MacroBase: Analytic Monitoring for the Internet of Things – Bailis et al. 2016
It looks like Peter Alvaro is not the only one to be doing some industrial collaboration recently! MacroBase is the result of Peter Bailis’ collaboration with Cambridge Mobile Telematics (CMT), an IoT company. The topic at hand is analytic monitoring – detecting anomalies (outliers) in streams of data. In many scenarios this combines the twin demands of scale (hundreds of thousands to millions of complex events per second) and timeliness (minutes or maybe even seconds to report an outlier situation). All the while performing complex statistical calculations. The solution that Bailis et al. come up with combines robust statistical estimation with several novel streaming data structures.
As a result of the optimisations and data structures we develop in this paper, our MacroBase prototype allows for interactive exploration and high-performance streaming deployment – up to 1M points per second on a single core – while producing meaningful results that we have already leveraged to find previously unknown bugs in production systems at CMT.
I’m going to focus on the ‘optimisations and data structures’ in this review, but there is another story that also unfolds in the paper – one of careful system design based on analysis of properties of the problem space, of thinking deeply and taking the time to understand the prior art (aka ‘the literature’), and then building on those discoveries to advance and adapt them to the new situation. “That’s what research is all about!” you may say, but it’s also what we’d (I’d?) love to see more of in practitioner settings too. The result of all this hard work is a system that comprises just 7,000 lines of code, and I’m sure, many, many hours of thinking! The MacroBase source code is available on GitHub.
MacroBase is configured to ingest data from multiple sources (e.g. Postgres, Kafka, Amazon Kinesis, etc.) – what the Google machine learning team describe as ‘signals.’ Each signal is a stream (sequence) of multi-dimensional data points. A data point combines some attributes (metadata) such as device ID and/or user ID, and some number of metrics such as battery drain. MacroBase users do not need to specify anything about the algorithms used in computation, they simply describe the attributes and metrics of their data sources and let MacroBase figure out the rest. A graphical front-end supports interactive exploration. Users may also specify a batch query to be run as a one-off, or streaming queries that are run in a continuous manner. MacroBase gives precedence to recent items through exponentially decayed damped-window streaming (e.g. decreasing the importance of points at a rate of 50% every hour).
MacroBase is designed to identify behaviours that occupy a sweet spot between obvious catastrophes (e.g. most requests are failing) that will be caught by standard processes (e.g. customer assurance) and one-off events (e.g. a single request is ill-formed). In our experience, the largest opportunities in analytic monitoring for IoT occupy this middle ground, which contains too much data for manual inspection and also contains subtle behaviours that can be difficult to detect manually.
The overall flow supported by MacroBase is as follows:

…of which the most interesting parts are how outlier detection and summarisation is done. Outlier detection operators monitor the input for interesting points that deviate from “normal” behaviour, dividing points into ‘outliers’ and ‘inliers.’ Summarization finds points that are common to the outliers, but relatively uncommon to the inliers – thus giving a first-level explanation of why the outliers have been flagged. In both cases the authors describe a batch process, and then show how it can be adapted to the streaming scenario.
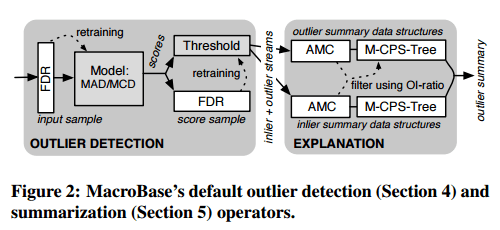
Outlier Detection
The criteria for an outlier detection solution were that it could work out of the box without any user intervention, that it would provide meaningful results, and that it would be efficient to execute (especially in a streaming model). After evaluating several methods, the authors turned to robust statistical estimation.
The core of MacroBase’s default outlier detection operator is powered by robust statistical estimation, a branch of statistics that pertains to finding statistical distributions for data that is well-behaved for the most part but may contain a number of ill-behaved data points. The basic insight is that if we can find a distribution that reliably fits most of the data, we can measure each point’s distance from this distribution in order to find outliers. While robust statistics have a long history, they “remain largely unused and even unknown by most communities of applied statisticians, data analysts, and scientists that might benefit from their use.”
Using a mean based model to detect outliers is not robust since a single outlying value can easily skew the mean. Instead it is better to consider distance from the median. The Median Absolute Deviation (MAD) plays the role of standard deviation in this world. MacroBase uses a multivariate version of MAD called MCD (Minimum Covariance Determinant) that works for queries with multiple metrics.
The MCD summarises a set of points according to its location (absolute distance in metric space) and scatter (relative distribution in metric space). Scale is captured via a sample mean μ and scatter via a covariance matrix C… Exactly computing the MCD requires examining all subsets of points to find the subset whose covariance matrix exhibits the minimum determinant. This is computationally intractable for even modest-sized datasets. Instead, for the actual computation of the MCD covariance and mean, MacroBase adopts an iterative approximation called FastMCD.
You may be wondering what MacroBase does when presented with a singular covariance matrix ;). Simple! “MacroBase instead computes the Moore-Penrose pseudo inverse of the covariance matrix, which preserves many of the properties of the inverse covariance matrix yet is guaranteed to exist.” I confess to having very little understanding of what this actually means!
In theory, many robust estimators such as MAD and MCD require data drawn from a given (single) distribution. In practice, it seems to work well even when that condition does not hold: “even for arbitrary distributions [extreme value analysis such as Z-Scores] provides a good heuristic idea of the outlier scores of data points, _even when they cannot be interpreted statistically” (Aggarwal).
Record-at-a-time evaluation in not discussed in the robust statistics literature; as a result, it is unclear how to immediately adapt the above models to a streaming context. Conceptually, MacroBase treats streaming outlier detection as an online model evaluation and retraining problem. MacroBase continuously fits distributions to the data it has seen and scores each point as it arrives. However, there are two attendant problems. First, how should the system update its models without consulting all points previously seen? MAD requires a median of distances to existing points, and MCD is an inherently combinatorial iterative process. Second, how should the system determine whether a score is anomalous? Given a percentile-based threshold, the system needs to update its threshold continuously…
To solve these problems, Bailis et al. turn to reservoir sampling. Classic reservoir sampling accumulates a uniform sample over a set of data using finite space and a single pass, Chao adapts this to weighted sampling over data streams. “MacroBase adapts Chao’s algorithm to provide a novel, exponentially damped streaming reservoir sample that works over arbitrary windows.” The algorithm can be described very succinctly:

