Eventually Consistent Transactions – Burckhardt et al. 2012
There’s another ECOOP’15 paper I’d like to cover this week – Burckhardt et al.’s “Global Sequence Protocol.” But that paper builds on the notion of Cloud Types (similar in spirit to CRDTs, and not something I’ve personally come across before), which in turn builds on work on Eventually Consistent Transactions using revision diagrams. We’ll look at Eventually Consistent Transactions today, Cloud Types tomorrow, and then get to the Global Sequence Protocol paper on Wednesday.
In ‘Eventually Consistent Transactions,’ Burckhardt et al. give us a model for understanding what an eventually consistent transaction is (and insight into how it differs from sequentially consistent), an approach to creating eventually consistent systems based on revision diagrams, and some examples of constructing such systems.
What is an Eventually Consistent Transaction?
Eventually consistent systems guarantee that all updates are eventually delivered to all replicas, and that they are applied in a consistent order. Eventual consistency is popular with system builders. One reason is that it allows temporarily disconnected replicas to remain fully available to clients. This is particularly useful for implementing clients on mobile devices. Another reason is that it does not require updates to be immediately performed on all server replicas, thus improving scalability. In more theoretical terms, the benefit of eventual consistency can be understood as its ability to delay consensus.
Eventually consistent transactions are not serializable, but they do uphold traditional atomicity and isolation guarantees. They also offer a couple of useful properties that traditional transactions do not:
- transactions cannot fail and never roll back
- all code, even long-running tasks, can run inside transactions without compromising performance
The definition of eventual transactions in the paper is based on a model of Query-Update interfaces and automaton. A Query Update interface is a triple (Q,U,V) where Q is a set of query operations, U is a set of update operations, and V is the set of values returned by queries. A query-update automaton (QUA) provides the state model behind a query-update interface: for an interface (Q,U,V), a QUA adds (S,s0) where S is the set of permissible states, and s0 is the initial state. Each query in Q is then interpreted as a function from S → V, and each update in U as a function from S → S.
QUAs can naturally support abstract data types (e.g. collections, or even entire documents) that offer higher-level operations (queries and updates) beyond just loads and stores. Such data types are often important when programming against a weak consistency model [18], since they can ensure that the data representation remains intact when handling concurrent and potentially conflicting updates.
There are two important considerations compared to abstract data types:
- there is a strict separation between query and update operations – you can’t have an update that also returns a value.
- all updates are total functions, therefore it is not possible for an update to fail. You may of course define an update function that does not change the state of the system if its preconditions are not met.
For instance, in our formalization, we would not allow a classic stack abstract data type with a pop operation for two reasons, (1) pop both removes the top element of the stack and returns it, so it is neither an update nor a query, and (2) pop is not total, i.e. it can not be applied to the empty stack. This restriction is crucial to enable eventual consistency, where the sequencing and application of updates may be delayed, and updates may thus be applied to a different state than the one in which they were originally issued by the program.
The model assumes that every operation happens within a transaction. Therefore instead of explicit begin and end transaction events, only ‘yield’ is defined. Yield punctuates a stream of operations (queries and updates) to demarcate them into transactions.
A set of clients interacting with a shared QUA can have their interactions defined in terms of the updates u ∈ U issued by the program, the pairs (q,v) where q ∈ Q and v ∈ V representing the queries issued by clients and the responses returned, and finally the yield operations issued by the client programs.
A history H maps a set of clients c ∈ C to a sequence of operations (query pairs and updates) – yields are not considered part of the history. Based on this history, a set of rules are given for sequential consistency …
Sequential consistency fundamentally limits availability in the presence of network partitions. The reason is that any query issued by some transaction t must see the effect of all updates that occur in transactions that are globally ordered before t, even if on a remote device. Thus we cannot conclusively commit transactions in the presence of network partitions.
And now we can see the fundamental difference between sequential and eventual consistency:
Eventual consistency relaxes sequential consistency by allowing queries in a transaction t to see only a subset of all transactions that are globally ordered before t. It does so by distinguishing between a visibility order (a partial order that defines what updates are visible to a query), and an arbitration order (a partial order that determines the relative order of updates).
Given these two partial orders, we are given the set of rules for eventual consistency.
The reason why eventual consistency can tolerate temporary network partitions is that the arbitration order can be constructed incrementally, i.e. may remain only partially determined for some time after a transaction commits. This allows conflicting updates to be committed even in the presence of network partitions.
Techniques used by implementors to achieve a visibility ordering include general causally ordered broadcast and pairwise anti-entropy. The arbitration ordering is often determined by logical or actual timestamps, or by making operations commutative so that order does not matter.
We show in the next section (Section 3) how to arbitrate updateswithout using timestamps or requiring commutativity, a feature that sets our work apart. We prefer to not use timestamps because they exhibit the write stabilization problem [20], i.e. the inability to finalize the effect of updates while older updates may still linger in disconnected network partitions.
