Sirius: An Open end-to-end Voice and Vision Personal Assistant and its Implications for Future Warehouse Scale Computers – Hauswald et al. 2015
Welcome back to The Morning Paper! I hope you managed to catch-up on same of your backlog over the last two weeks since normal service is resumed as of today. To kick things off, I’m dedicating this week to looking at some of the research published last month from ASPLOS ’15 and one paper from the International Conference on Cloud Engineering. So much to cover, so little time!
First up is Sirius – here’s a piece of work that really fires up my imagination on a number of dimensions. First of all, Sirius is a full open source implementation of an Intelligent Personal Assistant or IPA (think Siri, Cortana, or Google Now). I’ve wanted to play around with a system like that for some time now, and here’s something I can install on my laptop that combines speech recognition, image recognition, and a question-and-answer system. Of course, this also makes a fantastic base for others who want to do research on parts of an IPA system without needing to rebuild the whole thing. Secondly, we get implementations of the core algorithms across a number of hardware devices: multicore CPUs, GPUs, Intel Phi, and FPGAs. This enables the researchers to assess how well suited the different architectures are for IPA-style workloads. And finally, Hauswald et al. extrapolate these results to show us the implications for future datacenters as the number of ‘natural interface’ driven queries rises to represent increasing proportions of datacenter workloads.
Check out this short introductory video from the Sirius project website:
When it comes time to build the second-generation system, it simply has to be called “McEnroe” ;).
I have everything running in a Docker container based off of the ubuntu:14.04 base image, which was pretty straightforward – a couple of missing dependencies needed installing by hand, and I had to specify utf-8 encoding to build the question-answer component but otherwise things went smoothly. I’d push the resulting image back to the registry but with all the image db and wikipedia index files it runs to 10s of GBs…
Apple’s Siri, Google’s Google Now and Microsoft’s Cortana represent a class of emerging web-service applications known as Intelligent Personal Assistants (IPAs). An IPA is an application that uses inputs such as the user’s voice, vision (images), and contextual information to provide assistance by answering questions in natural language, making recommendations, and performing actions.
IPAs are emerging as one of the fastest growing internet services, and the rise of wearables which rely heavily on voice and image input will only accelerate this trend. IPAs use more natural forms of input, which makes each IPA request much more compute intensive to serve than a simple text-based query. Crucially, they also rely on access to large datasets, which makes it difficult to fully offload the computation to the client.
IPA queries stream through software components that leverage recent advances in speech recognition, natural language processing and computer vision to provide users a speech-driven and/or image-driven contextually-based question-and-answer system. Due to the computational intensity of these components and the large data-driven models they use, service providers house the required computation in massive datacenter platforms in lieu of performing the computation on the mobile devices themselves…. questions arise as to whether the current design employed by modern datacenters, composed of general-purpose servers, is suitable for emerging IPA work-loads.
One key result is that if we do stick with current designs for datacenters there is a large scalability gap between our current capacity and what will be needed as IPA style queries become ever increasing proportions of the workload:
the computational resources required for a single leaf query is in excess of 100x more than that of traditional Web Search.
Sirius is an open source IPA constructed to help explore these questions. It integrates best of breed speech, image, and question-and-answer sub-systems:
…the lack of a representative, publicly available, end-to-end IPA system proves prohibitive for investigating the design space of future accelerator-based server designs for this emerging workload. To address this challenge, we first construct an end-to-end standalone IPA service, Sirius, that implements the core functionalities of an IPA such as speech recognition, image matching, natural language processing and a question-and-answer system.
