Procella: unifying serving and analytical data at YouTube Chattopadhyay et al., VLDB’19
Academic papers aren’t usually set to music, but if they were the chorus of Queen’s “I want it all (and I want it now…)” seems appropriate here. Anchored in the primary use case of supporting Google’s YouTube business, what we’re looking at here could well be the future of data processing at Google. Well, I say the future, but “Procella has now been in production for multiple years. Today, it is deployed in over a dozen data centers and serves hundreds of billions of queries per day over tens of petabytes of data…” So maybe what we’re looking at is the future of data processing for the rest of us!
Google already has Dremel, Mesa, Photon, F1, PowerDrill, and Spanner, so why did they need yet another data processing system? Because they had too many data processing systems! 😉
Large organizations… are dealing with exploding data volume and increasing demand for data driven applications. Broadly, these can be categorized as: reporting and dashboarding, embedded statistics in pages, time-series monitoring, and ad-hoc analysis. Typically, organizations build specialized infrastructure for each of these use cases. This, however, creates silos of data and processing, and results in a complex, expensive, and harder to maintain infrastructure.
When each of those use cases is powered by a dedicated back-end, investments in better performance, improved scalability and efficiency etc. are divided. And given the growing scale of YouTube, some of those backend systems were starting to creak. Moreover, moving data between the different systems to support different use cases can lead to tricky ETL pipelines.
The big hairy audacious goal of Procella was to “implement a superset of capabilities required to address all of the four use cases… with high scale and performance, in a single product” (aka HTAP1). That’s hard for many reasons, including the differing trade-offs between throughput and latency that need to be made across the use cases.
Use cases
Reporting and dashboarding use cases (e.g. to understand YouTube video performance) drive tens of thousands of canned (known in advance) queries per second, that need to be served with latency in the tens of milliseconds. Each data source being queried over can add hundreds of billions of new rows every day. Oh, and in additional to low latency, “we require access to fresh data.”
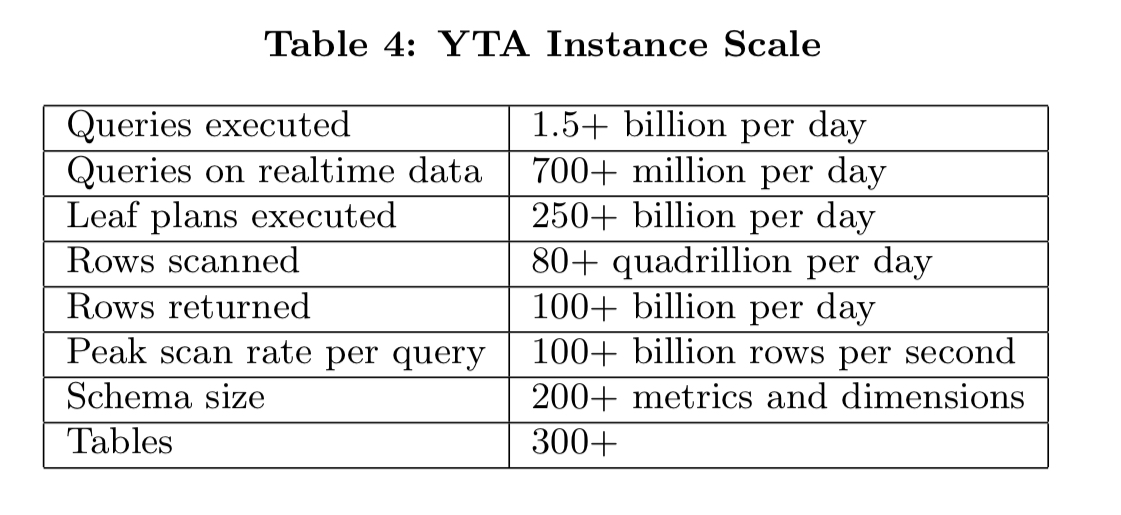
For just the YouTube Analytics application, we’re looking at metrics like this, with a 99%-ile latency of 412ms:
Embedded statistics use cases include the various counters such as views, likes, and subscriptions that are included in pages. Here the query volumes run to hundreds of billions of queries per day, with millisecond latency requirements (Procella achieves 99%-ile latency of 3.3ms here).
