TAG: A Tiny Aggregation Service for ad-hoc Sensor Networks – Madden et al. 2002
** updated broken link above **
This is the third in a series of 5 ‘desert island paper’ selections from Peter Alvaro. The topics discussed in this paper seem so highly relevant to the current hope and excitement for the Internet of Things that it’s hard to believe the paper was written all the way back in 2002!
Recent advances in computing technology have led to the production of a new class of computing device: the wireless, battery powered, smart sensor. These new sensors are active, full fledged computers, capable not only of measuring real world phenomena but also filtering, sharing, and combining those measurements.
Given an ad-hoc sensor network connecting these sensors, the authors address the problem of how best to evaluate aggregate queries over sensor values while minimising communication and storage requirements. As with modern smartphones, powering on the radio is one of the most battery-draining things you can do. This paper is a great example of bringing together ideas from a variety of (sub-) disciplines (check out the related research section), and a reminder of the very broad applicability of the ideas developed within the database community – data and the efficient processing of it is central to computing! TAG can give an order of magnitude improvement over a straightforward broadcast scheme.
The value of a query language
Here’s a lesson we’ve seen in many contexts – a declarative query language that allows for independent planning, execution, and optimisation is a good idea! And if you’re going to have a declarative query language, SQL is a very strong contender.
One simple example in the paper is enough to get across the value of the approach very quickly:
SELECT AVG(volume), room FROM sensors
WHERE floor = 6
GROUP BY room
HAVING AVG(volume) > _threshold_
EPOCH DURATION 30s
This partitions sensors on the 6th floor of a building according to the room they are located in and then reports all rooms where the average volume is over a specified threshold. (I.e. those rooms that have a high likelihood of being occupied). Updates are delivered every 30 seconds. This allows end-users to pose declarative queries over sensor networks.
The primary semantic difference between TAG queries and SQL queries is that the output of a TAG query is a stream of values, rather than a single aggregate value (or batched result). In monitoring applications, such continuous results are often more useful than a single, isolated aggregate, as they allow users to understand how the network is behaving over time and observe transient effects (such as message losses) that make individual results, taken in isolation, hard to interpret.
Structuring the ad-hoc network
In an ad-hoc sensor network, devices can identify each other and route data without prior knowledge of or assumptions about the network topology, allowing the network topology to change as devices move, run out of power, or experience shifting waves of interference.
What is true for smartphones is even more true for these typically tiny sensor devices: powering on the radio for communication is expensive! If the goal is to deploy long-lived zero (or as close as possible) maintenance ad-hoc sensor networks, then power-conserving algorithms are particulary important. You don’t want to be constantly attending devices to change batteries!
TAG assumes a routing tree, which must provide two basic properties: the ability to deliver requests to all nodes in the network, and the ability to provide one or more routes from every node to the root of the network where aggregate data is being collected. These routes must guarantee at-most-once delivery.
In the tree-based routing scheme, one mote (sensor device) is appointed to be the root, usually because it is the point where the user interfaces to the network. The root broadcasts a message asking motes to organize into a routing tree; in that message it specifies its own id and its level, or distance from the root (in this case, zero.) Anymote without an assigned level that hears this message assigns its own level to be the level in the message plus one. It also chooses the sender of the message as its parent, through which it will route messages to the root.
The routing messages then flood down the tree until every node has been assigned a parent and level.
