FAWN: A Fast Array of Wimpy Nodes – Andersen et al. 2009
A few days ago we looked at FaRM (Fast Remote Memory), which used RDMA to match network speed with the speed of CPUs and got some very impressive results in terms of queries & transactions per second. But maybe there’s another way of addressing the imbalance – use less powerful CPUs! Which perhaps sounds a little odd at first, but starts to make sense when you consider a less-often quoted metric: queries / transactions per Joule.
High performance DRAM-based clusters, storing terabytes or petabytes of data, are both expensive and consume a surprising amount of power—two 2 GB DIMMs consume as much energy as a 1 TB disk. The power draw of these clusters is becoming an increasing fraction of their cost—up to 50% of the three-year total cost of owning a computer. The density of the datacenters that house them is in turn limited by their ability to supply and cool 10–20 kW of power per rack and up to 10–20 MW per datacenter. Future datacenters may require as much as 200 MW, and datacenters are being constructed today with dedicated electrical substations to feed them.
So queries per Joule (qpj) is a significant determinant of the overall cost of your solution.
These challenges necessitate the question: Can we build a cost-effective cluster for data-intensive workloads that uses less than a tenth of the power required by a conventional architecture, but that still meets the same capacity, availability, throughput, and latency requirements?
Andersen et al. set out to do just this with FAWN by building a fast array of “wimpy” (low-power AMD) nodes with SSDs, and a key value store on top designed to work well on this hardware platform. A 21-node FAWN cluster built with 500MHz CPUs (that were old even in 2009 when this paper was written) achieved 364 qpj, two orders of magnitude better than traditional disk-based clusters. Each node could support up to 1300 256 byte queries per second, enough to exploit nearly all the raw capacity of its attached SSDs. Total power consumption under 5W per node, compared to an Intel processor consuming about 83-90W under load.
The workload under study is a key-value store. For other big data workloads, it turns out that the network and disk may not be the bottleneck, it could still be the CPU! This suggests yet another way of addressing the imbalance – do lots of expensive serialization and deserialization! That wouldn’t be my top recommendation ;).
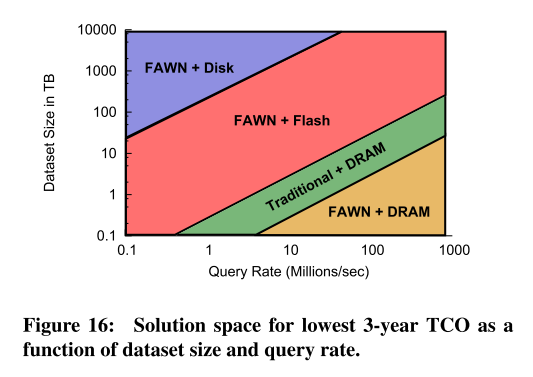
In their analysis, the authors consider dataset size and desired query rate, and provide recommendations as to the most cost-effective hardware+software platform to meet the targets. The result is shown in Figure 16 in the paper (reproduced below) – which is striking for showing that there is only a narrow band in which traditional approaches actually make sense for the small random access workloads (e.g. K-V store) studied!
Let’s take a look at FAWN’s hardware choices and rationale, and then dive into a few details of the K-V store built on top…
FAWN Hardware
FAWN couples low-power, efficient embedded CPUs with flash storage to provide efficient, fast, and cost-effective access to large, random-access data. Flash is significantly faster than disk, much cheaper than the equivalent amount of DRAM, and consumes less power than either.
CPU power consumption grows super-linearly with speed, therefore you can get a better price-performance point by moving back down the curve:
A FAWN cluster’s slower CPUs dedicate more transistors to basic operations. These CPUs execute significantly more instructions per Joule than their faster counterparts: multi-GHz superscalar quad-core processors can execute approximately 100 million instructions per Joule, assuming all cores are active and avoid stalls or mispredictions. Lower-frequency in-order CPUs, in contrast, can provide over 1 billion instructions per Joule—an order of magnitude more efficient while still running at 1/3rd the frequency.
Flash devices support fast random reads and efficient I/O, but with slower random writes.
Flash devices consume less than one Watt even under heavy load, whereas mechanical disks can consume over 10 W at load. Flash is over two orders of magnitude more efficient than mechanical disks in terms of queries/Joule.
The evaluation hardware consisted of single-core 500 MHz AMD Geode LX processors, with 256 MB DDR SDRAM operating at 400 MHz, and 100 Mbit/s Ethernet. Each node contained one 4 GB Sandisk Extreme IV CompactFlash device.
FAWN K-V Store
The FAWN data store is a log-structured key-value store.
FAWN-DS is designed specifically to perform well on flash storage and to operate within the constrained DRAM available on wimpy nodes: all writes to the datastore are sequential, and reads require a single random access. To provide this property, FAWN-DS maintains an in-DRAM hash table (Hash Index) that maps keys to an offset in the append-only Data Log on flash…. The key design choice in FAWN-KV is the use of a log- structured per-node datastore called FAWN-DS that provides high performance reads and writes using flash memory. This append-only data log provides the basis for replication and strong consistency using chain replication between nodes.
FAWN backends divide up the key space using consistent hashing, with each physical node responsible for multiple key ranges. Chain replication is used between nodes. Individual nodes use an in-memory hash index to map keys to values stored in the data log. To save space only a fragment of the key (the index bits) is kept in the index. This allows for a small probability that the key retrieved is not actually the one being sought (collision). In this situation hash-chaining is used continue searching the hash table.
With the 15-bit key fragment, only 1 in 32,768 retrievals from the flash will be incorrect and require fetching an additional record.
A smaller tier (about 1:80) of front-end nodes sits in front of the data storing back ends.
Each front-end node manages the VID membership list and queries for a large contiguous chunk of the key space (in other words, the circular key space is divided into pie-wedges, each owned by a front-end). A front-end receiving queries for keys outside of its range forwards the queries to the appropriate front-end node. This design either requires clients to be roughly aware of the front-end mapping, or doubles the traffic that front-ends must handle, but it permits front ends to cache values without a cache consistency protocol.
The front-end and back-end nodes implement a two-level caching hierarchy. Front-end nodes maintain a small high-speed query cache that reduces latency and helps managed hot spots. Back-ends implicitly cache recently accessed data in their file system buffer cache. About 1300 queries per second can be served from flash, but 85,000 queries per second from the buffer cache.

However, there’re two important aspects that authors haven’t mentioned. One is how to replay the data log when restarting, along with the checkpointing, the other is how to garbage-collect the obsolete data.