The Chubby lock service for loosely coupled distributed systems – Burrows ’06
This paper describes the Chubby lock service at Google, which was designed as a coarse-grained locking service, found use mostly as a name service and configuration repository, and inspired the creation of Zookeeper.
[Chubby’s] design is based on well-known ideas that have meshed well: distributed consensus among a few replicas for fault tolerance, consistent client-side caching to reduce server load while retaining simple semantics, timely notification of updates, and a familiar file system interface. We use caching, protocol-conversion servers, and simple load adaptation to allow it scale to tens of thousands of client processes per Chubby instance. We expect to scale it further via proxies and partitioning. Chubby has become Google’s primary internal name service; it is a common rendezvous mechanism for systems such as MapReduce [4]; the storage systems GFS and Bigtable use Chubby to elect a primary from redundant replicas; and it is a standard repository for files that require high availability, such as access control lists.
Why build a coarse-grained locking service?
Before Chubby, most systems at Google used either an ad-hoc mechanism for primary election, or required operation intervention after a failure. The introduction of Chubby brought a significant increase in availability. Creating a lock service rather than just a client library made it easier to integrate with existing applications. This proved useful since:
… our developers sometimes do not plan for high availability in the way one would wish.
Distributed consensus requires a quorum, so several replicas are needed to ensure availability. Chubby usually runs five replicas in a cell. Client systems that depend on Chubby can make progress with fewer replicas, whereas this would not be possible with an embedded library.
A lock-based interface is also familiar to Google’s programmers, although it turns out that can be a double-edged sword:
…many programmers have come across locks before, and think they know to use them. Ironically, such programmers are usually wrong, especially when they use locks in a distributed system; few consider the effects of independent machine failures on locks in a system with asynchronous communications. Nevertheless, the apparent familiarity of locks overcomes a hurdle in persuading programmers to use a reliable mechanism for distributed decision making.
Chubby is explicity designed for coarse-grained locking use cases (for example, when electing a primary), and not for fine-grained locks that might be held only for a short duration. This has important consequences for the design of Chubby:
Coarse-grained locks impose far less load on the lock server. In particular, the lock-acquisition rate is usually only weakly related to the transaction rate of the client applications … it is good for coarse-grained locks to survive lock-server failures, but there is little concern about the overhead of doing so, and such locks allow many clients to be adequately served by a modest number of lock servers with somewhat lower availability.
Name Service vs DNS
In practice, Chubby’s most popular use inside Google turned out to be as a name service, not as a lock service. With DNS it is desirable to have a short TTL in order get prompt replacement of failed services, but this creates a risk of overloading DNS servers with requests. The particular nature of Google’s workload meant this was especially likely:
It is common for our developers to run jobs involving thousands of processes, and for each process to communicate with every other, leading to a quadratic number of DNS lookups. We might wish to use a TTL of 60s; this would allow misbehaving clients to be replaced without excessive delay and is not considered an unreasonably short replacement time in our environment. In that case, to maintain the DNS caches of a single job as small as 3 thousand clients would require 150 thousand lookups per second. Larger jobs create worse problems, and several jobs many be running at once. The variability in our DNS load had been a serious problem for Google before Chubby was introduced.
(Presumably something fundamental in the workload necessitates that communication pattern, which otherwise looks far from ideal).
Because Chubby’s caching uses explicit invalidation, keep-alive messages are sufficient to maintain an arbitrary number of cache entries indefinitely at a client. In fact, Chubby’s cache guarantees are stronger than a name service strictly needs – timely notification is sufficient rather than full consistency.
As a result, there was an opportunity for reducing the load on Chubby by introducing a simple protocol-conversion server designed specifically for name lookups. Had we foreseen the use of Chubby as a name service, we might have chosen to implement full proxies sooner than we did in order to avoid the need for this simple, but nevertheless additional server.
Google also implemented a Chubby DNS server than makes Chubby name entries available to DNS clients and eases the transition for existing applications.
