access the data items in the monitored portion of the slice that were missing from that portion of the slice. Such statements exist because Gist’s static slicing does not use alias analysis (due to alias analysis’ inaccuracy) for determining all statements that can access a given data item.
Root Cause Identification
Gist defines failure predictors for both sequential and multithreaded programs. For sequential programs, Gist uses branches taken and data values computed as failure predictors. For multithreaded programs, Gist uses the same predicates it uses for sequential programs, as well as special combinations of memory accesses that portend concurrency failures.
Gist logs the order of accesses and updates to shared variables, and searches for the failure-predicting patterns in those logs.
Once Gist has gathered failure predictors from failing and successful runs, it uses a statistical analysis to determine the correlation of these predictors with the failures. Gist computes the precision P (how many runs fail among those that are predicted to fail by the predictor?), and the recall R (how many runs are predicted to fail by the predictor among those that fail?). Gist then ranks all the events by their F-measure, which is the weighted harmonic mean of their precision and recall to determine the best failure predictor.
Failure sketches present the developer with the highest-ranked failure predictors for each type of predictor.
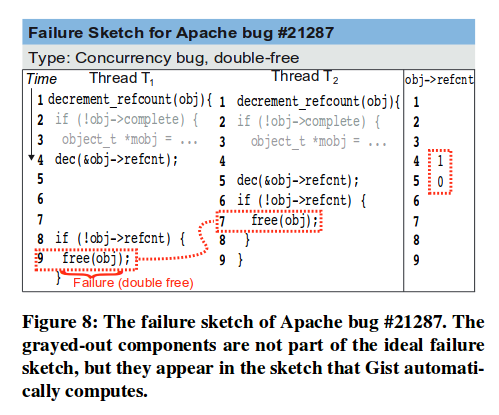
An example Failure Sketch
The State of the Art
The paper includes an extensive related work section: “In this section, we review a variety of techniques that have been developed to date to understand the root causes of failures and to help developers with debugging.” It’s an impressive collection of work from which you can only conclude that if your debugging technique still primarily consists of inserting print statuments then you are some way behind the state of the art…

2 thoughts on “Failure Sketching: A Technique for Automated Root Cause Diagnosis of In-Production Failures”
Comments are closed.