No Compromises: Distributed Transactions with Consistency, Availability, and Performance – Dragojević et al. 2015
Let’s do a thought experiment. In the last couple of days we’ve been looking at transaction commit protocols and assessing their cost in terms of the number of message delays and forced-writes. But suppose for a moment that network I/O and storage I/O were not the bottleneck, that those operations where really cheap. Instead, imagine if CPUs were the bottleneck. In such a crazy world would the optimum design for a transaction processing system (and datastore) look the same? What trade-offs would you make differently?
This crazy world is real, it’s powered by lots of little batteries, and it changes everything! We could call it FaRMville. In FaRMville you can have distributed transactions with strict serializability and still get incredibly high performance, low latency, durabilty, and high availability. In FaRMville transactions are processed by FaRM – the Fast Remote Memory system that we first looked at last year. A 90 machine FaRM cluster achieved 4.5 million TPC-C ‘new order’ transactions per second with a 99th percentile latency of 1.9ms. If you’re prepared to run at ‘only’ 4M tps, you can cut that latency in half. Oh, and it can recover from failure in about 60ms. Of course, since FaRMville is such a topsy-turvy world that challenges all of our assumptions, the authors had to design new transaction, replication, and recovery protocols from first principles…
This paper demonstrates that new software in modern data centers can eliminate the need to compromise. It describes the transaction, replication, and recovery protocols in FaRM, a main memory distributed computing platform. FaRM provides distributed ACID transactions with strict serializability, high availability, high throughput and low latency. These protocols were designed from first principles to leverage two hardware trends appearing in data centers: fast commodity networks with RDMA and an inexpensive approach to providing non-volatile DRAM.
RDMA we’ve encountered before on The Morning Paper – it stands for Remote Direct Memory Access. One-sided RDMA is the fastest communication method supported by RDMA and provides one-way direct access to the memory of another machine, bypassing the CPU.
DRAM in the data center is becoming plentiful and cheap:
A typical data center configuration has 128-512GB of DRAM per 2-socket machine, and DRAM costs less than $12/GB. This means that a petabyte of DRAM requires only 2000 machines, and this is sufficient to hold the data sets of many interesting applications.
It’s those ‘lots of little batteries’ that I mentioned earlier that make things really interesting though… Instead of a centralized, expensive UPS (uninterruptible power supply), a distributed UPS integrates Lithium-ion batteries into the power supply units of each chassis in a rack. The estimated cost is less than $0.005 per Joule, and it’s more reliable than a traditional UPS. All these batteries mean that we can treat memory as if it was stable storage…
A distributed UPS effectively makes DRAM durable. When a power failure occurs, the distributed UPS saves the contents of memory to a commodity SSD using the energy from the battery. This not only improves common-case performance by avoiding synchronous writes to SSD, it also preserves the lifetime of the SSD by writing to it only when failures occur. An alternative approach is to use non-volatile DIMMs (NVDIMMs), which contain their own private flash, controller and supercapacitor (e.g., [2]). Unfortunately, these devices are specialized, expensive, and bulky. In contrast, a distributed UPS uses commodity DIMMs and leverages commodity SSDs. The only additional cost is the reserved capacity on the SSD and the UPS batteries themselves.
In the worst case configuration, it costs about $0.55/GB for non-volatility using this approach, and about $0.90/GB for the storage cost of the reserved SSD capacity. The combined additional cost is therefore about 15% of the base DRAM cost.
The combination of high-performance networking with RDMA and the ability to treat memory as stable storage eliminates network and storage bottlenecks, and as a consequence exposes CPU bottlenecks.
FaRM’s protocols follow three principles to address these CPU bottlenecks: reducing message counts, using one-sided RDMA reads and writes instead of messages, and exploiting parallelism effectively.
The reason to reduce message counts is all of the CPU involved in marshaling, unmarshmaling, and dispatching (we’ve seen serialization and deserialization become the bottleneck before, even in less extreme hardware scenarios). FaRM uses primary-backup replication and an optimistic concurrency four-phase commit protocol.
