Meltdown Lipp et al., 2018
I’m writing this approximately one week ahead of when you get to read it, so it’s entirely possible by this time that you’ve already heard more than you can stand about Meltdown and Spectre! Behind the news headlines though, there’s a lot of good information in the accompanying papers, and I certainly wanted to read them, so that’s what we’re going to be starting out with this week.
Meltdown breaks all security assumptions given by the CPU’s memory isolation capabilities. We evaluated the attack on modern desktop machines and laptops, as well as servers in the cloud. Meltdown allows an unprivileged process to read data mapped in the kernel address space… this may include physical memory of other processes, the kernel, and in case of kernel-sharing sandbox solutions (e.g., Docker, LXC) or Xen in paravirtualization mode, memory of the kernel (or hypervisor) and other co-located instances.
Depending on the capabilities of the target machine, it’s possible to dump memory at up to 503 KB/s. There’s an interesting footnote on the first page of the paper that says “This attack was independently found by the authors of this paper and Jann Horn from Google Project Zero.” Two independent discoveries of the same vulnerability, which it turns out has existed on Intel microarchitectures since 2010, certainly makes you wonder how many other ‘discoveries’ of this there might have been in the intervening period.
You’re bang out-of-order
(That might be just a British expression, if it doesn’t make sense to you, just ignore it!).
The roots of the problem go way back to 1967, when Tomasulo first developed an algorithm to allow out-of-order execution of instructions. Inside a CPU there are multiple execution units. To keep things moving at pace, while the CPU is busy executing the current instruction in one execution unit, other units can run ahead, speculatively executing the instructions that follow. The particular case of out-of-order execution this paper concerns itself with is an instruction sequence following a branch.
If we look inside a Skylake core, we’d find something like this:
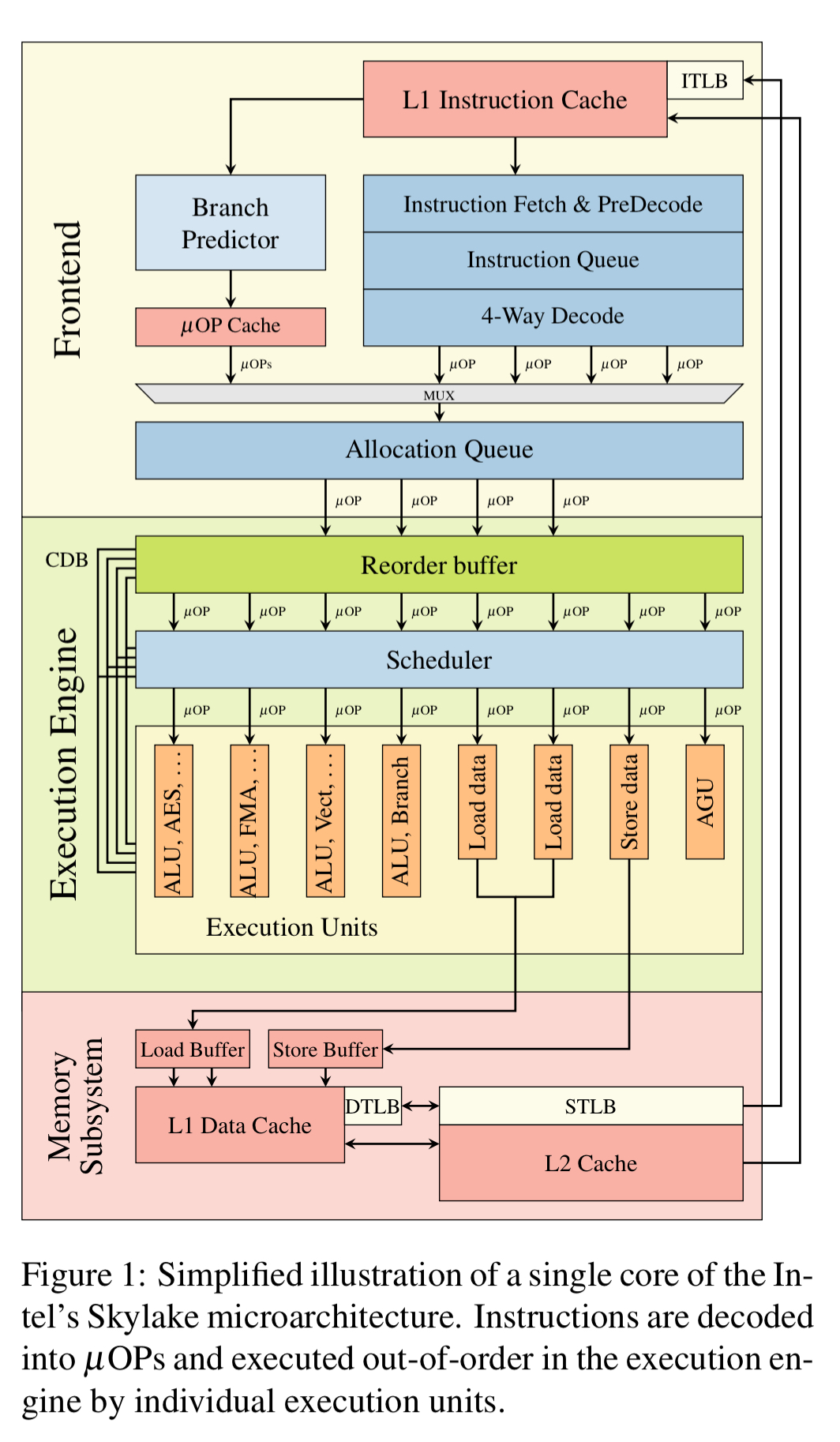
x86 instructions are fetched from memory by the front-end, and decoded to micro-operations which are continuously sent to the execution engine. The reorder buffer is responsible for swizzling the registers so that instructions operating on the same physical registers use the last logical value. Execution units are connected via a common data bus, and if a required operand is not immediately available then it’s possible to listen on the bus and directly begin instruction execution the moment it appears.