Time-series monitoring workloads have similar properties to dashboarding (relatively simple canned queries, but a need for fresh data). Additional query features such as approximation and dedicated time-series functions are needed here too.
Ad-hoc analysis use cases support internal teams performing complex ad-hoc analyses to understand usage trends and determine how to improve products. These are comparatively lower volume queries with moderate latency requirements, but they can be complex and the query patterns are highly unpredictable.
Procella system overview
The paper covers a lot of territory. In this write-up we’ll look at some of the high-level architectural principles, and then I’m going to cherry-pick details relating to how Procella achieves its performance, latency, and data freshness goals.
To its clients, Procella is a SQL query engine (SQL-all-the-things). Under the covers, it’s a sophisticated distributed system built on the tenets of cloud-native systems:
- Disaggregated (remote) storage, with read or write operations performed via RPCs, and immutable data (append only files).
- Shared compute tier designed to scale horizontally with many small tasks rather than a small number of large tasks. (Little or) no local state.
- Fast recovery from the loss of any single machine
- Sophisticated strategies for handling stragglers, badly behaving tasks, and periodic unavailability
The big picture looks like this:
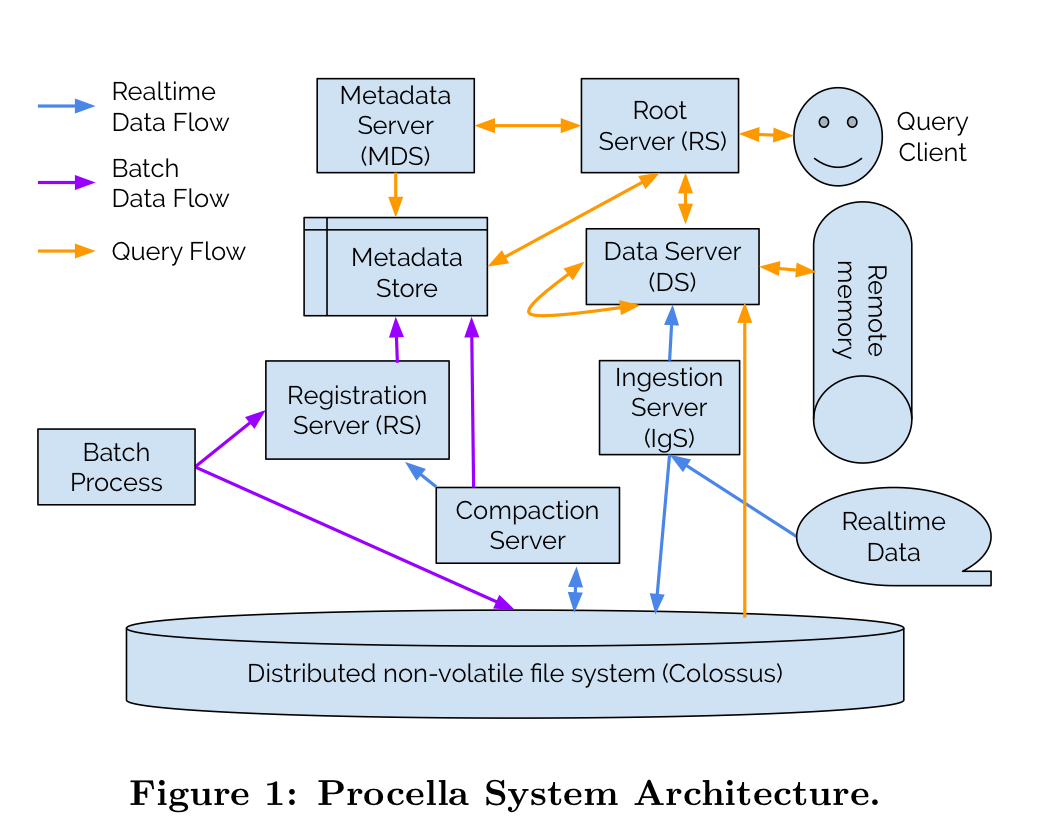
Taken together, these principles enable Procella to scale, but achieving the desired levels of performance while supporting “an almost complete implementation of standard SQL, including complex multi-stage joins, analytic functions and set operations, with several useful extensions such as approximate aggregations, handling complex nested and repeated schemas, user-defined functions, and more” is a whole other challenge. Let’s now take a look at some of the things that help to make Procella fast.