One-sided RDMA enables direct access to remote data without involving the remote CPU at all, and places minimal requirements on the local CPU. But if there’s no remote CPU involvement, there’s not going to be any additional processing in the remote region either, and that requires thinking about the design of the system a little differently. (The processing of one-sided RDMA requests is handled in the NIC).
FaRM transactions use one-sided RDMA reads during transaction execution and validation. Therefore, they use no CPU at remote read-only participants. Additionally, coordinators use one-sided RDMA when logging records to non-volatile write-ahead logs at the replicas of objects modified in a transaction. For example, the coordinator uses a single one-sided RDMA to write a commit record to a remote backup. Hence, transactions use no foreground CPU at backups. CPU is used later in the background when lazily truncating logs to update objects in-place.
Because it’s so unusual, it’s worth stressing again that these write-ahead logs are simply held in memory, because memory is stable storage.
Failure detection and recovery also has to look a little different…
For example, FaRM cannot rely on servers to reject incoming requests when their leases expire because requests are served by the NICs, which do not support leases. We solve this problem by using precise membership to ensure that machines agree on the current configuration membership and send one-sided operations only to machines that are members. FaRM also cannot rely on traditional mechanisms that ensure participants have the resources necessary to commit a transaction during the prepare phase because transaction records are written to participant logs without involving the remote CPU. Instead, FaRM uses reservations to ensure there is space in the logs for all the records needed to commit and truncate a transaction before starting the commit.
Transaction Model
FaRM uses optimistic concurrency and provides strict serializability. During the execution phase of a transaction, objects reads happen from memory (local access or via RDMA), and all writes are buffered locally. The address and version of every object accessed is recorded. At the end of the transaction, the commit protocol proceeds as follows:
- Lock phase: the coordinator writes a LOCK record to the log on each machine that is a primary for any written object. The record contains the versions and new values for every written object. Primaries process these messages by attempting to lock the objects at the specified version using compare-and-swap. They send back a message indicating whether or not all locks were successfully taken. If any object version has changed since it was read by the transaction, or another transaction has the object locked, then the coordinator aborts the transaction and writes an abort record to the log on all primaries.
- Validation phase: the coordinator now checks that the versions of all objects read by the transaction have not changed. This can be done via one-sided RDMA with no remote CPU involvement. If a primary holds more than some threshold tr objects then an RPC is used instead (the current cut-off point where RPC becomes cheaper is 4). The transaction is aborted if the versions have changed.
- Commit backups phase: the coordinator writes a commit-backup record to the logs at each backup, and waits for an ack from the NIC (remote CPU is not involved).
- Commit primaries phase: once acks have been received from the NICs at every backup (this is necessary to guarantee strict serialization in the presence of failures), the coordinator writes a commit-primary record to the logs at each primary. Completion can be reported to the application once at least one hardware ack is received. Primaries process these records by updating objects in place, incrementing their versions, and unlocking them.
- Truncation: “Backups and primaries keep the records in their logs until they are truncated. The coordinator truncates logs at primaries and backups lazily after receiving acks from all primaries. It does this by piggybacking identifiers of truncated transactions in other log records. Backups apply the updates to their copies of the objects at truncation time.”
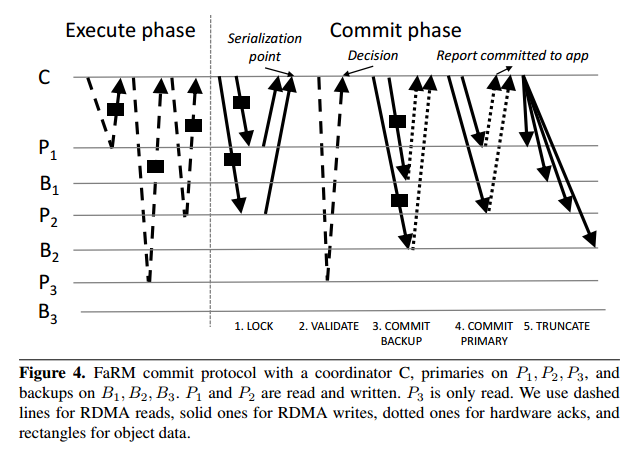
The FaRM commit phase uses Pw(f + 3) one-sided RDMA writes where Pw is the number of machines that are primaries for objects written by the transaction, and Pr one-sided RDMA reads where Pr is the number of objects read from remote primaries but not written. Read validation adds two one-sided RDMA latencies to the critical path but this is a good trade-off: the added latency is only a few microseconds without load and the reduction in CPU overhead results in higher throughput and lower latency under load.