The Design of Chubby
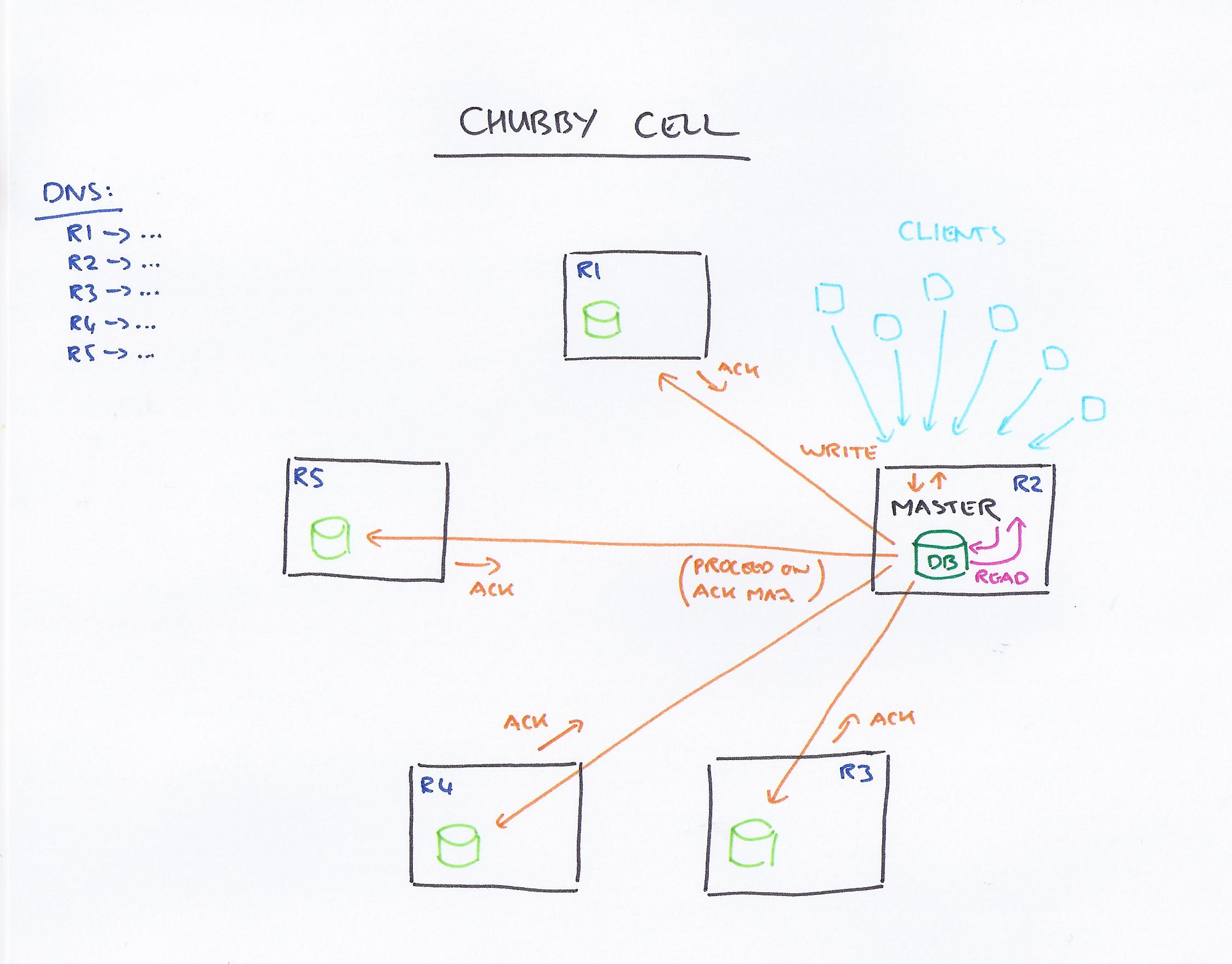
A Chubby cell is a small set of (typically 5) replicas that use Paxos to elect a master. DNS is used to find the replicas, which can then point to the current master. Chubby exposes a file-system like interface, and nodes may be either permanent or ephemeral (tied to client sessions, and automatically deleted if no client has them open).