Making Procella fast
Cache all the things
Procella achieves high scalability and efficiency by segregating storage (in Colossus) from compute (on Borg). However, this imposes significant overheads for reading or even opening files, since multiple RPCs are involved for each. Procella employs multiple caches to mitigate this networking penalty.
The nice thing though about files that are immutable once closed is that you don’t have to worry about cache invalidation.
Procella agressively caches metadata, columnar file headers, and columnar data (using a newly developed data format, Artus, that gives data the same representation on disk and in memory). Given sufficient memory, Procella can essentially become an in-memory database. For their reporting instance, only about 2% of all data can fit in memory, but the system still achieves a 99%+ file handle cache hit rate, and a 90% data cache hit rate.
One of the secrets to those high hit rates is affinity scheduling. Requests to data servers and metadata servers are routed such that operations on the same data/metadata go the the same server with high probability. Another feature of the storage layer, the fact that all data is available from anywhere, means that the affinity scheduling is an optimisation and requests can still be served if they do end up being routed elsewhere for some reason.
Heavily optimise and pre-compute data formats
Since Procella aims to cover [large scans typical in ad-hoc analysis workloads] and several other use cases requiring fast lookups and range scans, we built a new columnar file format called Artus, which is designed for high performance on both lookups and scans.
We could really do with a dedicated paper just on Artus itself, but here are some of the highlights.
- Heavy use of custom encodings, instead of generic compression algorithms such as LZW.
- Multi-pass encoding, with a first fast pass to understand the shape of the data (e.g. number of distinct values, range, sort order etc.), followed by selection of an optimal encoding strategy, and then a second pass that does the full encoding using the selected strategy.
Artus uses a variety of methods to encode data: dictionary and indexer types, run-length, delta, etc. to achieve compression within 2x of strong general string compression (e.g. ZSTD) while still being able to directly operate on the data. Each encoding has estimation methods for how small and fast it will be on the data supplied. (Emphasis mine).
- For sorted columns, Artus’ encodings allow fast lookups in
time, with
seeks to a given row number.
- For nested and repeated data types Artus uses a novel tree representation that notes whether a given field occurs, and eliminates any subtree below a missing parent field.
- Artus exposes encoding information such as dictionary indices and run-length encoding information to the evaluation engine, and can support some filtering operations directly within its API. “This allows us to aggressively push such computations down to the data format, resulting in large performance gains in many common cases.“
- Keeps rich metadata in file and column headers (sort order, min and max, detailing encoding information, bloom filters, and so on), making many pruning operations possible without the need to read the actual data in the column.
