Queues don’t matter when you can JUMP them – Grosvenor et al. 2015
The Cambridge Systems at Scale team are on a roll. Hot on the heels of the excellent Musketeer paper from Eurosys 2015 comes this paper on QJUMP which last week won a best paper award at NSDI’15.
Distributed systems design involves trade-offs. One of those trade-offs we often have to make is between optimising for throughput and optimising for (low) latency. Mixing high throughput and low latency workloads on the same network sounds like a recipe for problems. Yet as we saw in the Borg paper there are excellent utilisation reasons for doing just this. A predictable consequence is tail latency, something we have also looked at in previous editions of The Morning Paper (The Tail at Scale, Blade):
Many datacenter applications are sensitive to tail latencies. Even if as few as one machine in 10,000 is a straggler, up to 18% of requests can experience high latency. This has a tangible impact on user engagement and thus potential revenue. One source of latency tails is network interference: congestion from throughput-intensive applications causes queueing that delays traffic from latency-sensitive applications.
In their evaluation, the authors found that mixing MapReduce and memcached traffic in the same network extended memcached latency in the tail by 85x compared to an interference free network. Similar effects were observed with the PTPd low-latency clock synchronisation daemon, and the Naid data-flow computation framework. This leads to the insight that if the low-latency application packets can somehow ‘jump the queue’ and take priority over the less latency sensitive application packets then we can mitigate these effects. Of course, with enough low-latency traffic we’ll also get interference between low-latency applications as well (due to contention at network switches) – we can solve that problem by rate limiting.
Our exploratory experiments demonstrate that applications are sensitive to network interference, and that network interference occurs primarily as a result of shared switch queues. QJUMP therefore tackles network interference by reducing switch queueing: essentially, if we can reduce the amount of queueing in the network, then we will also reduce network interference. In the extreme case, if we can place a low, finite bound on queueing, then we can fully control network interference. This idea forms the basis of QJUMP.
Suppose a switch has four input ports, a packet arriving at a port will wait for at most three other packets (one at each of the other three input ports) before being serviced. Now consider a multi-hop, multi-host network. Assume that each host has only one connection to the network, and in the worst case with n hosts, n-1 of them can all try to send a packet to the nth host at the same time – this gives a ‘network fan-in’ of n-1. From this we can find an upper bound on the worst case end-to-end packet delay which is given by
(n * (maximum packet size/rate of the slowest link in bits per second))
+ cumulative hop delay
We refer to the result from Equation 1 (above) as a network epoch. Intuitively, a network epoch is the maximum time that an idle network will take to service one packet from every sending host, regardless of the source, destination or timing of those packets. If all hosts are rate-limited so that they can- not issue more than one packet per epoch, no permanent queues can build up and the end-to-end network delay bound will be maintained forever.
If all hosts in a network share the same time source, we can use truly synchronized epochs, but assuming they don’t there’s still a good solution.
As an alternative, we can allow the network to become mesochronous. That is, we require all network epochs in the system to occur at the same frequency, but impose no restriction on the phase relationship between epochs.
In the worst case, this doubles the length of a network epoch.
However, unlike the Internet, datacenters have well-known network structures (i.e. host counts and link rates), and the bulk of the network is under the control of a single authority. In this environment, we can enforce system-wide policies, and calculate specific rate-limits which take into account worst-case behavior, ultimately allowing us to provide a guaranteed bound on network latency.
If all hosts are rate limited so that they only issue one packet per network epoch, then no packet will take more than one network epoch to be delivered in the worst case.
This scheme has the effect of dramatically restricting throughput as the number of hosts rises, and is overly pessimistic. Let’s assume that fewer than n hosts send to the same destination at the same time. We can introduce a throughput factor f, such that only n/f senders are assumed to simultaneously send to the same destination. Tuning the throughput factor f allows us to trade-off between highest throughput (f=n), lowest-latency (f=1), or any point inbetween.
Now consider that different applications have different throughput and latency requirements. Ideally we would like to set different f factors for the traffic of each application class….
We would like to use multiple values of f concurrently, so that different applications can benefit from the latency variance vs. throughput tradeoff that suits them best. To achieve this, we partition the network so that traffic from latency-sensitive applications (e.g. PTPd, memcached, Naiad) can “jump-the-queue” over traffic from through-put intensive applications (e.g. Hadoop). Datacenter switches support the IEEE 802.1Q [18] standard which provides eight (0–7) hardware enforced “service classes” or “priorities”.
