Pregel: A System for Large-Scale Graph Processing – Malewicz et al. (Google) 2010
“Many practical computing problems concern large graphs.”
Yesterday we looked at some of the models for understanding networks and graphs. Today’s paper focuses on processing of graphs, especially the efficient processing of large graphs where large can mean billions of vertices and trillions of edges. Pregel is the system at Google that powers PageRank, which makes it a very interesting system to study. It is also the inspiration for Apache Giraph, which Facebook use to analyze their social graph.
There are single machine-sized graph processing problems, and then there are distributed graph processing problems. You probably don’t want to be using a distributed graph processing platform to solve a problem that would fit on one machine (See Musketeer), but if you really do have a large graph, then…
Efficient processing of large graphs is challenging. Graph algorithms often exhibit poor locality of memory access, very little work per vertex, and a changing degree of parallelism over the course of execution. Distribution over many machines exacerbates the locality issue, and increases the probability that a machine will fail during computation.
Pregel is Google’s scalable and fault-tolerant platform with an API that is sufficiently flexible to express arbitrary graph algorithms. Within Google, even as of 2010:
Dozens of Pregel applications have been deployed, and many more are being designed, implemented, and tuned. The users report that once they switch to the “think like a vertex” mode of programming, the API is intuitive, flexible, and easy to use.
Google already had a distributed computing framework though, based on MapReduce. So why not just use that?
Pregel keeps vertices and edges on the machine that performs computation, and uses network transfers only for messages. MapReduce, however, is essentially functional, so expressing a graph algorithm as a chained MapReduce requires passing the entire state of the graph from one stage to the next — in general requiring much more communication and associated serialization overhead. In addition, the need to coordinate the steps of a chained MapReduce adds programming complexity that is avoided by Pregel’s iteration over supersteps.
Let’s first take a look at Pregel’s programming model, and then we can dive into a few implementation details.
The Pregel Programming Model
The high-level organization of Pregel programs is inspired by Valiant’s Bulk Synchronous Parallel model. Pregel computations consist of a sequence of iterations, called supersteps. During a superstep the framework invokes a user-defined function for each vertex, conceptually in parallel. The function specifies behavior at a single vertex V and a single superstep S. It can read messages sent to V in superstep S − 1, send messages to other vertices that will be received at superstep S + 1, and modify the state of V and its outgoing edges. Messages are typically sent along outgoing edges, but a message may be sent to any vertex whose identifier is known.
The synchronicity makes it easier to reason about program semantics, and ensures that Pregel programs are inherently free of deadlocks and data races.
Within each superstep the vertices compute in parallel, each executing the same user-defined function that expresses the logic of a given algorithm. A vertex can modify its state or that of its outgoing edges, receive messages sent to it in the previous superstep, send messages to other vertices (to be received in the next superstep), or even mutate the topology of the graph. Edges are not first-class citizens in this model, having no associated computation.
A Pregel program terminates when every vertex votes to halt. A vertex starts in the active state. It deactivates itself by voting to halt, after which time the Pregel framework will not execute that vertex in subsequent supersteps unless it receives a message. If reactivated by a message, a vertex must explicitly deactivate itself again. Communication is via message passing:
We chose a pure message passing model, omitting remote reads and other ways of emulating shared memory, for two reasons. First, message passing is sufficiently expressive that there is no need for remote reads. We have not found any graph algorithms for which message passing is insufficient. Second, this choice is better for performance. In a cluster environment, reading a value from a remote machine incurs high latency that can’t easily be hidden. Our message passing model allows us to amortize latency by delivering messages asynchronously in batches.
Of course, the second reason does not apply if you are using RDMA. So it would be very interesting to see what a graph processing platform over RDMA might be able to do, similar in spirit to FaRM’s key-value store over RDMA.
