Mergeable replicated data types – part II Kaki et al., OOPLSA ’19
Last time out we saw how Mergeable Replicated Data Types (MRDTs) use a bijection between the natural domain of a data type and relational sets to define merge semantics between two concurrently modified versions given their lowest common ancestor (LCA). Today we’re picking things up in §4 of the paper, starting with how to derive a merge function for an arbitrary data type.
The basic approach so far has been to take the difference between each version and the LCA, and add those differences to the LCA state. But using an example of a pair data type holding pairs of integers, the authors show that what we’ve been doing so far isn’t quite good enough. We need to merge the pair state, and also the state of the first and second members of the pair.
The pair example demonstrates the need and opportunity to make merges compositional. The specification of such a composite merge function is invariably compositional in terms of the merge specifications of the types involved.
Given a merge function for counters, we can construct a merge function for a pair of counters. Given a merge function for queues, we can construct a merge function for a pair of queues. The ‘pair’ merge function is the same in both cases, parameterised by the merge function for its element type.
Observe that the specification captures the merge semantics of a pair while abstracting away the merge semantics of its component types… The ability to compose merge specifications in this way is key to deriving a sensible merge semantics for any composition of data structures.
Not every element in a composite data type may itself be mergeable though. Consider a map data type which may have non-mergeable keys, and mergeable values. The merge strategy should work differently for the mergeable and non-mergeable components, so we need a way to tell the two cases apart. To handle that the authors introduce type specifications for characteristic relations.
Types in 
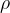


A relation’s type specification is well-formed if all of its tuple types can be flattened to tuple types such that the first element is non-mergeable. In the pair of counters example, we could use e.g.
let R_pair (x,y) = {(1,x), (2,y)}
The tuples here are of type 
The merge specification 

- The Set-Merge rule tells us how to merge constraints for a relation composed only of non-mergeable types. The Set-Merge rules applies for example to
for queues.
- The rule Order-Merge-1 constrains the merge result for relations with a tuple type involving the cross-product of other relations. It says that all tuples and their ordering should be preserved in the merge.
- The rule Order-Merge-2 is there to prevent new tuples being created out of thin air. The rules Order-Merge-1 and Order-Merge-2 together apply for example to
for queues.
- The rules Rel-Merge-1 and Rel-Merge-2 relate a data structure composed of multiple types to the (mergeable) values of those types through (non-mergeable) ordinals or identifiers.
Deriving merge functions
The specification tells us the desired behaviour of a merge, but it doesn’t give us a function that implements it. The next part of the paper shows how to automatically synthesise such a function given the specification.
The synthesis process is quite straightforward as the expressive merge specification
already describes what the result of a relational merge should be. For each first-order logic constraint
in
that computes the merged relation in a way that satisfies the constraint.
Imagine a set of OCaml functions that implement each of the rules, and you won’t be far off (full details in §5 on p18). There’s also an implementation of the graph-based approach to concretisation, 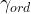
All these pieces come together in an OCaml library that lets you derive MRDTs from ordinary OCaml data types. Here are a couple of examples:

The @@deriving merge annotation (added to OCaml using a PPX extension) tells the compiler to automatically derive the merge function.