Introducing Revision Diagrams
Revision diagrams show an extended history not only of the queries, updates, and transactions by each client, but also of the forking and joining of revisions, which are logical replicas of the state. A client works with one revision at a time, and can perform operations (queries and updates) on it. Since different clients work with different revisions, clients can perform both queries and updates concurrently and in isolation (i.e. without creating race conditions). Reconciliation happens during join operations.When a revision joins another revision, it replays all the updates performed in the joined revision at the join point. After a revision is joined, no more operations can be performed on it (i.e. clients may need to fork new revisions to keep enough revisions available).
Revision diagrams (see below) can have five different types of vertices: the special start vertex, a fork vertex, a join vertex, an update vertex, and a query vertex. Vertices are joined by edges which may be a successor edge, a join edge, or a fork edge.
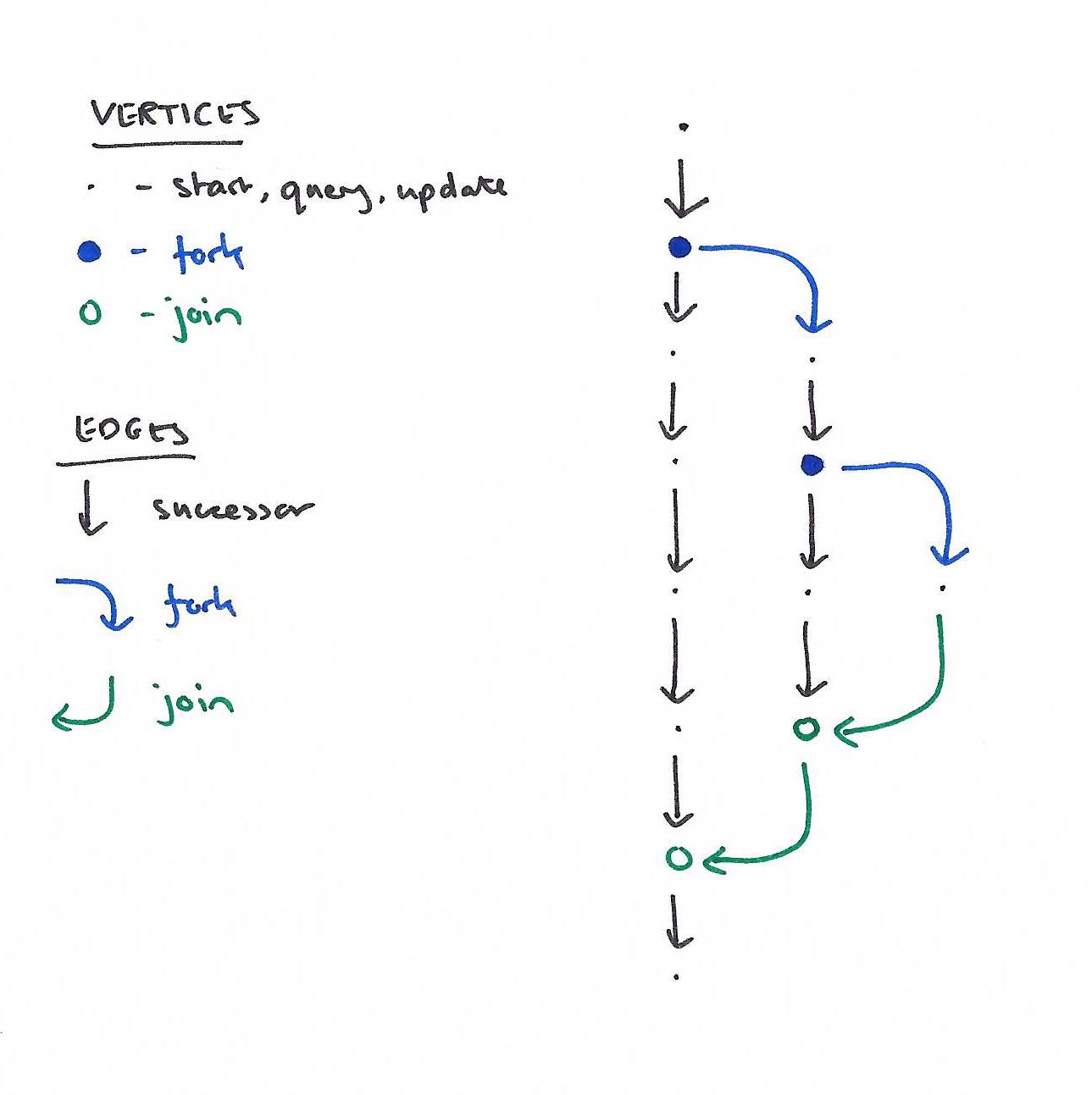
To construct a revision diagram apply a possibly infinite sequence of the following rules starting with an initial start vertex:
- Query: choose some terminal vertex t, create a new query vertex x, and add a successor edge from t → x.
- Update: choose some terminal vertex t, create a new update vertex x, and add a successor edge from t → x.
- Fork: choose some terminal vertex t, create a new fork vertex x and add a successor edge from t → x. Create a new start vertex y for the new revision, and add a fork edge from x → y.