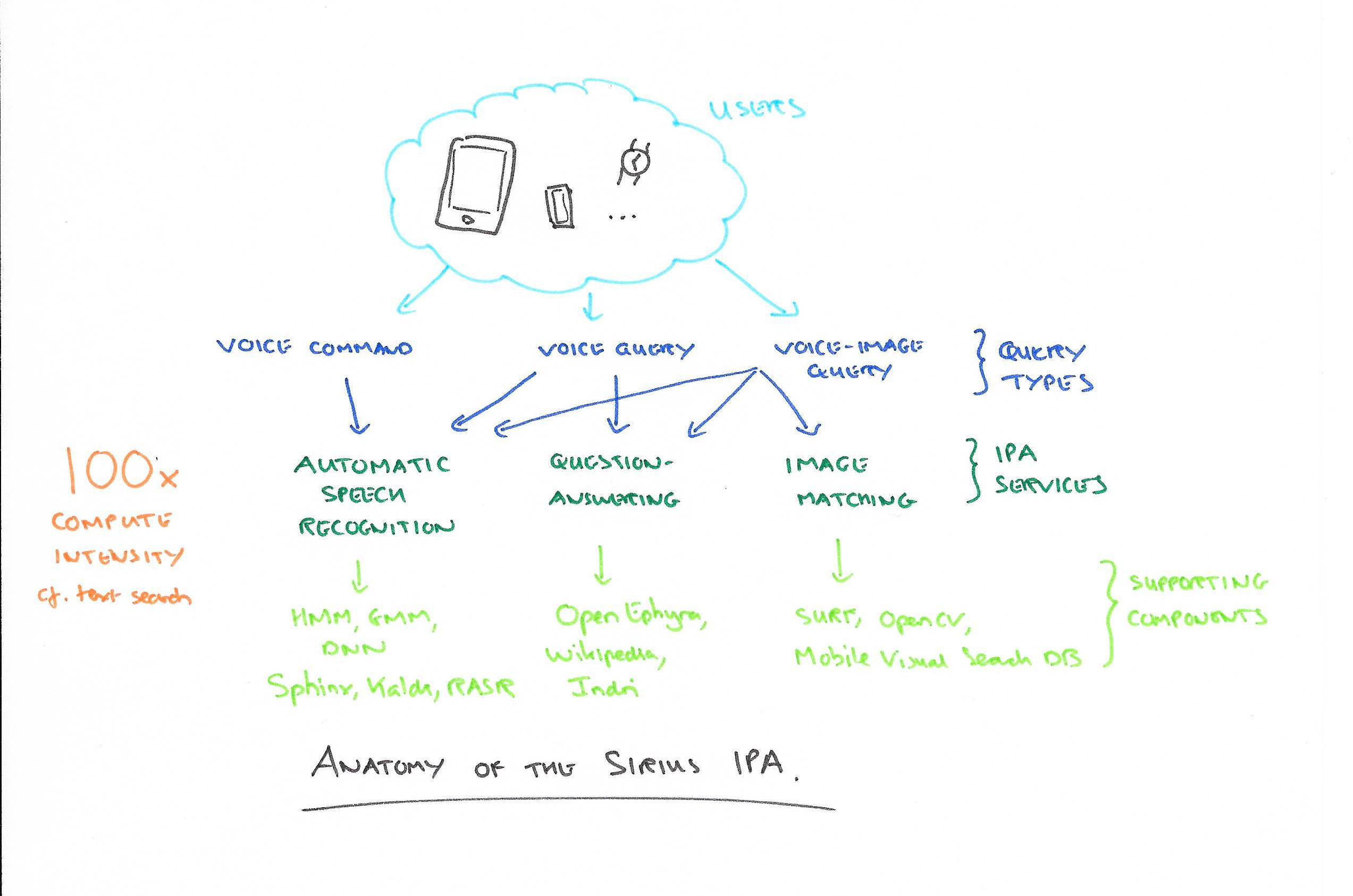
(sorry about the green, it’s more legible if you click to enlarge..)
- For Automatic Speech Recognition (ASR), Sirius combines Hidden Markov Models with either a Gaussian Mixture Model (GMM) or Deep Neural Nets (DNN). The GMM-based ASR is based on CMU’s Sphinx, and the DNN ASR includes Kaldi and RASR. This is the same combination of techniques as used by Google Voice:
In order to design Sirius to be representative of production grade systems, we leverage well-known open infrastructures that use the same algorithms as commercial applications. Speech recognition in Google Voice, for example, has used speaker-independent Gaussian Mixture Model (GMM) and Hidden Markov Model (HMM) and is adopting Deep Neural Networks (DNNs).
- For Image Recognition (IMM), Sirius uses the SURF algorithm implemented using the open source OpenCV library. This library is also used in commercial products from IBM, Microsoft, and Google. Sirius uses the Mobile Visual Search database to answer queries.
-
The OpenEphyra framework used for question-answering (QA) is an open-source release from CMU’s prior research collaboration with IBM on the Watson system. OpenEphyra’s NLP techniques, including conditional random field (CRF), have been recognized as state-of-the-art and are used at Google and in other industry question-answering systems. Sirius answers questions based on a Wikipedia index in Lemur’s Indri format.