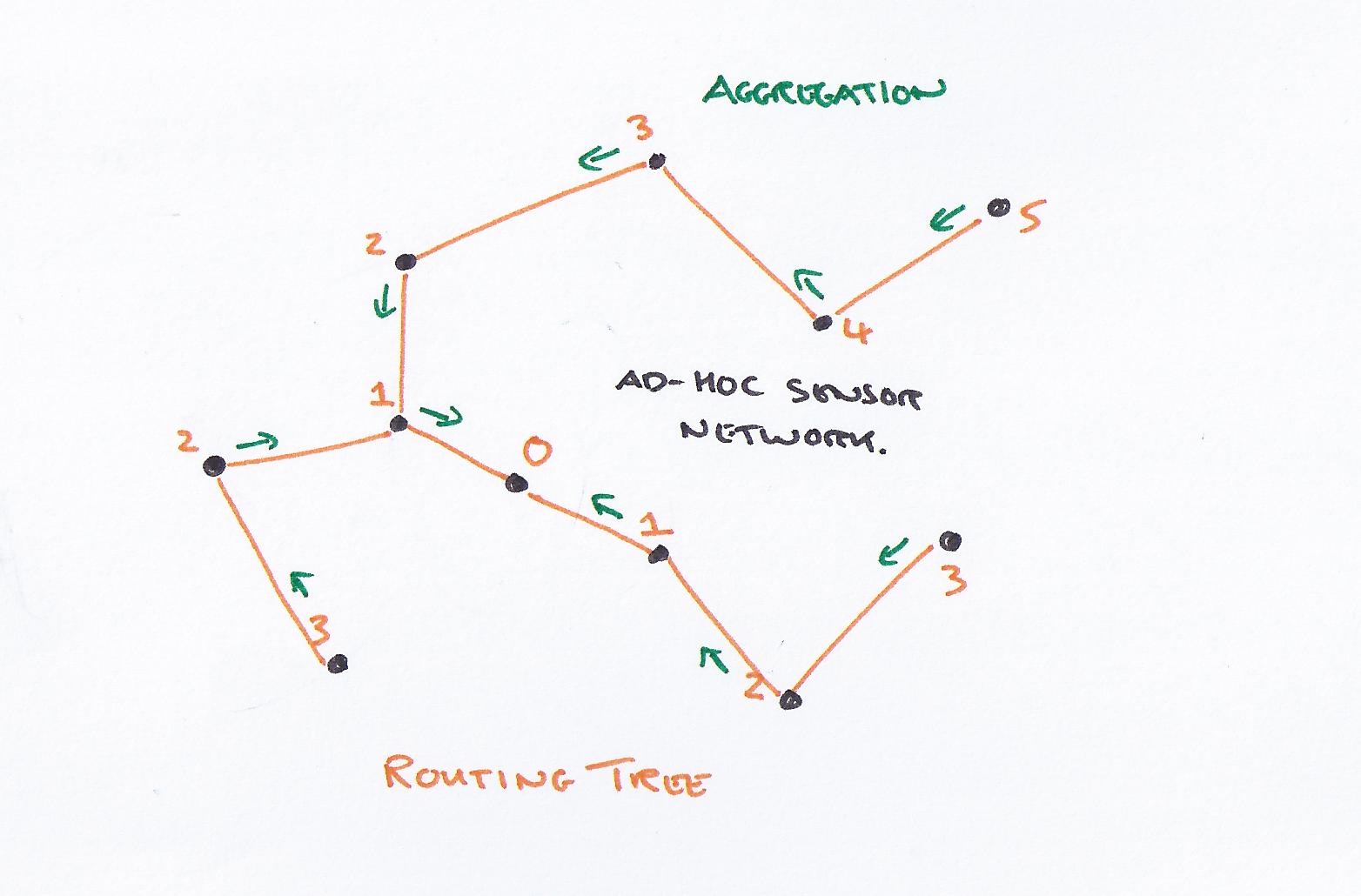
These routing messages are periodically broadcast from the root, so that the process of topology discovery goes on continuously.
Each node also maintains a small fixed-sized list of its neighbours and monitors the quality of the link to each of these by tracking the proportion of packets received from each. If the node observes that its parent p is significantly worse than some other neighbour p’, it chooses p’ as its new parent if p’ is as close or closer to the root than p, and p’ does not believe it is the parent. If a node has not heard from its parent for some time, it picks a new parent node from its neighbours based on link quality. Child nodes may need to subsequently reselect their parent as a result if there own parent’s rooting level goes up.
To send a message to the root, a sensor device broadcasts a message addressed to its parent, which in turn forwards the message to its parent, and so on up the tree. Broadcasting a message from the root is covered next…
Processing aggregates
This is where we get to the really good stuff! Borrowing from techniques developed for shared-nothing parallel query processing environments, aggregrates are implemented using three functions: a merging function, an initialization function, and an evaluation function. The orginal SQL specification defines just five aggregate functions: COUNT, MIN, MAX, SUM and AVERAGE. For TAG the desire is to support a broader set, and a set of dimensions for classifying aggregates is introduced that help when assessing their performance implications. The dimensions are:
- Duplicate sensitive (yes or no): for example COUNT is duplicate sensitive, but MAX is not.
- Exemplary or Summary: exemplary aggregates return one or more representative values from the set of all values, whereas summary values compute some property over all of them. Examplary aggregates are much more sensitive to loss than summary aggregates.
- Monotonic (yes or no): when two state records with partial results are combined, is the result always either >= (monotonically increasing), or <= (monotonically decreasing) the partials? This affects whether some predicates (such as HAVING) can be applied in-network.