Since CPUs usually do not run linear instruction streams, they have branch prediction units that are used to obtain an educated guess of which instruction will be executed next. Branch predictors try to determine which direction of a branch will be taken before its condition is actually evaluated. Instructions that lie on that path and do not have any dependencies can be executed in advance and their results immediately used if the prediction was correct.
If the guess was wrong, the results can just be rolled back and it’s as if they never happened. Or at least that’s the plan! But as we all now know, unfortunately some traces do get left behind…
Although the instructions executed out of order do not have any visible architectural effect on registers or memory, they have microarchitectural side effects. During the out-of-order execution, the referenced memory is fetched into a register and is also stored in the cache. If the out-of-order execution has to be discarded, the register and memory contents are never committed. Nevertheless, the cached memory contents are kept in the cache.
Consider the following simple example:
raise_exception()
// the line below is never reached
access(probe_array[data * 4096]);
“
Although we know the code on line 3 will never be reached, it still might be speculatively executed. We’d like to know what the value of data was during that execution. Since we multiply data by 4096, every access to the probe array is one memory page (4kB) apart: therefore each unique value of data maps to a different unique page. If we ensure that the probe array is not in cache (is flushed) before the execution, then after the speculative execution, the only page of the array that will (now) be in the cache is the page indexed by the data value.
Now all we have to do is iterate over all of the 256 possible values of the data byte and observe how many cycles it takes to read each page of the probe array. This combination is known as a ‘Flush+Reload’ cache side channel.
Figure 4 shows the result of a Flush+Reload measurement iterating over all pages, after executing the out-of-order snipped with
data = 84. Although the array access should not have happened due to the exception, we can clearly see that the index which would have been accessed is cached. Iterating over all pages (e.g. in the exception handler) shows only a cache hit for page 84.