Quark
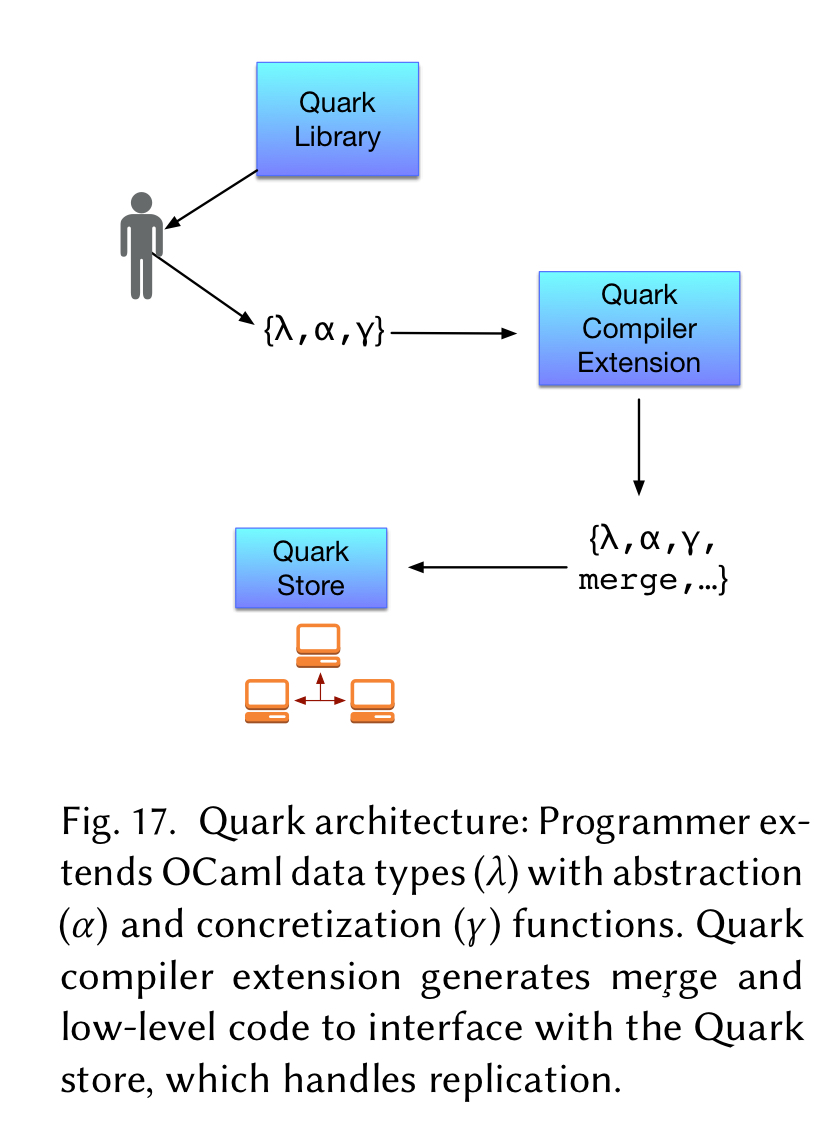
The MRDT concept is brought to life in an implementation called Quark. Quark has three main components:
- A library of MRDT modules for basic data structures such as lists and binary trees, and a collection of signatures and functions that help in the development of new MRDTs.
- An OCaml compiler extension for generating merge functions, and also for serializing and deserializing data structures for replication, using the third component of Quark…
- A content-addressable distributed storage abstraction, called the Quark store.
If you’ve been reading along so far and thinking “this all sounds wonderful, but what’s the catch?,” then one of the answers to that question is that the merge functions take two different versions, and their lowest common ancestor. How do you efficiently store, compute, and retrieve the LCA given two concurrent versions? And when do you know it is safe to garbage collect old versions that might one day be the LCA of some future merge??
Quark addresses this by using its custom store, the Quark store:
The key innovation of the Quark store is the use of a storage layer that exposes a Git-like API, supporting common Git operations such as cloning a remote repository, forking off branches, and merging branches using a three-way merge function…
It’s implemented as a content-addressable block store to maximise the potential for sharing between different versions of data structures. The authors reference a separate paper (‘Version control is for your data too’) for the details of this store, but TBH there isn’t a ton of detail on the store there either.