What a wonderful collection of open source resources this represents!
With the Sirius system to hand, the authors perform a series of tests to uncover the computational load of IPA queries, and find that we are two orders of magnitude adrift:
current datacenter infrastructures will need to scale compute resources to 165x current size when the number of IPA queries scale to match the number of Web Search queries. We refer to this throughput difference as the scalability gap.
In order to understand what might be done to close this gap, the authors use Intel’s VTune to find hot spots for potential acceleration:
Across services, a few hot components emerge as good candidates for acceleration. For example, a high percentage of the execution for ASR is spent on scoring using either GMM or DNN. For QA, on average 85% of the cycles are spent in three components including stemming, regular expression pattern matching and CRF, and for IMM, the majority of cycles are spent either performing feature extraction or description using the SURF algorithm.
Looking at these bottlenecks, it turns out that the maximum speed-up we can expect on a general purpose processor is about 3x – well short of what is required to bridge the scalability gap. Therefore acceleration will be required. But what kind of acceleration?
A collection of benchmarks called the Sirius Suite (also available as part of the OSS) is developed in order to assess the suitability of multicore CPUs vs GPUs vs Intel Phi vs FPGAs.
- For Automatic Speech Recognition, in comparison to a single core baseline, the multicore gives between 3-6x improvement, GPU 55-70x, Intel Phi 1-11x, and FPGAs 110-169x.
- For Image Matching, the multicore gives a 5-6x speed-up, GPU 10-120x, Intel Phi 2-12x, and FPGA 35-76x.
- For Question Answering, the multicore gives a 4x speed-up, GPU 4-48x, Intel Phi 1-6x, and FPGA 7-169x.
(Variations in ranges above are for the different sub-algorithms involved in each process).
Across all services, the GPU and FPGA significantly reduce the query latency. For example, the FPGA implementation of ASR (GMM/HMM) reduces the speech recognition query latency from 4.2s to only 0.19s. The FPGA outperforms the GPU for most of the services except ASR (DNN/HMM). Although Intel Phi can reduce the latency over the single core baseline (CMP), Phi is generally slower than the Pthreaded multicore baseline.
FPGA is also the most energy efficient:
The FPGA has the best performance/watt, exceeding every other platform by a significant margin, with more than 12x energy efficiency over the baseline multicore. The GPU’s performance/watt is also higher than the baseline for 3 of 4 services. Its performance/watt is worse than the baseline for QA, mainly due to its moderate performance improvement for this service.
Based on the latency and energy efficiency trade-offs, the paper concludes by looking at the best overall datacenter architecture to support IPA workloads using a TCO model that also takes into account hardware costs etc. They look at homogeneous designs (same hw everywhere), and heterogeneous ones.
In conclusion, FPGAs and GPUs are the top 2 candidates for homogeneous accelerated datacenter designs across all three design objectives. An FPGA-accelerated datacenter allows DCs to minimize latency and maximize energy efficiency for most of the services and is the best homogeneous design option for those objectives. Its power efficiency is desirable for datacenters with power constraints, especially for augmenting existing filled datacenters that are equipped with capped power infrastructure support. It also improves TCO for all four services. On the other hand, FPGA-accelerated datacenters incur higher engineering cost than the rest of the platforms. For DCs where engineering cost needs to be under a certain constraint, GPU-accelerated homogeneous datacenters achieve relatively lowlatency and high throughput. They also achieve similar or higher TCO reduction than FPGA due to its low purchase cost. GPUs could be a desirable option over FPGAs when the high engineering overhead of FGPA implementation is a concern, especially given the quick workload churn (e.g., binaries are updated on the monthly basis) in modern datacenters.
It turns out that a heterogeneous design – partitioned to direct certain parts of the overall workload to the hardware best suited to it – does not add significant benefit, and certainly not enough to outweigh the operational advantages of homogeneous infrastructure.
I’m guessing the future will be GPU based. According to the results in this paper that should reduce IPA query latency by 10x on average, and the TCO by 2.6x.

2 thoughts on “Sirius: An open end-to-end voice and vision personal assistant and its implications for future warehouse scale computers”
Comments are closed.