Let us call instructions executed out-of-order which leave behind measurable side effects transient instructions. Such instructions introduce an exploitable side channel if their operation depends on a secret value. We’d like to, for example, dump the memory of the kernel address space (which will include all of the physical memory on Linux and OS X, and pretty much all of it on Windows). The kernel memory is protected of course, and if we try to access it that will trigger an exception. But not to worry – if the exception occurs after the execution of the transient instruction sequence the damage is already done, and we can just handle it. On more modern processors we can wrap everything up in hardware transactions using Intel TSX and suppress the exception altogether (which happens automatically as part of transaction rollback). One trivial exception handling technique is to fork the attacking application before accessing the invalid memory location, and only access that location in the child process. The parent process can then recover the secret.
I’m having a Meltdown
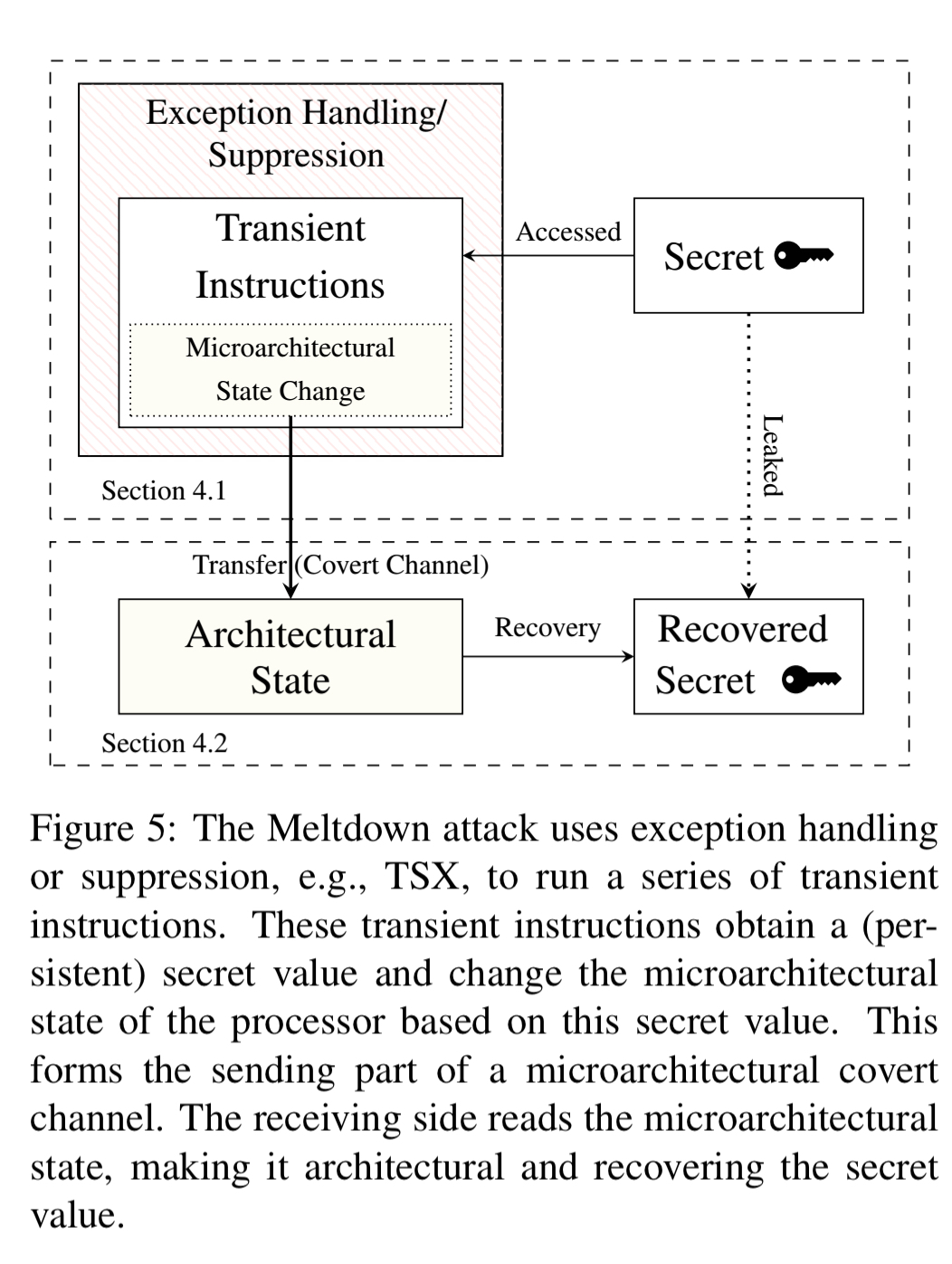
The full Meltdown attack consists of three steps:
- The content of an attacker-chosen memory location, which is inaccessible to the attacker, is loaded into a register
- A transient instruction accesses a cache line based on the secret content of the register
- The attacker uses Flush+Reload to determine the accessed cache line and hence the secret stored at the memory location.