The sequence below shows the four supersteps needed to complete a maximum value calculation for a graph with four nodes. In each step, each vertex reads any incoming messages and sets its value to the maximum of its current value and those sent to it. It then sends this maximum value out along all of its edges. If the maximum value at a node does not change during a superstep, the node then votes to halt.
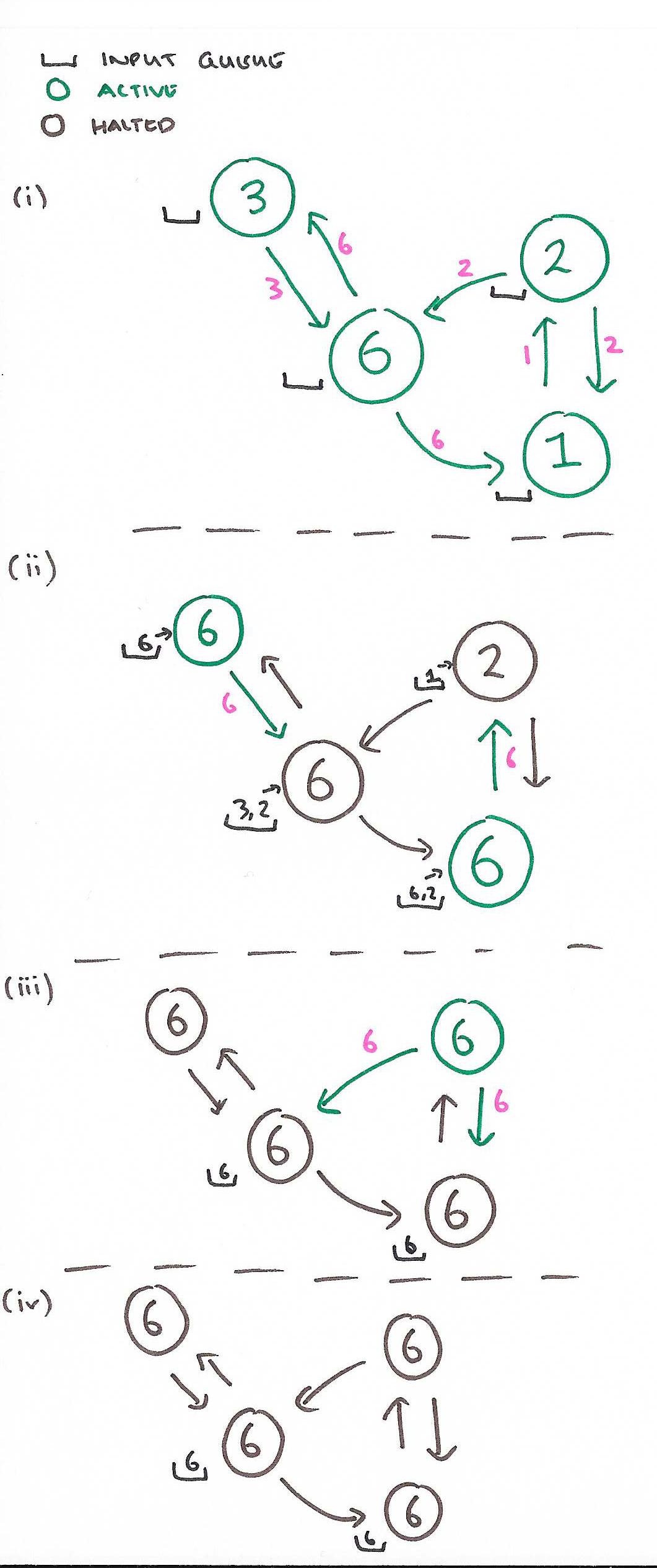
Vertices are addressed by (string) ids. If the destination vertex of a message does not exist, a user-defined handler is executed. This can manipulate the graph by e.g. creating the missing vertex, or removing the dangling edge from its source vertex.
