Asynchronous Distributed Snapshots for Distributed Dataflows – Carbone et al. 2015
The team behind Apache Flink and data Artisans are a smart group of folks. Their recent blog post on High-throughput, low-latency, and exactly-once stream processing with Apache Flink is well worth reading and has a good description of the evolution of streaming architectures, the desired characteristics of a fault-tolerant solution, and why working with unbounded data sets makes things harder… From the overview in that blog post, you’ll find a link to today’s paper choice which describes the Asynchronous Barrier Snapshotting (ABS) algorithm used by Apache Flink.
Fault tolerance is of paramount importance in [dataflow processing] systems, as failures cannot be afforded in most real-world use cases. Currently known approaches that guarantee exactly-once semantics on stateful processing systems rely on global, consistent snapshots of the execution state. However, there are two main drawbacks that make their application inefficient for real-time stream processing. Synchronous snapshotting techniques stop the overall execution of a distributed computation in order to obtain a consistent view of the overall state. Furthermore, to our knowledge all of the existing algorithms for distributed snapshots include records that are in transit in channels or unprocessed messages throughout the execution graph as part of the snapshotted state.Most often this includes state that is larger than required.
Synchronous snapshotting is used for example by Naiad. The overall computation of the execution graph is halted, a snapshot is taken, and then execution resumes. Unsurprisingly, the more frequently you snapshot, the higher the overhead. The ‘snapshot pauses’ can also interfere with low-latency delivery. Alternative approaches exist based on the Chandy-Lamport algorithm:
This is achieved by distributing markers throughout the execution graph that trigger the persistence of operator and channel state. This approach though still suffers from additional space requirements due to the need of an upstream backup and as a result higher recovery times caused by the reprocessing of backup records.
The solution employed by Apache Flink, Asynchronous Barrier Snapshotting, builds on the Chandy-Lamport approach but no backup logging in the case of acyclic graphs, and only selective logging for cyclic ones.
As per the Google Dataflow manifesto, the core data abstraction of Flink streaming is unbounded data streams:
Apache Flink is architectured around a generic runtime engine uniformly processing both batch and streaming jobs composed of stateful interconnected tasks. Analytics jobs in Flink are compiled into directed graphs of tasks. Data elements are fetched from external sources and routed through the task graph in a pipelined fashion. Tasks are continuously manipulating their internal state based on the received inputs and are generating new outputs…. The Apache Flink API for stream processing allows
the composition of complex streaming analytics jobs by exposing unbounded partitioned data streams (partially ordered sequences of records) as its core data abstraction, called DataStreams.
An execution graph G = (T,E), where T represents the set of tasks and E the edges (data channels) connecting them. A global snapshot Gs = (Ts,Es) is a consistent set of all task and edge states (as with Chandy-Lamport, we need to consider in-flight messages along data channels).
It is feasible to do snapshots without persisting channel states when the execution is divided into stages. Stages divide the injected data streams and all associated computations into a series of possible executions where all prior inputs and generated outputs have been fully processed. The set of operator states at the end of a stage reflects the whole execution history, therefore, it can be solely used for a snapshot. The core idea behind our algorithm is to create identical snapshots with staged snapshotting while keeping a continuous data ingestion.
This is reminiscent of the discussion of window-based snapshotting in the Google Dataflow paper. Key here is that snapshot stages can be independent of any event and processing windows, the two are not tightly coupled.
In our approach, stages are emulated in a continuous dataflow execution by special barrier markers injected in the input data streams periodically that are pushed throughout the whole execution graph down to the sinks. Global snapshots are incrementally constructed as each task receives the barriers indicating execution stages.
The core ABS algorithm (ignoring cycles for the moment) works as follows:
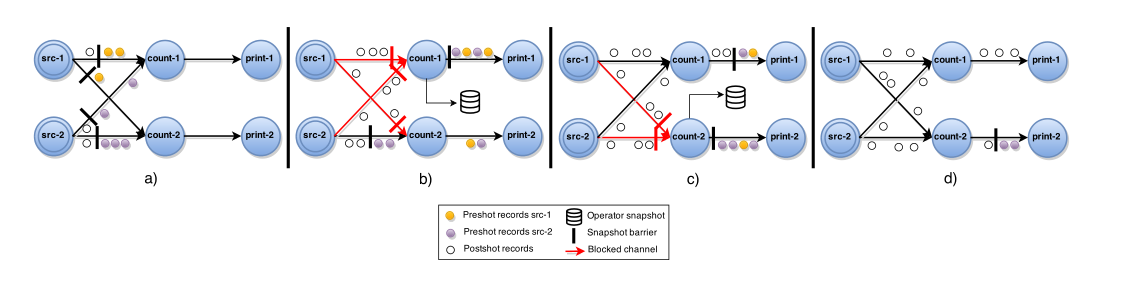
A central coordinator periodically injects stage barriers to all the sources. When a source receives a barrier it takes a snapshot of its current state, then broadcasts the barrier to all its outputs (Fig.2(a)). When a non-source task receives a barrier from one of its inputs, it blocks that input until it receives a barrier from all inputs (Fig.2(b)).When barriers have been received from all the inputs, the task takes a snapshot of its current state and broadcasts the barrier to its outputs (Fig.2(c)). Then, the task unblocks its input channels to continue its computation (Fig.2(d)). The complete global snapshot Gs = (Ts, Es) will consist solely of all operator states Ts where Es = ∅.
In the presence of directed cycles, this base algorithm results in a deadlock. Cycles are addressed as follows:
First, we identify back-edges L on loops in the execution graph by static analysis. From control flow graph theory a back-edge in a directed graph is an edge that points to a vertex that has already been visited during a depth-first search. The execution graph G(T,E \ L) is a DAG containing all tasks in the topology. From the perspective of this DAG the algorithm operates as before, nevertheless, we additionally apply downstream backup of records received from identified back-edges over the duration of a snapshot. This is achieved by each task t that is a consumer of back edges Lt ⊆ It, Lt creating a backup log of all records received from Lt from the moment it forwards barriers until receiving them back from Lt . Barriers push all records in transit within loops into the downstream logs, so they are included once in the consistent snapshot.
Tasks with back-edge inputs create a local copy of their state once all their regular channels have delivered barriers. From this point on, they log all records delivered from their back-edges until they receive barriers from them too.
The algorithm is implemented in Apache Flink:
We contributed the implementation of the ABS algorithm to Apache Flink in order to provide exactly-once processing semantics for the streaming runtime. In our current implementation blocked channels store all incoming records on disk instead of keeping them in memory to increase scalability. While this technique ensures robustness, it increases the runtime impact of the ABS algorithm… Snapshot coordination is implemented as an actor process on the job manager that keeps a global state for an execution graph of a single job. The coordinator periodically injects stage barriers to all sources of the execution graph. Upon reconfiguration, the last globally snapshotted state is restored in the operators from a distributed in-memory persistent storage.

One thought on “Asynchronous Distributed Snapshots for Distributed Dataflows”
Comments are closed.