- Join: choose two terminals t1 and t2 satisfying the join condition. Create a new join vertex x, and add a successor edge from t1 → x, and a join edge from t2 → x.
The join condition expresses that the terminal t1 (the “joiner”) must be reachable from the fork vertex that started the revision that contains t2 (the “joinee”). This condition makes revision diagrams more restricted than general task graphs. The join condition has some important, not immediately obvious consequences. For example, it implies that revision diagrams are always semilattices…
Revision diagrams can be used to determine the results of queries…
We now proceed to explain how to determine the results of a query in a revision diagram. The basic idea is to (1) return a result that is consistent with applying all the updates along the root path, and (2) if there are join vertices along that path, they summarize the effect of all updates by the joined revision.
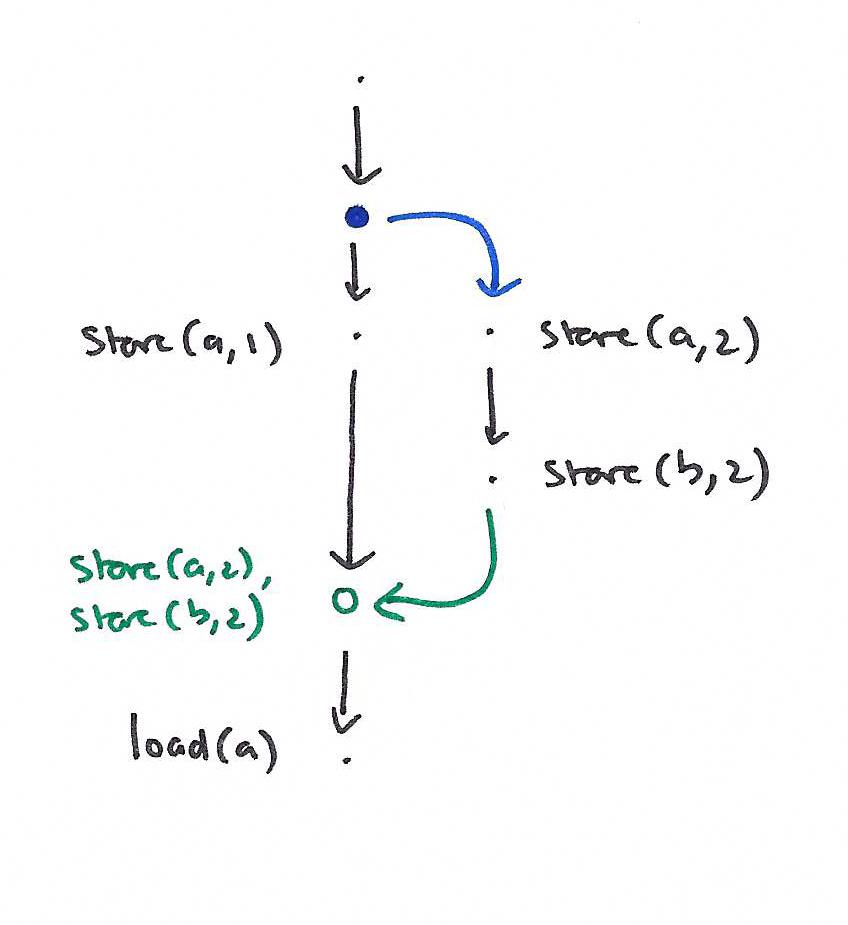
Histories can be related to revision diagrams by associating each query event with a query vertex, and each update event with an update vertex.
The intention is to validate the query results in the history using the path results, and to keep transactions atomic and isolated by ensuring that their events form contiguous sequences within a revision.
The paper contains the formal set of rules for a revision diagram to be considered a faithful ‘witness’ of a history. Given this, we have a model for eventual consistency based on interpreting revision diagrams:
Let H be a history. If there exists a witness diagram for H such that no committed events are neglected, then H is eventually consistent.
(A ‘neglected event’ is a terminal that never joins back onto the main branch, so the ‘no committed events’ condition is a liveness condition).
Note that this theorem gives us a solid basis for implementing eventually consistent transactions: an implementation can be based on dynamically constructing a witness revision diagram and as a consequence guarantee eventual consistent transactions.Moreover, as we will see in Section 4, implementations do not need to actually construct such witness diagrams at runtime but can rely on efficient state-based implementations.
Examples
For an implementation based on the above ideas, it is sufficient to define a fork-join QUA (FJ-QUA). This is a QUA as we saw before, with state by convention represented by Σ and with the addition of a fork function f : Σ → Σ X Σ, and a join function j: Σ X Σ → Σ.
If we have a fork-join QUA, we can simply associate a Σ-state with each revision, and then perform all queries and updates locally on that state, without communicating with other revisions. The join function of the FJ-QUA, if implemented correctly, guarantees that all updates are applied at the join time…. Since we can store a log of updates inside Σ, it is always possible to provide an FJ-QUA for any QUA
Examples are given of how to create an eventually consistent system with a single sychronous server and a set of clients, and also one that uses a server pool. See the full paper for the details of their FJ-QUAs.

One thought on “Eventually Consistent Transactions”
Comments are closed.