Improving Cloud Service Resilience using Brownout-aware Load Balancing – Klein et al 2014
This is what the previous two #themorningpaper selections have been building to. What happens when you apply brownout techniques to a set of load-balanced servers?
We study how to extend the classical cloud service architecture composed of a load-balancer and replicas with a recently proposed self-adaptive paradigm called brownout.
The following diagram (click to see larger view) tells a compelling story. Taking a load-balanced system with 5 servers (replicas) numbered 0-4, one replica is killed every 100 seconds until only 1 remains, then the replicas are brought back online one-at-a-time, also at 100 second intervals. The request rate is held constant throughout. The top plot shows what happens without brownout, and the bottom chart shows what happens with it.
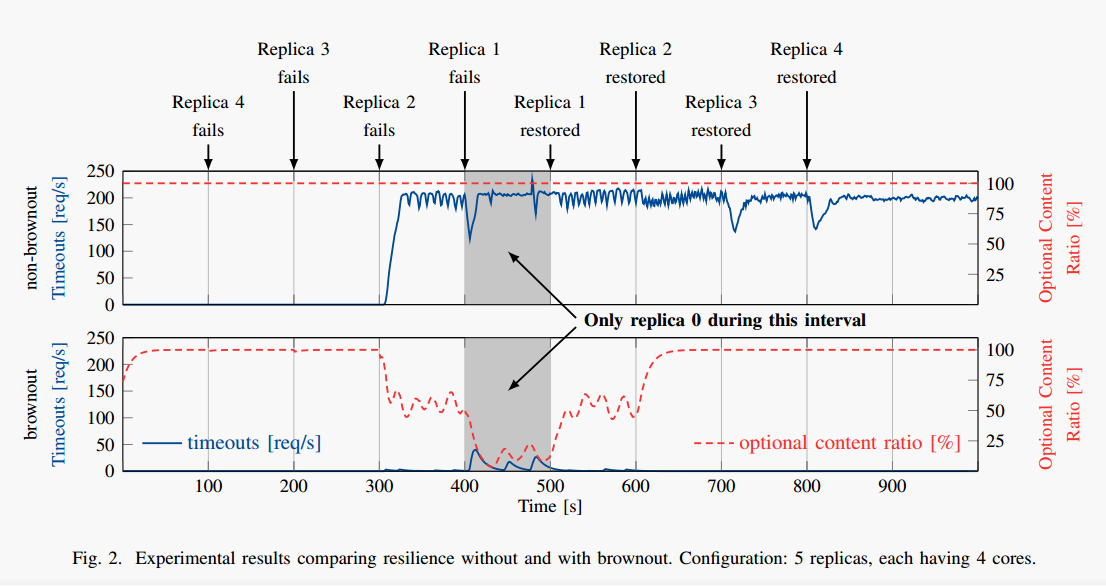
Note that without brownout controls in place, a large number of requests start timing out after the third replica has failed. These timeouts continue even when replicas are restored. This is attributed to ‘rotten’ requests that have timed out from the user perspective but are still active on the server-side – thus e.g. the database is wasting all its time on transactions that either will time out, or have already timed-out on the user side.
The bottom plot shows the dramatic difference made to this particular system by applying brownout controls. The red line shows the automatically controlled setting of the dimmer switch (altering the ratio of responses that include optional content to those that don’t). The blue line again shows the number of requests that time out: a dramatic improvement in user experience and system resiliency. It would be great to see a further study that also includes circuit-breakers.
The basic brownout technique as applied to an individual server/replica we covered in the previous edition of #themorningpaper. If you are using a load-balancer that depends in some way on response times, the adaptive behaviour arising from the brownout dimmer switch may confuse it.
The issue is to ensure that replica self-adaptivity would not confuse the load-balancing algorithm, overloading replicas that are already struggling with capacity shortage.
Recall that for a brownout-compliant service, the mandatory part of the response is always computed, but the optional part is computed only with a certain probability governed by a control variable called the dimmer. Klein et. al. piggy-back the current dimmer-switch value from a replica onto the normal response flow so that it can be used in load-balancing decisions.
Compared to the near-optimal (for non-adaptive workloads) Join the Shortest Queue (JSQ) algorithm,
results show that the resulting service can tolerate more replica failures and that the novel load-balancing algorithms improve the number of requests served with optional content by up to 5%.
From the charts earlier therefore, a lot of the gains come from simply having brownout controlled replicas. The load-balancing enhancements are then the icing on the cake. Two algorithms are explored: the first is a variant of a PI controller which adjusts queue-offsets (for a base JSQ algorithm) based on dimmer switch settings; the second strives to keep the dimmer value the same across all replicas.
In summary, adding brownout to a replicated service improves its resilience, even when using a brownout-unaware load-balancing algorithm… However, we observed that in scenarios featuring capacity heterogeneity, our algorithms performed better than shortest queue first (JSQ) with respect to the optional content ratio.

Do you know if the paper is archived anywhere else? As that link is down for me today.
Looks like the link has been restored (just tested it). Google Scholar is also a good place to find pdfs: here’s the scholar link for the paper in question: http://scholar.google.co.uk/scholar?q=cloud+service+resilience+brownout+aware+load+balancing