The design differs from UNIX in a ways that ease distribution. To allow the files in different directories to be served from different Chubby masters, we do not expose operations that can move files from one directory to another, we do not maintain directory modified times, and we avoid path-dependent permission semantics (that is, access to a file is controlled by the permissions on the file itself rather than on directories on the path leading to the file). To make it easier to cache file meta-data, the system does not reveal last-access times.
Each Chubby file and directory can act as a lock – either one client can hold it in write mode, or any number of clients can hold it in read mode.
Like the mutexes known to most programmers, locks are advisory. That is, they conflict only with other attempts to acquire the same lock: holding a lock called F neither is necessary to access the file F, nor prevents other clients from doing so. We rejected mandatory locks, which make locked objects inaccessible to clients not holding their locks.
Amongst the several reasons given for this, the argument that it makes debugging and administration significantly easier is compelling.
Chubby clients can subscribe to a range of events concerning nodes in the file system, these are delivered after the corresponding change has taken place. “Thus, if a client is informed that file contents have changed, it is guaranteed to see the new data if it subsequently reads the file.” Chubby clients can also cache file data and node meta-data using a lease mechanism, with invalidations sent by the master.
The caching protocol is simple: it invalidates cached data on a change, and never updates it. It would be just as simple to update rather than to invalidate, but update-only protocols can be arbitrarily inefficient; a client that accessed a file might receive updates indefinitely, causing an unbounded number of unnecessary updates.
On loss of the master, failover makes use of a grace period to allow sessions to be maintained whenever possible:
When a master fails or otherwise loses mastership, it discards its in-memory state about sessions, handles, and locks. The authoritative timer for session leases runs at the master, so until a new master is elected the session lease timer is stopped; this is legal because it is equivalent to extending the client’s lease. If a master election occurs quickly, clients can contact the new master before their local (approximate) lease timers expire. If the election takes a long time, clients flush their caches and wait for the grace period while trying to find the new master. Thus the grace period allows sessions to be maintained across fail-overs that exceed the normal lease timeout.
The 9-step process for the newly elected master is described, and “readers will be unsurprised to learn that the fail-over code, which is exercised far less often than other parts of the system, has been a rich source of interesting bugs.”
For scaling, a proxy to handle read and keep-alive requests can be placed in front of Chubby. The directory tree can also be partitioned across servers, though, as of 2006, the need to do this had not yet arisen.
Lessons learned
The paper presents an interesting set of lessons learned from rolling out the Chubby service at Google. Users never fail to suprise you! Here are some of my favourite excerpts:
Many services use shared Chubby cells, which makes it important to isolate clients from the misbehaviour of others. Chubby is intended to operate within a single company, and so malicious denial-of-service attacks against it are rare. However, mistakes, misunderstandings, and the differing expectations of our developers lead to effects that are similar to attacks.
The Chubby team tried instituting a review process before any client application could go live against Chubby, but “our early reviews were not thorough enough.”
Despite attempts at education, our developers regularly write loops that retry indefinitely when a file is not present, or poll a file by opening it and closing it repeatedly when one might expect they would open the file just once. At first we countered these retry-loops by introducing exponentially-increasing delays when an application made many attempts to Open() the same file over a short period. In some cases this exposed bugs that developers acknowledged, but often it required us to spend yet more time on education. In the end it was easier to make repeated Open() calls cheap.
And finally, it’s always a good idea to plan to fail.
We find that our developers rarely think about failure probabilities, and are inclined to treat a service like Chubby as though it were always available. For example, our developers once built a system employing hundred of machines that initiated recovery procedures taking tens of minutes when Chubby elected a new master. This magnified the consequences of a single failure by a factor of a hundred both in time and the number of machines affected… Developers also fail to appreciate the difference between a service being up, and that service being available to their applications.

4 thoughts on “The Chubby lock service for loosely coupled distributed systems”
Comments are closed.