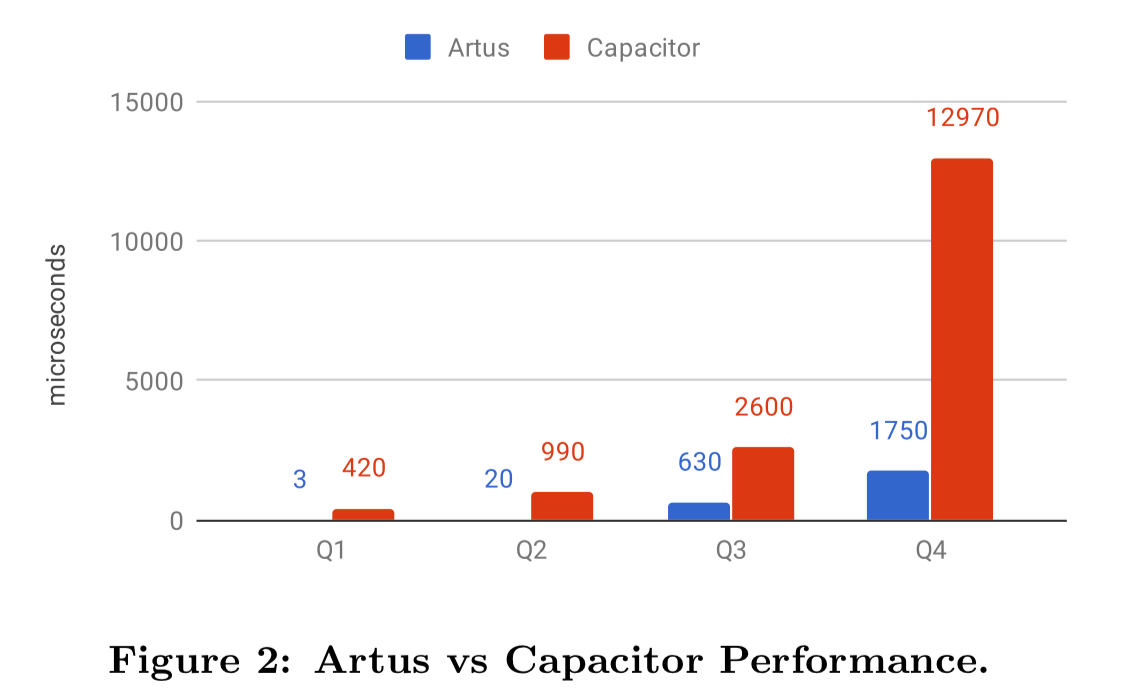
Evaluated over four typical YouTube Analytics query patterns, here are the performance and memory consumption figures for Artus vs Capacitor, Google BigQuery’s columnar storage format.

Adaptation and compilation
High performance evaluation is critical for low latency queries. Many modern analytical systems today achieve this by using LLVM to compile the execution plan to native code at query time. However, Procella needs to serve both analytical and high QPS serving use cases, and for the latter, the compilation time can often become the bottleneck. The Procella evaluation engine, Superluminal, takes a different approach…
Superluminal makes extensive use of C++ template metaprogramming and operates on the underlying data encodings natively. No intermediate representations are materialized.
The query optimiser then combines both static and dynamic (adaptive) query optimisation techniques. A rule-based optimiser applies standard logical rewrites. Then when the query is running Procella gathers statistics based on a sample of the actual data used in the query, and uses these to determine what to do next.
Adaptive techniques have enabled powerful optimizations hard to achieve with traditional cost-based optimizers, while greatly simplifying our system, as we do not have to collect and maintain statistics on the data (especially hard when ingesting data at a very high rate) and we do not have to build complex estimation models that will likely be useful only for a limited subset of queries.
Aggregation, join, and sort strategies are all adapted at runtime based on ongoing learnings during query execution. For queries with strict low latency targets it’s possible to fully define the execution strategy up front and turn off the adaptive optimiser.
Do the least work possible, and do the work in the best place possible
As well as pushing computation down to the leaves as far as possible, Procella also has a variety of join strategies to make distributed joins as efficient as possible. I’m out of space to describe them all here, but you’ll find a good short summary in §3.5 of the paper.
For heavy aggregations, Procella adds intermediate aggregation operators at the input of the final aggregation to prevent it becoming a bottleneck.
And there’s more!
There’s a lot of additional information in the full paper that I didn’t get to cover. If this topic interests you, it’s well worth a read…
- HTAP: Hybrid Transaction/Analytic Processing ↩