The core implementation of the transient instruction sequence and sending part of the covert channel looks like this:

Line 4 loads a byte value located at a target kernel address. While this is going on, the subsequent instructions on lines 5-7 are likely to be speculatively executed. Line 5 multiplies the secret value by the page size (4 KB, or 2^12 — 0xc), and line 7 contains an indirect memory access based on the result. This will affect the cache state based on the secret value. Iterating over all 256 pages of the probe array and measuring the access time reveals the secret as before.
It just remains to explain what that jz retry instruction is doing on line 6. There’s a race condition between the speculative execution and cache probing, and the triggering of an exception caused by trying to read from an inaccessible kernel address on line 5. When the exception is triggered, the register where the data should be stored gets zero’d out. But if the zeroing out of the register happen before the execution of line 5, we’d read a false zero as the value of the secret.
To prevent the transient instruction sequence from continuing with a wrong value, i.e., ‘0’, Meltdown retries reading the address until it encounters a value different from ‘0’ (line 6). As the transient instruction sequence terminates after the exception is raised, there is no cache access if the secret value (truly is) 0. Thus, Meltdown assumes that the secret value is indeed ‘0’ if there is no cache hit at all. The loop is terminated by either the read value not being ‘0’ or by the raised exception of the invalid memory access.
Meltdown was successfully reproduced on the following systems:
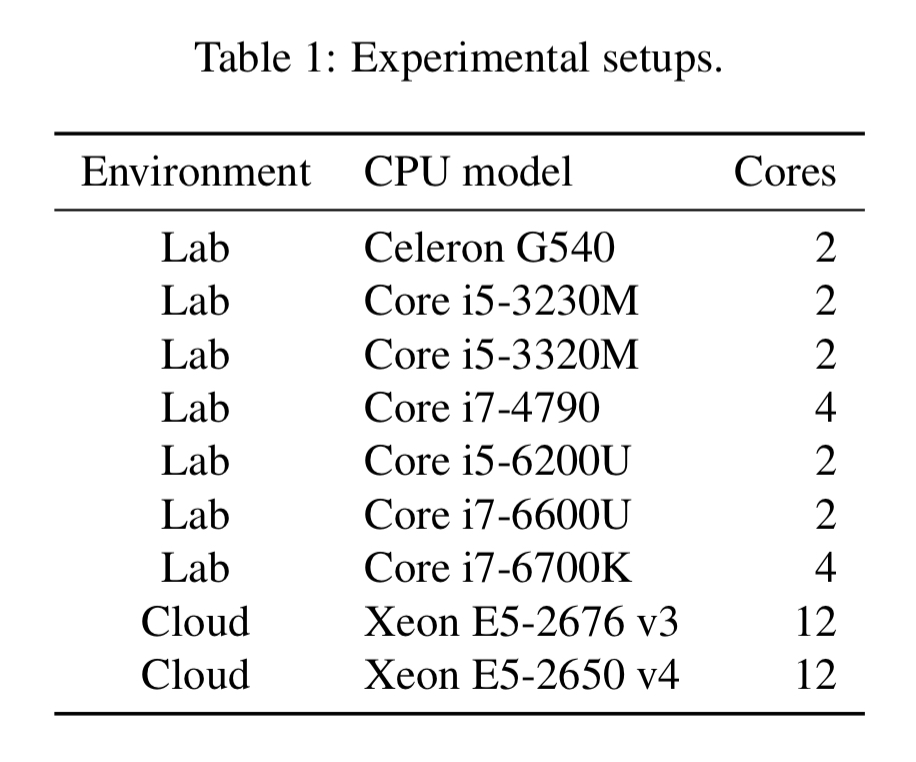
Using the exception handling strategy, it was possible to leak kernel memory at a rate of 122 KB/s. Using Intel TSX to suppress exceptions that goes up to 502 KB/s.
