Holistic Configuration Management at Facebook – Tang et al. (Facebook) 2015
This paper gives a comprehensive description of the use cases, design, implementation, and usage statistics of a suite of tools that manage Facebook’s configuration end-to-end, including the frontend products, backend systems, and mobile apps.
The configuration for Facebook’s site is updated thousands of times per day. There are also thousands of engineers who make those configuration changes. Thousands of changes made by thousands of people is a recipe for configuration errors – a major source of site outages. Therefore Facebook need a holistic configuration solution that is robust and can cope with this rate of change. One of the reasons that Facebook make so many configuration changes, is that they use configuration so for many different things:
- For controlling which users experience a new feature – for example, whether 1%, 5% or 10% of users should see it is managed via configuration
- For conducting live experiments (e.g. A/B tests) to try out different parameters
- For application-level traffic control…
Configs help manage the site’s traffic in many ways. Automation tools periodically make config changes to shift traffic across regions and perform load tests in production. In case of emergency, a config change kicks off automated cluster/region traffic drain and another config change disables resource-hungry features of the site. During shadow tests, a config change starts or stops duplicating live traffic to testing servers. During a fire drill, a config change triggers fault injection into a production system to evaluate its resilience.
- For topology setup and load-balancing of TAO
- For control of the monitoring stack:
Facebook’s monitoring stack is controlled through config changes: 1) what monitoring data to collect, 2) monitoring dashboard (e.g., the layout of the key-metric graphs), 3) alert detection rules (i.e., what is considered an anomaly), 4) alert subscription rules (i.e., who should be paged), and 5) automated remediation actions [27], e.g., rebooting or reimaging a server. All these can be dynamically changed without a code upgrade, e.g., as troubleshooting requires collecting more monitoring data.
- For updating machine learning models
- To control an application’s internal behaviour (i.e., the ‘classic’ configuration use case)
All of these are handled via configuration which is canonically stored in git with a watcher that monitors the git repositories and pushes changes to live systems. Sweet!
The config itself is often generated by code, with a defined set of validators for config values also provided in code:
We take a truly configuration-as-code approach to compile and generate configs from high-level source code. We store the config programs and the generated configs in a version control tool.
Before a configuration change makes it into production there are four layers of safeguards:
First, the configuration compiler automatically runs validators to verify invariants defined for configs. Second, a config change is treated the same as a code change and goes though the same rigorous code review process. Third, a config change that affects the frontend products automatically goes through continuous integration tests in a sandbox. Lastly, the automated canary testing tool rolls out a config change to production in a staged fashion.
Canary testing itself is also driven through configuration:
A config is associated with a canary spec that describes how to automate testing the config in production. The spec defines multiple testing phases. For example, in phase 1, test on 20 servers; in phase 2, test in a full cluster with thousands of servers. For each phase, it specifies the testing target servers, the healthcheck metrics, and the predicates that decide whether the test passes or fails. For example, the click-through rate (CTR) collected from the servers using the new config should not be more than x% lower than the CTR collected from the servers still using the old config.
At the core of Facebook’s configuration management process is a tool called the configerator [sic]. It provides all of the foundational capabilities: version control, authoring, code review, automated canary testing, and config distribution.
Configerator distributes a config update to hundreds of thousands of servers scattered across multiple continents. In such an environment, failures are the norm. In addition to scalability and reliability, other properties important to Configerator are 1) availability (i.e., an application should continue to run regardless of failures in the configuration management tools); and 2) data consistency (i.e., an application’s instances running on different servers should eventually receive all config updates delivered in the same order, although there is no guarantee that they all receive a config update exactly at the same time).
A Git Tailer continuously monitors git for changes and pushes them to Zeus (a forked version of ZooKeeper) for distribution. Zeus uses a three-level, high fan-out distribution tree to distribute configs using a push model. There are leaders, observers, and proxies. Each data center has multiple clusters, each with thousands of servers. A Zeus leader first commits a write on its followers, and then asynchronously pushes the write to observers (of which it may have hundreds). Observers keep a fully replicated read-only copy of the leader’s data. Every server runs a configuration proxy, which randomly picks an observer to connect to. Applications use the proxy to fetch their config:
The proxy reads the config from an observer with a watch so that later the observer will notify the proxy if the config is updated. The proxy stores the config in an on-disk cache for later reuse. If the proxy fails, the application falls back to read from the on-disk cache directly. This design provides high availability. So long as a config exists in the on-disk cache, the application can access it (though outdated), even if all Configerator components fail, including the git repository, Zeus leader/followers, observers, and proxy.
For large configuration objects, a separate peer-to-peer distribution mechanism is used.
