Machine Learning Classification over Encrypted Data – Bost et al. 2015
This is the 2nd of three papers we’ll be looking at this week from the NDSS ’15 conference held earlier this month in San Diego. When it comes to providing an informed critique of the security techniques applied in this paper, I’m out of my depth – but the paper can still be enjoyed by taking some of these details on faith and appreciating what has been achieved at a higher level. In particular, the authors show how homomorphic encryption building blocks can be combined to enable a classifier to classify an input vector, without revealing any details about the vector to the classifier, or the classifier to the vector! It’s an exciting result because the techniques used make homomorphic encryption practical (in space/time) for this use case.
Classifiers are an invaluable tool for many tasks today, such as medical or genomics predictions, spam detection, face recognition, and finance. Many of these applications handle sensitive data, so it is important that the data and the classifier remain private.
This paper is not concerned with the training phase – it assumes a trained model is available, and concentrates on the use of that model to perform classification tasks.
Consider the example of a medical study or a hospital having a model built out of the private medical profiles of some patients; the model is sensitive because it can leak information about the patients, and its usage has to be HIPAA compliant. A client wants to use the model to make a prediction about her health (e.g., if she is likely to contract a certain disease, or if she would be treated successfully at the hospital), but does not want to reveal her sensitive medical profile.
Only the classification needs to be privacy-preserving. The client should not learn anything about the model, and the server should not learn anything about the client’s input or the classification result.
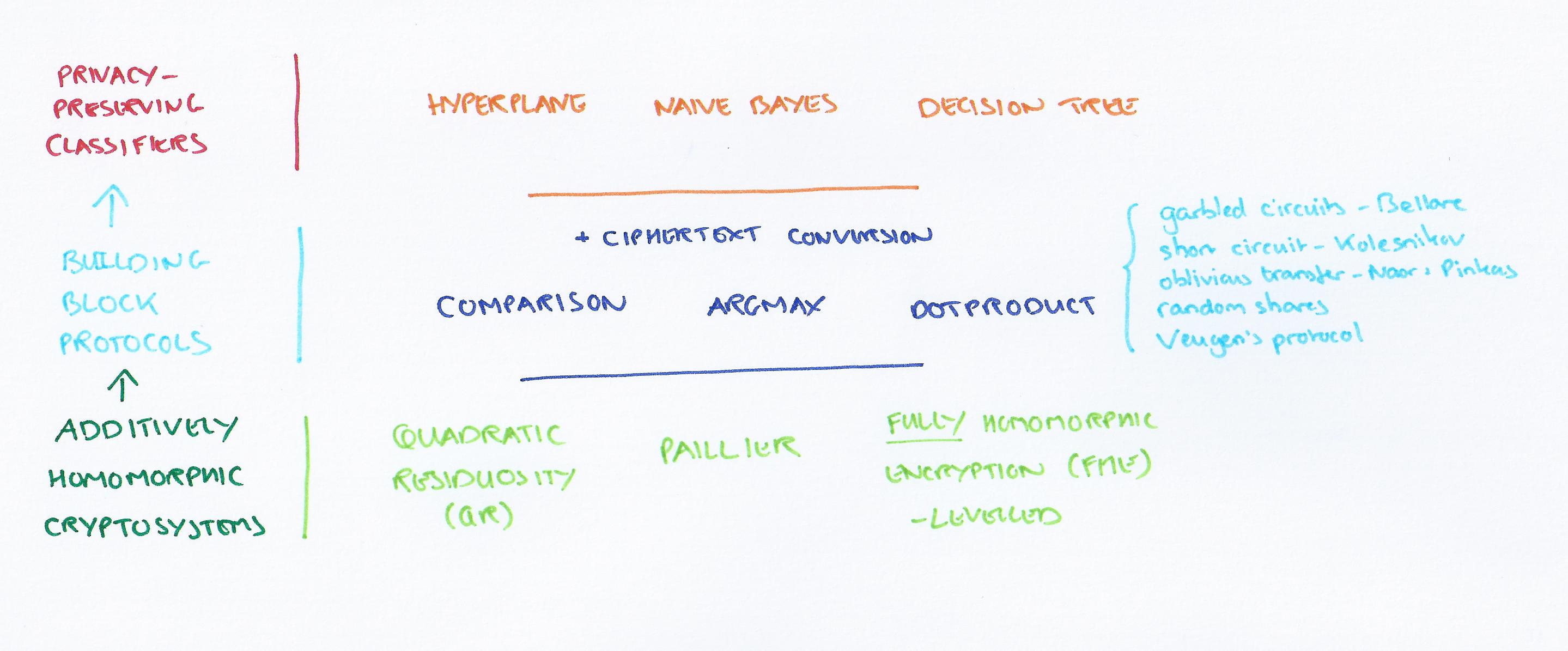
The authors create a general set of protocols for privacy preserving classifiers and show how these can be used for hyperplane decisions, naive bayes, and decision trees, as well as a solution that combines them using AdaBoost.
It is worth mentioning that our work on privacy-preserving classification is complementary to work on differential privacy in the machine learning community. Our work aims to hide each user’s input data to the classification phase, whereas differential privacy seeks to construct classifiers/models from sensitive user training data that leak a bounded amount of information about each individual in the training data set.
The essential approach is as follows: first the authors identify a set of common operations over encrypted data that underlie many classification protocols – these are comparison, argmax, and dotproduct. Then efficient building blocks are created for each of these, designed in such a way as to be composable both in functionality and security. Finally, the building blocks are used to create novel privacy preserving classifiers for three common classifier families.