This allows both time-based and tuple-based window policies (compared to previous single-tuple-at-a-time solutions). We call the resulting structure the Flexible Damped Reservoir (FDR). FDR separates the tuple insertion process from the decay and maintenance processes… The resulting algorithm is simple but powerful. As Efraimidis writes, Chao’s results “should become more known to the databases and algorithms communities.”
MacroBase uses an input FDR that samples the input of the outlier detector operator and can be used to periodically retrain it. It also uses an FDR to address the problem of threshold maintenance by sampling the output of the outlier detector. This is used to periodically recompute quantiles (e.g. the 99th percentile of recent scores).
Outlier Summarization
Outlier summarization finds attribute values that are common to the outliers but relatively uncommon to the inliers.
We define a combination of an attributes ratio of support (occurrences) in outliers to support in inliers as its outlier-inlier (OI-) ratio…
Support and OI-ratio correspond to frequent itemset mining and emerging pattern mining in data mining. Computing OI-ratios for all attributes is expensive, but computing them for single attributes is inexpensive as this can be done in a single pass over the data for both inliers and outliers. MacroBase therefore first computes OI-ratios of single attribute values, and then computes attribute combinations only from the attribute values with sufficient OI-ratios. The complete process has three stages and is implemented with a prefix-tree FPGrowth itemset mining algorithm:
- Calculate OI-ratios between inlier and outlier attribute values, and filter out those with an OI-ratio below some threshold of support.
- Compute the supported outlier attribute combinations
- Compute the OI-ratio for each attribute combination based on its support in the inliers.
Streaming summarization proved more challenging…
MacroBase adapts a combination of two data structures; a probabilistic heavy-hitter sketch for the frequent items, and a novel adaptation of the CPS-Tree data structure to store frequent attributes. The result is an approximation of the frequent attribute sets.
The essence of the approach is as follows:
- When a new data point arrives, each of the point’s corresponding attributes is inserted into an approximate counting data structure.
- A subset of the point’s attributes are also inserted into a prefix tree that maintains an approximate frequency descending order.
- When a window elapses, MacroBase decays the counts of the attributes in the counting data structure, and the counts of the nodes in the prefix tree. Any items no longer supported are removed, and the prefix tree is resorted into frequency-descending order.
- To produce summaries, MacroBase runs the FPGrowth algorithm on the streaming prefix tree.
For the counting data structure the authors chose to trade-off increased memory usage for higher performance, resulting in a structure they call an Amortized Maintenance Counter (AMC). See the paper for details.
The modification of the CPS-tree (M-CPS) used to store a frequency-descending prefix tree is that whereas CPS stores at least one node for every item ever observed in the stream, M-CPS only stores items that were frequent in the previous window. Storing all items is infeasible at scale.
For the evaluations of the effectiveness of these structures, see the full paper.
If the subject matter in this paper interests you, you may also like SnappyData, a new open source in-memory database supporting approximate query processing and stream processing, from some of my ex-colleagues at Pivotal.

5 thoughts on “MacroBase: Analytic Monitoring for the Internet of Things”
Comments are closed.