Meltdown was also demonstrated within containers (Docker, LXC, OpenVZ). This gives access to information both from the underlying kernel and also all other containers running on the same physical host.
… the isolation of containers sharing a kernel can be fully broken using Meltdown.
Defences?
Kernal address space layout randomisation (KASLR) makes it harder to find the kernel memory, but not by much it turns out. An attacker can simply search through the address space, or de-randomise the direct-physical map: “assuming that the target system has at least 8GB of physical memory, the attacker can test defences in steps of 8GB, resulting in a maximum of 128 memory locations to test.”
The KAISER patch by Gruss et al. (or its equivalents) seems to be what is going into the OS patches (mitigations really – this isn’t a software vulnerability remember). It provides stronger isolation between kernel and user space by mapping only the bare minimum of kernel memory in user space (and still with the protection bit set of course).
Consequently, Meltdown cannot leak any kernel or physical memory except for the few memory locations which have to be mapped in user space. We verified that KAISER indeed prevents Meltdown, and there is no leakage of any kernel or physical memory.
That sounds alright then? Apply the patches, pay the performance penalty, forget about Meltdown and move onto worrying about Spectre? Not quite… it’s important to keep reading into section 7.2 of the paper where we find this:
Although KAISER provides basic protection against Meltdown, it still has some limitations. Due to the design of the x86 architecture, several privileged memory locations are required to be mapped in user space. This leaves a residual attack surface for Meltdown… Even though these memory locations do not contain any secrets, such as credentials, they might still contain pointers. Leaking one pointer can be enough to again break KASLR, as the randomization can be calculated from the pointer value. Still, KAISER is the best short-term solution currently available and therefore be deployed on all systems immediately.
The authors were unable to reproduce Meltdown on ARM and AMD CPUs, though that’s not quite the same thing as saying that variations of the attack will not be possible.
The world will never be the same again…
Meltdown fundamentally changes our perspective on the security of hardware optimizations that manipulate the state of microarchitectural elements. The fact that hardware optimizations can change the state of microarchitectural elements, and thereby imperil secure software implementations, is known since more than 20 years. Both industry and the scientific community so far accepted this as a necessary evil for efficient computing… Meltdown changes the situation entirely… it is nothing any (cryptographic) algorithm can protect itself against. KAISER is a short-term software fix, but the problem we uncovered is much more significant.
One of the sobering things here is that improved performance is an observable effect which creates a side-channel to leak information. (That’s not a new observation, witness all the variations on the Flush+Reload cache attacks for example). But what would it mean to eliminate that side-channel? The whole point of performance improvements is that they’re observable! If you don’t see improved performance, it’s not a performance improvement. Moreover, if we think about adding noise we can only slow down discovery but not eliminate it — it’s possible to add noise that makes the occasional cached data be returned more slowly, but not the other way round. Making everything always go as slowly as the slowest possible route doesn’t seem all that appealing either!
And then there’s this:
Even if Meltdown is fixed, Spectre will remain an issue. Spectre and Meltdown need different defenses. Specifically mitigating only one of them will leave the security of the entire system at risk.
You locked the front door, but you left the backdoor wide open.

I guess NSA was very well aware of this vulnerability since long. How many agree with me here?
It’s hard to believe the opposite.
Once again, a concise, simple to understand summary of a complex issue. Thanks Adrian!
So why are the AMD processors supposedly not susceptible to the Meltdown attack?
It’s taking a long time to approve my comment.
Did I ask a bad question?