Quantifying Isolation Anomalies – Fekete et al. 2009
Before we get into today’s content, for those of you that can be in London for the week of the 14th September the GOTO London conference will be taking place with curated themes from Adrian Cockcroft discussing how we can build systems that are agile, lean, and rugged. Ines Sombra (Fastly and Papers we Love, San Francisco) and I will be giving an evening keynote “Agile, Lean, Rugged: The Paper Edition” with a few paper selections related to the conference themes. Discount code adrcol50. Hope to see you there!
Earlier this week we looked at Probabilistically Bounded Staleness and the probability of stale reads under eventual consistency. But of course anything less than serializability can lead to anomalies – which means that your favourite RDBMS isn’t immune either – especially under default isolation levels.
The “gold standard” for concurrency control is to provide serializability, which has the valuable feature that any integrity constraint will continue to hold in the database, provided it is true initially, and each transaction is coded to preserve the constraint when run alone. Unfortunately, the algorithms implemented in most platforms that ensure serializable execution can have detrimental impact on performance in cases of contention. These algorithms involve strict two-phase locking (2PL), with locks, in shared or exclusive (or other) modes being taken at various granularities covering data items as well as on indices, and these locks are held till the end of the transaction.
In practice, weaker isolation levels such as Read Committed are often used – and this is the default setting. We end up trading off performance and correctness…
It is widely described as allowing the application developer to take advantage of domain knowledge which means that their particular code will work correctly with low isolation; however, there is no set of principles or guidelines to determine whether this is so for given code. [17] reported examples of deployed applications using SI which produced non-serializable executions. Thus in practice, what most developers actually see is a trade-off between performance and correctness. Running with strong isolation such as serializability will protect data integrity but limit throughput under contention; conversely, weak isolation offers better performance but with the risk that data might be corrupted by undesirable interleavings between concurrent activities.
(SI here is Snapshot Isolation, Oracle’s ‘serializable’).
The ANSI SQL standard has four isolation levels, Serializable, Repeatable Read, Read Committed, and Read Uncommited.
Each level is “defined” to rule out some particular anomalous behaviors which the lower levels allow.
The standard does not however mandate particular implementation approaches, and there are some well-known flaws in the way the behaviors of each level are specified[3]. If we assume that the well-known locking-based concurrency control algorithms are used, then the hierarchy is valid.
When the well-know locking based concurrency control algorithms aren’t used, things aren’t quite so straightforward:
However, as we saw, many platforms implement multiversion algorithms for concurrency control. Snapshot Isolation is treated as a strong algorithm (in particular, it prevents all the anomalies described in the ANSI standard as shown by [3], although it does allow an anomaly called Write-Skew). It is generally assumed that the multiversion Read Committed algorithm is weaker than SI, because it does allow anomalies like Inconsistent Reads and Phantoms. Indeed, several platforms use SI when an application is declared to be Serializable, and they use the multiversion form of Read Committed when the application requests the lower isolation level. Despite this, [3] shows that SI is not strictly less permissive than RC MV.
This means that there are pathological cases where you can see more anomalies under SI than under Read Committed.
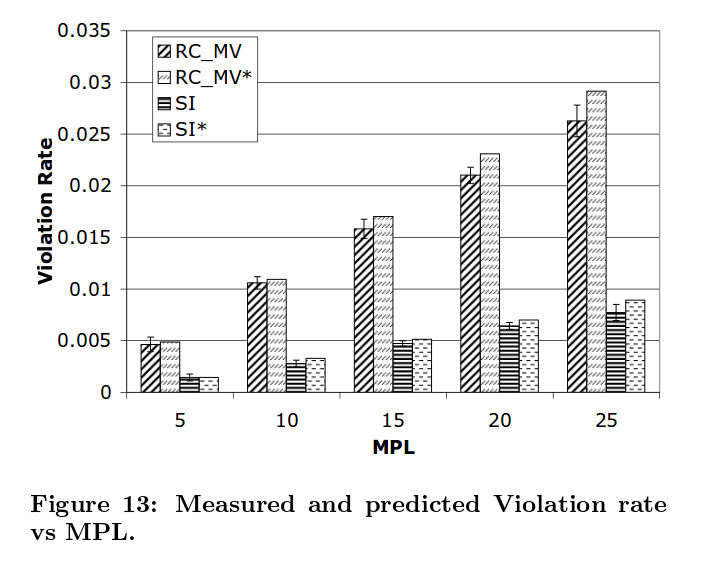
A microbenchmark is constructed based around two tables A and B, and three transactions changeA, changeB, and changeAB that update tables A, B, and both A and B respectively. A predictive model is also built for both SI and Read Committed isolation levels to predict how many integrity violations will occur under different transaction mixes.
In Figure 1 we show an example of the use of our microbenchmark. We have measured the rate of violations of the integrity constraint at different isolation levels, on a particular platform, and for a range of configurations which vary only in the MPL (the number of concurrent clients that are submitting transactions).

The predictions show the correct trend, with reasonable accuracy as shown below:
 .
.
The work shows that it is possible to quantify the number of predicted integrity violations, given an understanding of the transaction mix, thus helping developers figure out what they’re giving up when trading correctness for performance.
Another direction is to extend our predictive model from the particular transactions in the microbenchmark, to deal with arbitrary mixes of application code, in particular so it can be applied to more realistic programs. This will be based on a static dependency graph which shows which pairs of transactions deal with the same item, but it will also need careful analysis of which interleavings actually cause violation of integrity constraints.
(Of course, this statement predates the work by Bailis, Fekete, et al. on I-Confluence which did indeed go on to investigate which interleavings cause violation of integrity constraints).

3 thoughts on “Quantifying Isolation Anomalies”
Comments are closed.