The convoy phenomenon Blasgen et al., IBM Research Report 1977 (revised 1979)
Today we’re jumping from HotOS topics of 2019, to hot topics of 1977! With thanks to Pat Helland for the recommendation, and with Jim Gray as one of the authors, we have a combination that’s very hard to ignore :).
Here’s the set-up as relayed to me by Pat (with permission):
At work, I am part of a good sized team working on a large system implementation. One of the very senior engineers with 25+ years experience mentioned a problem with the system. It seems that under test load, it would behave beautifully until the performance just fell to the floor. The system just crawled forever and never seemed to get out of this state. Work was getting done but at a pathetic rate. I said: “You have a convoy.” His response was; “Huh?”. I forwarded him the paper on “The Convoy Phenomenon”…
I have to confess I hadn’t heard of the convoy phenomenon either! Before we go on, take a moment to think of possible causes for the system behaviour described above. Lots of things can cause a performance cliff, but the interesting thing here is that the system never recovers. That’s suggestive to me of a queue where queue depth has increased and service and arrival times are finely balanced, so we’re always seeing long wait times. (In such a situation I’d expect to see unusually high latencies, but normal throughput). I was only partially right (there is a steady-state queue involved)… Plus, although it’s not described, the performance degradation observed in this case would almost certainly be poor latency and poor throughput.
What is a convoy and why do they form?
When driving on a two-lane road with no passing one often encounters clusters of cars. This is because a fast-moving car will soon bump into a slow one. The equilibrium state of such a system is for everyone to be in a convoy behind the slowest car.
On English B-roads one of the most common causes for this is a tractor moving between fields on the public highway. And Dorset (maybe other English counties too, but definitely Dorset) seems to have a penchant for Steam Engine rallies in the summer (e.g. ‘The Great Dorset Steam Fair’), which are a bit like a distributed denial of service attack on the road network as lots of very slow steam engines all converge on a given point.
But enough about tractors and steam engines! Processes (or in the case of System R, transactions) can also bump into each other when contending for shared resources. “This contention appears as conflicting requests for locks.”
We know that both contention and coherence are scalability killers, but we still have to explain why the performance never recovers.
The duration of a lock is the average number of instructions executed while the lock is held. The execution interval of a lock is the average number of instructions executed between successive requests for that lock by a process. The collision cross section of the lock is the fraction of time it is granted, i.e., the lock grant probability. With a single processor this is just duration / (duration + execution interval) to a first approximation (ignoring wait times and switching times).
The high-traffic, lock-protected resources in System R are the buffer pool, recovery log, and system entry/exit. Here are their respective stats:

If a process P1 goes into a wait state while it holds a high traffic lock L (e.g. for a buffer pool) then all other processes will be scheduled and will more or less immediately request L (it’s a high traffic lock remember). Each transaction finds the lock L busy, and so it waits for it. Now P1 which holds the lock is sleeping, and all the other processes are waiting for the lock that P1 holds:
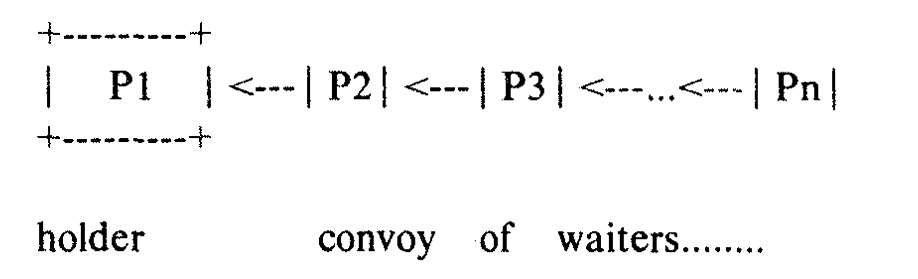
That already looks bad, but it turns out to be a trap from which the system finds it very hard to escape:
- The system sleeps until P1 wakes up
- P1 runs and releases L (after say 100 instructions)
- P2 is granted L by P1
- P1 executes 1000 instructions (the buffer pool execution interval) more and then
- P1 requests L (again) but L is busy (because there are many processes ahead of P1 in the queue and not all of these processes will be dispatched before P1 re-requests L)
- P1 enqueues on the lock and goes to sleep
With N processes and M processors, where N is much bigger than M, the lock queue will contain N-M processes and each process will have a execution interval of 1000 instructions.
The system is in a situation of lock thrashing. Most of the CPU is dedicated to task switching. This is a stable phenomenon: new processes are sucked into the convoy and if a process leaves the convoy (for I/O wait or lock wait), when it returns the convoy will probably still exist.
Don’t sleep while holding a lock!
As of 1977, convoys had been observed in System R, MVS, and IMS. System R code followed the following rules:
- Never lock wait while a high traffic lock is held
- Never do I/O while a high traffic lock is held (the log lock was an occasional exception)
- Never page fault while a high traffic lock is held
If you’re in control of process scheduling then you can greatly reduce the probability of being caught out holding a high traffic lock. But you still won’t reduce that probability to zero, and given the high consequences when it does occur that’s still a problem. But moreover…
Most of us are stuck with a pre-emptive scheduler (i.e., general purpose operating system with virtual memory). Hence convoys will occur. The problem is to make them evaporate quickly when they do occur rather than have them persist forever.
Breaking up the convoy
A trivial solution would be to only run one process at a time, that way there can’t be any lock contention. However, there’s an obvious scalability issue with that!
The next simplest solution is to avoid locks. One can go a very long way with shrewd use of atomic machine instructions (compare and swap) and other programming tasks…. we have done a lot of this, but we were unable to completely eliminate high traffic locks from our programs.
If we have to have locks, we can try to minimise contention by reducing increasing lock granularity (e.g. row locks not table locks), and the lock mode (e.g. non-exclusive locks). This will help to make convoys less likely and less stable, but it probably won’t eliminate them.
The System R team also experimented with spin locks, but the CPU wastage turned out to be worse than than caused by the convoys.
Using these techniques System R reduced lock waits on high traffic locks by a factor of ten, and only 40% of lock waits (down from 92%) were for high traffic locks.
So how did System R solve it in the end?
The key issue of convoys is associated with the granting of locks in first-come first-served order. So we elect to grant all lock requests in random order in the hope that eventually everyone will get service. In theory, some process might ‘starve’ (never be granted its request) but in fact the underlying scheduler and the stochastic nature of real systems cause each process to eventually get service.
Note that we’re talking about adding some randomness to which waiter on a given lock gets access next, not changing the order in which a given process acquires its locks – that way leads to deadlocks!
Given a single processor, if a convoy exists when a high contention lock is released then the releasor dequeues all members of the convoy from the lock, marks the lock as free, and then signals all members of the convoy. The releaser then continues to run, and with high probability (lets call that P) will terminate with the lock free. Whichever of the signalled processes runs next will be able to acquire the lock (there is no queue on it). With N processes in the convoy, it will disappear with probability P^N.
In the multi-processor case another processor may look to acquire the lock during a critical section. Here the solution is for the lock requestor to spin for a few instructions in the hope that the lock becomes free, and then enqueue and sleep if it does not.
About that slow system…
So let’s go back to our opening story and see how it turned out…
The next day I was told that our system did, indeed, have a convoy and the solution was simple.