Epochs
FaRM relies on precise knowledge of the primary and backups for every data region. After a configuration change (for example, because a machine failed and is being replaced), all machines must agree on the membership of the new configuration before allowing object mutations. FaRM reconfiguration protocol is responsible for moving the system from one configuration to the next.
Using one-sided RDMA operations is important to achieve good performance but it imposes new requirements on the reconfiguration protocol. For example, a common technique to achieve consistency is to use leases : servers check if they hold a lease for an object before replying to requests to access the object. If a server is evicted from the configuration, the system guarantees that the objects it stores cannot be mutated until after its lease expires. FaRM uses this technique when servicing requests from external clients that communicate with the system using messages. But since machines in the FaRM configuration read objects using RDMA reads without involving the remote CPU, the server’s CPU cannot check if it holds the lease. Current NIC hardware does not support leases and it is unclear if it will in the future.
When a machine receives a NEW-CONFIG message with a configuration identifier greater than its own, it prepares to move to the new configuration by updating its current configuration identifier and copy of the cached region mapping, and allocates space for any new regions assigned to it. “From this point, it does not issue new requests to machines that are not in the configuration and it rejects read responses and write acks from those machines. It also starts blocking requests from external clients.” Machines reply to the configuration manager with a NEW-CONFIG-ACK. Once acks have been received from all machines in the new configuration, the coordinator commits the new configuration by sending a NEW-CONFIG-COMMIT message. Members then unblock previously blocked external client requests, and initiate transaction recovery.
Fault detection and Recovery
We provide durability for all committed transactions even if the entire cluster fails or loses power: all committed state can be recovered from regions and logs stored in non-volatile DRAM.We ensure durability even if at most f replicas per object lose the contents of non-volatile DRAM. FaRM can also maintain availability with failures and network partitions provided a partition exists that contains a majority of the machines which remain connected to each other and to a majority of replicas in the Zookeeper service, and the partition contains at least one replica of each object.
Failure recovery has five phases:
- Failure detection, which uses very short leases (5-10ms). Expiry of any lease triggers recovery. A 90-node cluster can use 5ms leases with no false positives. “Achieving short leases under load required careful implementation” !
- Reconfiguration, using the reconfiguration protocol briefly described above.
- Transaction state recovery, using the logs distributed across the replicas of objects modified by the transaction being recovered. First access is blocked to recovering regions until all write locks for recovering transactions have been acquired. Then the logs are drained to ensure that all relevant records are processed during recovery. During the log draining process the set of recovering transactions is determined (those whose commit phase spans configuration changes). Information about these transactions is exchanged via NEED-RECOVERY messages. Then locks are acquired, log records replicated so that every participant has a full set, and the coordinator drives a commit protocol to decide whether to commit or abort. The coordinator for a given transaction is determined by consistent hashing.
- Bulk data recovery. Data recovery (re-replicating data to ensure that f replica failures can be tolerated in the future) is not necessary to resume normal operation, so it is delayed until all regions become active to minimize impact on latency-critical lock recovery.
- Allocator state recovery – the FaRM allocator splits regions into 1MB blocks used as slabs for allocating small objects. Free lists need to be recovered on the new primary by scanning the objects in the region, which is parallelized across all threads on the machine.
In the TPC-C test, the system regains most throughput in less than 50ms after the loss of a node. Full data recovery takes just over 4 minutes.