Combiners are optional user provided functions that can combine multiple messages intended for a vertex into one – thus reducing the number of messages that must be transmitted and buffered. For the maximum value example, a combiner could collapse multiple messages into a single one containing the maximum for example.
There are no guarantees about which (if any) messages are combined, the groupings presented to the combiner, or the order of combining, so combiners should only be enabled for commutative and associative operations. For some algorithms, such as single-source shortest paths, we have observed more than a fourfold reduction in message traffic by using combiners.
Aggregators enable global information exchange:
Each vertex can provide a value to an aggregator in superstep S, the system combines those values using a reduction operator, and the resulting value is made available to all vertices in superstep S + 1.
Aggregators are quite flexible – for example the output of an aggregator can be used to control conditional branching in vertex compute functions, or a min or max aggregator applied to the vertex id can be used to select a vertex to play a distinguished role in an algorithm.
Finally, a vertex compute function can issue request to add or remove vertices or edges:
Some graph algorithms need to change the graph’s topology. A clustering algorithm, for example, might replace each cluster with a single vertex, and a minimum spanning tree algorithm might remove all but the tree edges.
Mutations become effective in the superstep after the request were issued. Mutations are always applied in the following order: edge removal, vertex removal (which implicitly removes all of its out edges), vertex addition, edge addition. Any conflicts are resolved by user-defined handlers.
The Pregel Implementation
Pregel is designed to run on Google’s cluster architecture.
The Pregel library divides a graph into partitions, each consisting of a set of vertices and all of those vertices’ outgoing edges. Assignment of a vertex to a partition depends solely on the vertex ID, which implies it is possible to know which partition a given vertex belongs to even if the vertex is owned by a different machine, or even if the vertex does not yet exist. The default partitioning function is just hash(ID) mod N, where N is the number of partitions, but users can replace it.
Multiple copies of a user program begin executing on a cluster of machines. One of these as as the master and is responsible for coordinating worker activity. Workers use a name service to discover the master’s location and register with it. Then,…
The master determines how many partitions the graph will have, and assigns one or more partitions to each worker machine. The number may be controlled by the user. Having more than one partition per worker allows parallelism among the partitions and better load balancing, and will usually improve performance.
After this point, parallel loading of the input graph occurs, with the master assigning portions of the input to each worker.
The division of inputs is orthogonal to the partitioning of the graph itself, and is typically based on file boundaries. If a worker loads a vertex that be- longs to that worker’s section of the graph, the appropriate data structures are immediately updated. Otherwise the worker enqueues a message to the remote peer that owns the vertex. After the input has finished loading, all vertices are marked as active.
The master then instructs each worker to perform a superstep. A worker uses one thread for each partition it is responsible for, looping through the active vertices in each partition. Messages are sent asynchronously, but are delivered before the end of the superstep. The worker then tells the master how many vertices will be active in the next superstep. The master repeats this process so long as any vertices are active, or any messages are in transit.
Fault tolerance is achieved through checkpointing. At the beginning of a superstep, the master instructs the workers to save the state of their partitions to persistent storage, including vertex values, edge values, and incoming messages; the master separately saves the aggregator values.
A simple heartbeating mechanism is used to detect failures.
When one or more workers fail, the current state of the partitions assigned to these workers is lost. The master reassigns graph partitions to the currently available set of workers, and they all reload their partition state from the most recent available checkpoint at the beginning of a superstep S.
The frequency of checkpointing is chosen to balance checkpoint cost against expected recovery cost using a mean time to failure model.
Example Applications
The paper gives examples of PageRank, single-source shortest path, bipartite maching, and semi-clustering algorithms implemented using Pregel’s programming model. See the full paper (link at the top of the post as always) for details.
Running shortest paths for a graph with a billion vertices and over 127 billion edges, using 800 worker tasks on 300 multicore machines, took ‘a little over 10 minutes.’

13 thoughts on “Pregel: A System for Large-Scale Graph Processing”
Comments are closed.