- The amount of state required for each partial state record. The possible categories are: distributive (partials the same size as the aggregate); algebraic (partials of constant size); holistic (proportional in size to the size of the data in question); unique (proportional to the number of distinct values in the set of data in question); and context-sensitive (proportional to some property of the records in question).
A naive implementation of sensor network aggregation would be to use a centralized, server-based approach where all sensor readings are sent to the base station, which then computes the aggregates. In TAG, however, we compute aggregates in network whenever possible, because, if properly implemented, this approach can be lower in number of message transmissions, latency, and power consumption than the server-based approach.
In the distribution phase, aggregate queries are pushed down into the network, and in the collection phase aggregate values are continually routed up from children to parents. Since the query semantics partition time into epochs, one unique value must be produced each epoch. The amount of communication can be reduced if a parent batches the results from all of its children before sending them on to its parent in turn (vs sending each message up the tree as it arrives).
We will accomplish this by having parents subdivide the epoch such that children are required to deliver their partial state records during a parent-specified time interval. This interval is selected such that there is enough time for the parent to combine partial state records and propagate its own record to its parent…. During the epoch after query propagation, each mote listens for messages from its children during the interval it specified when forwarding the query. It then computes a partial state record consisting of the combination of any child values it heard with its own local sensor readings. Finally, during the transmission interval requested by its parent, the mote transmits this partial state record up the network.
Grouping introduces additional requirements. A grouping expression is pushed down with the query so that nodes can choose which group they belong to (groups partition sensors). When a node receives an aggregate from a child it checks the group id and combines with its own value if it is in the same group, or forwards it unaltered otherwise. Some HAVING clauses for groups can be used to suppress message communication – for example ‘HAVING MAX x already. This cannot always be done – ‘HAVING MAX > x’ does not permit such an optimisation for example, because a greater value may always be found in the group from another sensor not yet aggregated.
The TAG aggregate processing scheme has three compelling advantages:
- It dramatically reduces the communication required to compute an aggregate vs a centralized aggregaion approach. In simulation, an order of magnitude improvement over the centralized approach was found for many aggregates, with the worst case performance (e.g. MEDIAN) equivalent to the centralized approach.
- In most cases, each sensor device is only required to transmit a single message per epoch, regardless of its depth in the routing tree. In the centralized approach, nodes nearer the top of the tree are required to transmit significantly more messages, and therefore their batteries drain much faster.
- By explicitly dividing time into epochs, a convenient mechanism for idling the processor is obtained.
Optimisations
Because messages are broadcast over a shared channel, nodes can ‘snoop’ on other messages in their vicinity. If a node misses the initial request to begin aggregation for example, it can still initiate it after snooping on the network traffic of nearby nodes by assuming it should be aggregating if they are. Snooping can also help to reduce message transmission – consider a MAX aggregation: if a neighbour thas reported a higher value there is no need to send your own.
For MAX, MIN and other monotonic, exemplary aggregates, this technique is directly applicable. There are a number of ways it can be applied – the snooping approach, where nodes suppress their local aggregates if they hear other aggregates that invalidate their own, is one. Alternatively, the root of the network (or any subtree of the network) seeking an exemplary sensor value, such as a MIN, might compute the minimum sensor value over the highest levels of the subtree, and then abort the aggregate and issue a new request asking for values less than over the whole tree. In this approach, leaf nodes need not send a message if their value is greater than the minimum observed over the top levels; intermediate nodes, however,must still forward partial state records, so even if their value is suppressed, they may still have to transmit.
A related optimisation involves computing aggregates accurate to within some probability. For example, in the case of an AVERAGE, and given an error bound, any device whose sensor value is within the bound of a prior hypothesis value need not respond. Of course, there’s a rich world of probabilistic data structures that can also be exploited for aggregrate functions – these are not discussed in the paper.
To help cope with message loss, nodes can keep a cache of their children’s value for some previous number of epochs and use those values when new ones are unavailable due to message loss. In a simulation with a network of diameter 50, 15 rounds of caching was shown to significantly increase the number of nodes included in a aggregate.
The substantial benefit of this technique suggests that allocating RAM to application level caching may be more beneficial than allocating it to lower-level schemes for reliable message delivery, as such schemes cannot take advantage of the semantics of the data being transmitted.
Making use of available redundancy and choosing two parents also improves node reach. For duplicate insensitive aggregates the value can be sent to both, for duplicate sensitive aggregates a child must choose only one of the two parents to send to.

Link to paper has been gnawed at by Internet rodents. Appears fully broken.
Thanks for the catch! Link is now updated… (http://www.gta.ufrj.br/wsns/Aggregation/tag_tiny02.pdf)