The full end-to-end flow is illustrated by this diagram:
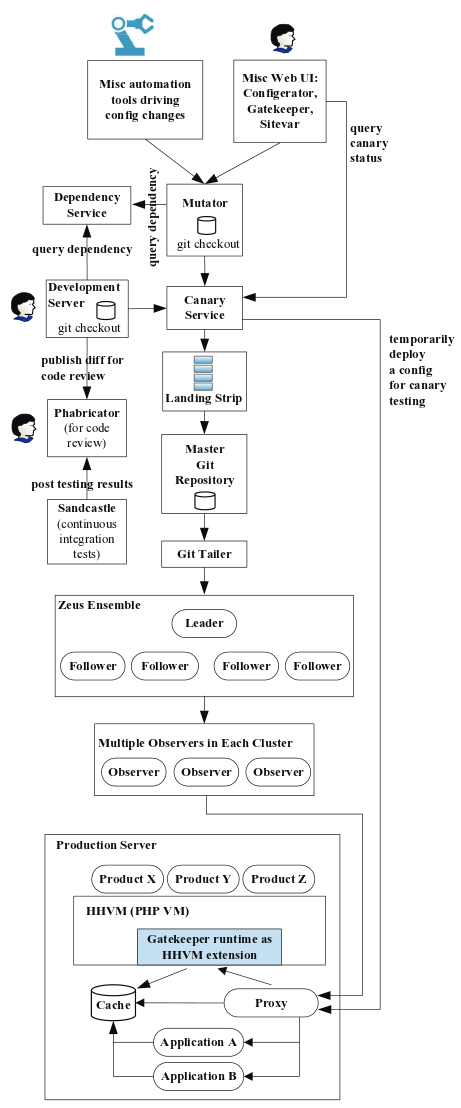
The ‘landing strip’ is there to address contention caused by so many engineers making concurrent commits into a shared config repository.
The “Landing Strip” in Figure 3 alleviates the problem, by 1) receiving diffs from committers, 2) serializing them according to the first-come-first-served order, and 3) pushing them to the shared git repository on behalf of the committers, without requiring the committers to bring their local repository clones up to date. If there is a true conflict between a diff being pushed and some previously committed diffs, the shared git repository rejects the diff, and the error is relayed back to the committer. Only then, the committer has to update her local repository clone and resolve the conflict.
This helps but does not fully alleviate the problem. The issue arise because all configuration for all projects is stored in one git repository. The Facebook team are investigating a configuration tree approach where different git repositories are used for different branches of the tree (e.g. /feed and /tao).
On top of the base configuration infrastructure runs the Gatekeeper. Gatekeeper manages code rollout through online config changes:
While a new product feature is still under development, Facebook engineers commonly release the new code into production early but in a disabled mode, and then use Gatekeeper to incrementally enable it online. If any problem is detected during the rollout, the new code can be disabled instantaneously. Without changing any source code, a typical launch using Gatekeeper goes through multiple phases. For example, initially Gatekeeper may only enable the product feature to the engineers developing the feature. Then Gatekeeper can enable the feature for an increasing percentage of Facebook employees, e.g., 1%→10%→100%. After successful internal testing, it can target 5% of the users from a specific region. Finally, the feature can be launched globally with an increasing coverage, e.g., 1%→10%→100%.
To enable or disable a product feature, Gatekeeper first evaluates a set of configuration-specified constraints called restraints. If these restraints are satisfied, it probabilistically determines whether to pass or fail the gate depending on a configurable property that controls user sampling (e.g. 1% or 10%).
Examples of restraints include checking whether the user is a Facebook employee and checking the type of a mobile device… A Gatekeeper project is dynamically composed out of restraints through configuration. Internally, a restraint is statically implemented in PHP or C++. Currently, hundreds of restraints have been implemented, which are used to compose tens of thousands of Gatekeeper projects. The restraints check various conditions of a user, e.g., country/region, locale, mobile app, device, new user, and number of friends.
All of this control logic is stored as a config that can be changed live without a code update.
Gatekeeper projects manage product feature rollouts. When a user accesses facebook.com, the Gatekeeper projects are checked in realtime to determine what features to enable for the user. Because the check throughput is high (billions of checks per second) and some Gatekeeper restraints are data intensive, currently Gatekeeper consumes a significant percentage of the total CPU of the frontend clusters that consist of hundreds of thousands of servers. We constantly work on improving Gatekeeper’s efficiency. On the other hand, we consider this “overhead” worthwhile, because it enables Facebook engineers to iterate rapidly on new product features. This is evidenced by the popularity of Gatekeeper. In 2014, tens of thousands of Gatekeeper projects were created or updated to actively manage the rollouts of a huge number of micro product features.
When an engineer makes a change, it takes about 10 minutes to go through the canary process, 5 seconds to then commit the change into the shared git repository, another 5 seconds for the tailer to fetch the change from the repository and write it to Zeus, and about 4.5 seconds from there to reach hundreds of thousands of servers across multiple continents.
Is all of this machinery something that only applies at Facebook scale? For the general principles at least, no – anyone trying to continuously deliver new features into production can benefit. The authors conclude the paper by contemplating what lessons and principles might be applicable outside of Facebook.
The technology we described is not exclusive for large Internet services. It matters for small systems as well.. .Agile configuration management enables agile software development.
Among many other lessons, I like this one:
Although the use cases of configuration management can be very diverse (e.g., from gating product rollouts to A/B testing), it is feasible and beneficial to support all of them on top of a uniform and flexible foundation, with additional tools providing specialized functions. Otherwise, inferior wheels will be reinvented. At Facebook, it is a long history of fragmented solutions converging onto Configerator.

“Every server runs a configuration proxy, which randomly picks an observer to connect to. Applications use the proxy to fetch their config”.
But at the same time they write “Configerator uses the push model”.
If every server has to connect to a proxy, it looks like the pull model, does not it?
From my recollection, updates are pushed to the configuration proxies, and applications pull from there. So it’s a mixture of both modes…