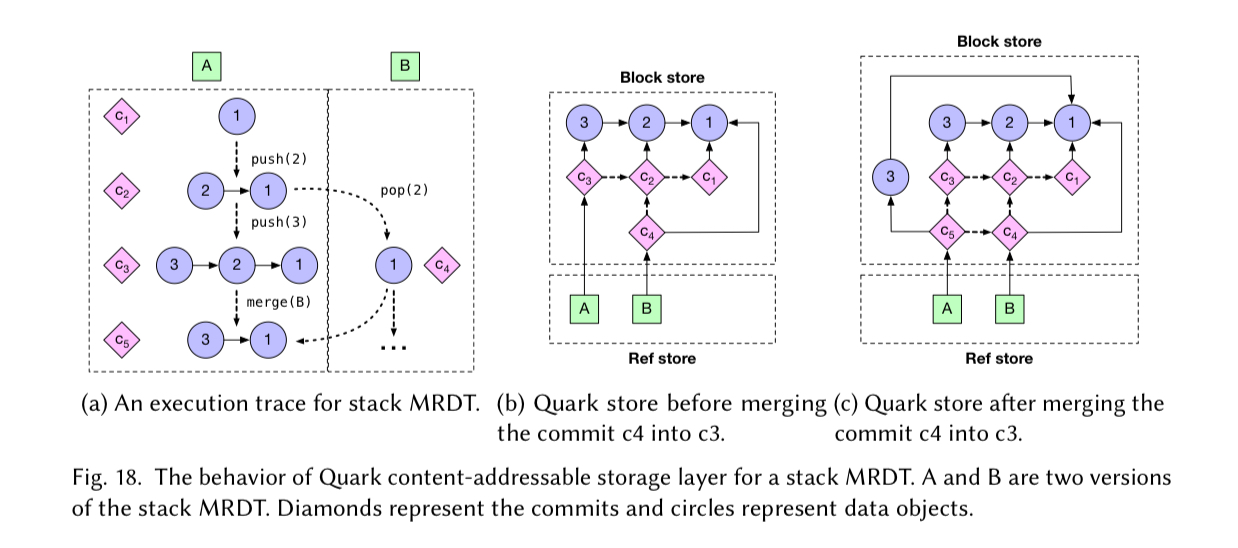
Evaluation
The evaluation looks at several data types implemented in Quark and analyses the merge overhead and size of the diffs over time. The short summary here is that “diff experiments show that the version control-inspired replication model can be efficiently supported for common data structures by transmitting succinct diffs over the network rather than entire versions.”
The authors also implemented four large application benchmarks (TPC-C, TPC-E, RUBiS, and Twissandra) as a collection of MRDTs.
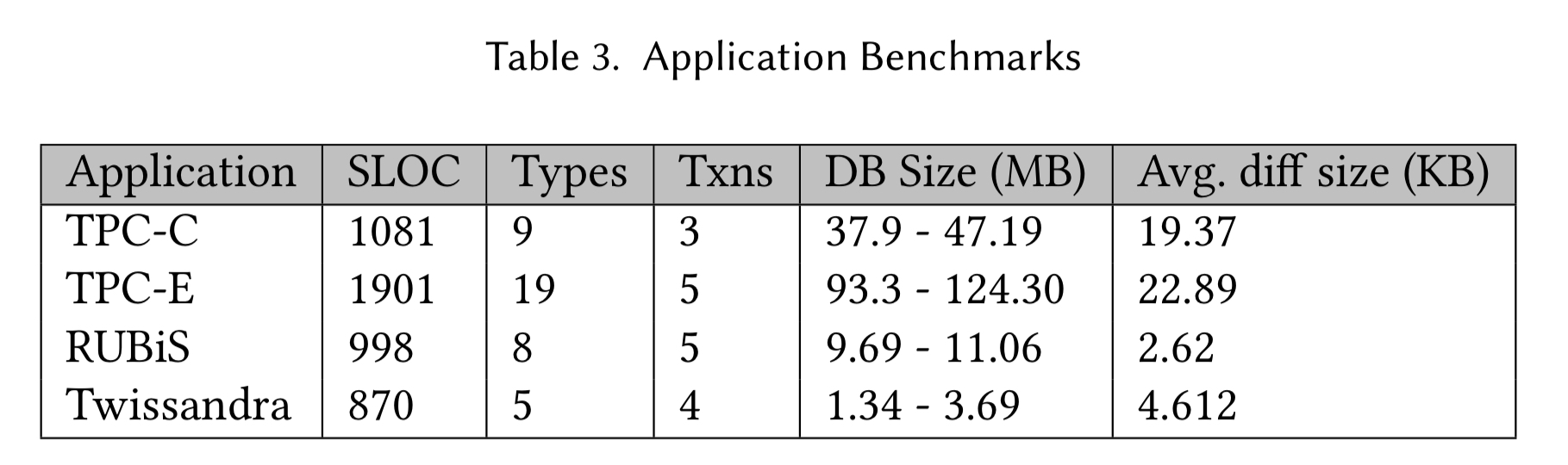
For those familiar with TCP-C, here’s a fun rendition of the tables as mergeable types:

We don’t get to find out how many tps the system does, but the DB size column in the table above does show us that after 500 transactions the database size has grown by around 10MB – 20KB per transaction. The good news is that this number stays constant at around 20KB rather than growing. The bad news is that 20KB per transaction is going to add up fast!!