Classifier building blocks (unencrypted)
The paper contains a quick breakdown of the main calculations required for each of the three chosen classifiers (useful if you need a refresher!). From this it is show that hyperplane decision classifiers fundamentally rely on argmax and inner product operations. To extend the classifier from 2 classes to k classes, the one vs all technique can be used. “This framework is general enough to cover many common algorithms such as support vector machines, logistic regression, and least squares.”
The naive bayes model depends on argmax and probability multiplications, and decision trees rely on walking a tree and deciding which branch to take at each node based on weightings.
Cryptographic building blocks
In this work, we use three additively homomorphic cryptosystems. A public-key encryption scheme HE is additively homomorphic if, given two encrypted messages HE.Enc(a) and HE.Enc(b), there exists a public-key operation⊕ such that HE.Enc(a)⊕ HE.Enc(b) is an encryption of a+b. We emphasize that these are homomorphic only for addition, which makes them efficient, unlike fully homomorphic encryption, which supports any function.
The three cryptosystems that are used are:
- Quadratic Residuosity (QR) – Goldwasser & Micali
- the Paillier cryptosytem
- a levelled fully homomorphic encryption (FHE) scheme, HELib.
The performance of FHE is very much dependent on the depth of multiplications in its circuit. In the classifier use case, the authors are able to ensure that the tree depth is kept relatively small, thus enabling use of a levelled FHE scheme…
a scheme that supports only an a priori fixed multiplicative depth instead of an arbitrary such depth. As long as this depth is small, such a scheme is much faster than a full FHE scheme.
The basic comparison building block is created on top of these. Because of the various ways it gets combined, it needs to be fully flexible in terms of which party gets the input, which party gets the output, and whether the input and output are encrypted or not.
And here comes one of those parts I just have to take on faith:
To compare unencrypted inputs, we use garbled circuits implemented with the state-of-the-art garbling scheme of Bellare et al., the short circuit for comparison of Kolesnikov et al. and a well-known oblivious transfer (OT) scheme due to Naor and Pinkas. Since most of our other building blocks expect inputs encrypted with homomorphic encryption, one also needs to convert from a garbled output to homomorphic encryption to enable composition. We can implement this easily using the random shares technique.
The comparison with encrypted inputs uses Veugen’s protocol….
we slightly modify Veugen’s protocol: it uses a comparison with unencrypted inputs protocol as a sub-procedure, and we replaced it with the comparison protocol we just described above.
(Normal service is now resumed…).
The approach to argmax is much easier to understand. If party A has a list of encrypted values encrypted with B’s secret key, we want B to learn the position in the list of the largest value, but nothing else. Before starting the comparisons, A shuffles the order of the items in the list (remembering the transformation used so that it can be reversed later).
Now, A and B compare the first two values using the comparison protocol. B learns the index, m, of the larger value, and tells A to compare the value at index m with the value at index 3 next. After iterating in this manner through all the k values, B determines the index m of the largest value.
Party A can then determine the argmax in the orginal unshuffled order by reversing the list transformation.
As described, B does not learn the ordering of the values due to the shuffle performed by A, but A does. To solve this a juggle is performed in which B can randomize the encryption of the maximum value so that A can’t tell which of the two original values it was.
The dot product operation relies on Paillier’s homomorphic property, but otherwise seems to be very straightforward.
To compose these building blocks it needs to be possible to convert ciphertexts from one encryption scheme to another while maintaining the underlying plaintexts. For switching between encryption schemes with the same plaintext size, the process is relatively straightforward:
The idea is for A to add a random noise r to the ciphertext using the homomorphic property of E1. Then B decrypts the resulting value with E1 (obtaining x+r∈M) and encrypts it with E2, sends the result to A which removes the randomness r using the homomorphic property of E2. Even though B was able to decrypt the value sent by A, B obtains x + r ∈M which hides x in an information-theoretic way (it is a one-time pad).
Some calculations require working with floating point numbers, whereas the encryption protocols all work with integers. The basic solution is simply to multiply all floating point numbers by a large constant (2^52).
Private classifiers
Given the building blocks, creating the hyperplane classifier is straightforward. The client first uses the secure dot product protocol, and then applies the argmax protocol to the encrypted dot products.
Naive bayes requires probability calculations, but Paillier works with integers, so the conversion described above is performed first (and the paper discusses issues relating to possible overflows etc.). From this point the server encrypts the values in the model using Paillier and gives the encrypted model to the client. The client uses Pailliers additive homomorphism to compute the posteriors, and then argmax to find the maximum.
Each node of a decision tree can be considered to be associated with a boolean variable with value 1 if on input x the right branch should be followed (x We construct a polynomial P that, on input all these boolean variables and the value of each class at a leaf node, outputs the class predicted for x. The idea is that P is a sum of terms, where each term (say t) corresponds to a path in the tree from root to a leaf node (say c). A term t evaluates to c iff x is classified along that path in T, else it evaluates to zero.
The client and server engage in the comparison protocol to compare each w (weight) and x (input vector element) to determine the boolean variables. The server then changes the encryption of these values to FHE using the encryption conversion protocol. Finally, FHE can be used to evaluate the polynomial P.
FHE evaluation is normally very slow, but it is made efficient through the use of levelling as described earlier.
Performance evaluation
Our classifiers run in at most a few seconds, which we believe to be practical for sensitive applications. Note that even if the datasets become very large, the size of the model stays the same – the dataset size only affects the training phase which happens on unencrypted data before one uses our classifiers. Hence, the cost of our classification will be the same even for very large data sets.
For comparison, using generic secure two-party or multi-party computation tools on a simplified problem set (so as to fit into available memory), the classification was approximately 500 times slower.

2 thoughts on “Machine Learning Classification over Encrypted Data”
Comments are closed.