These service-classes are not often used because prioritization often becomes a race to the top, but QJUMP can use them in a principled way:
QJUMP couples priority values and rate-limits: for each priority, we assign a distinct value of f , with higher priorities receiving smaller values. Since a small value of f implies an aggressive rate limit, priorities become useful because they are no longer “free”: QJUMP users must choose between low latency variance at low throughput (high priority) and high latency variance at high throughput (low priority).
The implementation of QJUMP and integration with existing application workloads is made very easy. To specify a QJUMP (priority) level, an application can use the SO_PRIORITY option on a secsocketopt() call. Alternatively a simple interception utility can be used to set this option on behalf of unmodified existing applications.
QJUMP differs from many other systems that use rate-limiters. Instead of requiring a rate-limiter for each flow, each host only needs one coarse-grained rate-limiter per QJUMP level. This means that just eight rate-limiters per host are sufficient when using IEEE 802.1Q priorities. As a result, QJUMP rate-limiters can be implemented efficiently in software… On our test machines, we found no measurable ef- fect of the rate-limiter on CPU utilization or throughput. On average it imposes a cost of 35.2 cycles per packet (σ = 18.6; 99th% = 69 cycles) on the Linux kernel critical path of approx. 8,000 cycles. This amounts to less than 0.5% overhead.
Evaluation
The detailed evaluation of QJUMP shows impressive results, of which I can only touch on a small subset here.
In real-world datacenters, a range of applications with different latency and bandwidth requirements share the same infrastructure. QJUMP effectively resolves network interference in these shared, multi-application environments. We consider a datacenter setup with three different applications: ptpd for time synchronization, memcached for serving small objects and Hadoop for batch data analysis. Since resolving on-host interference is outside the scope of our work, we avoid sharing hosts between applications in these experiments and share only the network infrastructure.
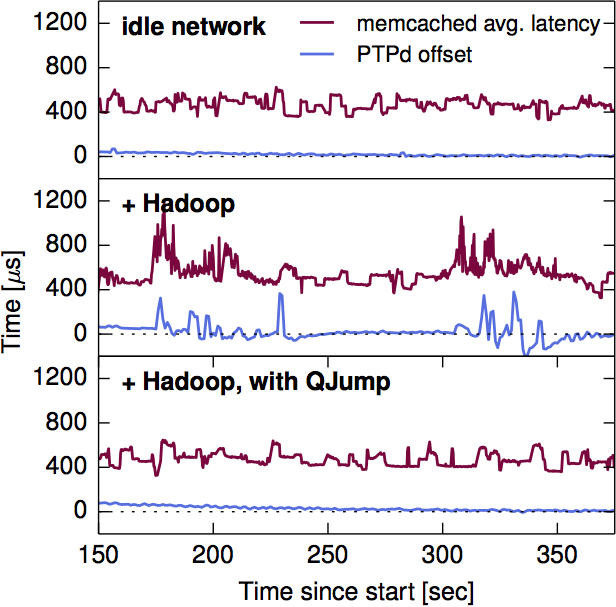
Figure 5 from the paper illustrates nicely how a high throughput Hadoop job interferes with low-latency ptpd traffic (compare the top and middle rows). The bottom row shows how very effective QJUMP is at eliminating this interference.
As we saw in Taming uncertainty in distributed systems with help from the network, we can exploit programmable networks to improve distributed systems. There’s a great illustration of this in the QJUMP paper too:
One of QJUMP’s unique features is its guaranteed latency level (described in §3.1). Bounded latency enables interesting new designs for datacenter coordination software such as SDN control planes, fast failure detection and distributed consensus systems. To demonstrate the usefulness of QJUMP’s bounded latency level, we built a simple distributed two-phase atomic-commit (2PC) application. The application communicates over TCP or over UDP with explicit acknowledgements and retransmissions. Since QJUMP offers reliable delivery, the coordinator can send its messages by UDP broadcast when QJUMP is enabled. This optimization yields a ≈ 30% throughput improvement over both TCP and UDP… Our 2PC system detects component failure within two network epochs (≈ 40μs on our network), far faster than typical failure detection timeouts (e.g. 150 ms in RAMCloud).
QJUMP is readily deployable on commodity hardware and compares very favourably to alternative approaches to easing datacenter congestion (see Table 2 in the paper for a good overview).
In an extensive evaluation, we have demonstrated that QJUMP attains near-ideal performance for real applications and good flow completion times in simulations. Source code and data sets are available from http://goo.gl/q1lpFC.
If I was operating a datacenter network, this is one project I’d certainly be keeping a very close eye on!

3 thoughts on “Queues don’t matter when you can JUMP them”
Comments are closed.