Fast key-value stores: an idea whose time has come and gone Adya et al., HotOS’19
No controversy here! Adya et al. would like you to stop using Memcached and Redis, and start building 11-factor apps. Factor VI in the 12-factor app manifesto, “Execute the app as one or more stateless processes,” to be dropped and replaced with “Execute the app as one or more stateful processes.”
It all makes for a highly engaging position paper (even if that engagement doesn’t necessarily take the form of agreement on all points)! It’s healthy to challenge the status-quo from time to time…
Remote, in-memory key-value (RInK) stores such as Memcached and Redis are widely used in industry and are an active area of academic research. Coupled with stateless application servers to execute business logic and a database-like system to provide persistent storage, they form a core component of popular data center service archictectures. We argue that the time of the RInK store has come and and gone…
What on earth are they thinking? 😉
Why are developers using RInK systems as part of their design? Generally to cache data (including non-persistent data that never sees a backing store), to share non-persistent data across application services (e.g. session state that you want to survive an application process crash), and to keep the application server/services layer stateless.
Keeping application services stateless is a design guideline that achieved widespread adoption following the publication of the 12-factor app manifesto. Specifically, the sixth factor says “Execute the app as one or more stateless processes.” Even re-reading that today, the letter of the law there is surprisingly strict to me: you can use the local memory space or filesystem as a brief single transaction cache, but no more. If you want to store time-expiring data that should be shared across application processes, used Memcached or Redis. TBH, I never interpreted it quite so strictly. I think it’s absolutely fine to use the local memory space or filesystem as a local cache of data that spans transactions so long as that doesn’t introduce stickiness, consistency or stale data issues. After all, we’ve been doing that forever with the 2nd-level cache of ORMs, and it is highly encouraged in e.g. the AWS Lambda programming model — which was born on the cloud— to help mitigate function start-up times. I say go ahead and use local state as a performance boost, so long as you’re fine to have that state wiped out at any moment.
The stateless + RInk (S+RInK) architecture attempts to provide the best of both worlds: to simultaneously offer both the implementation and operational simplicity of stateless application servers and the performance benefits of servers caching state in RAM.
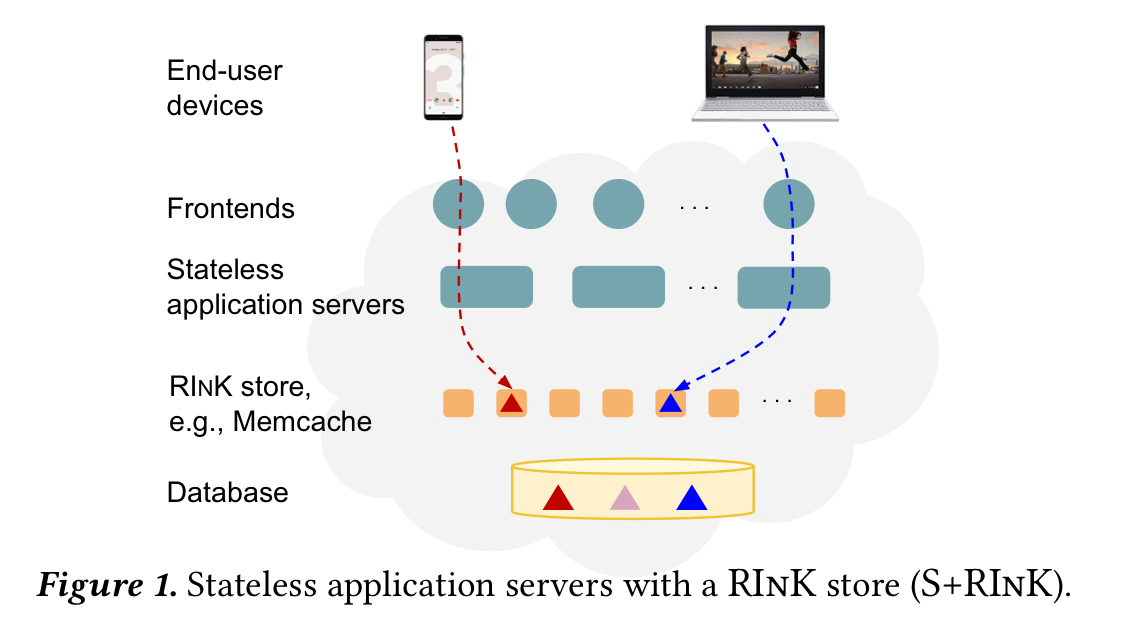
What have the authors got against this combination?
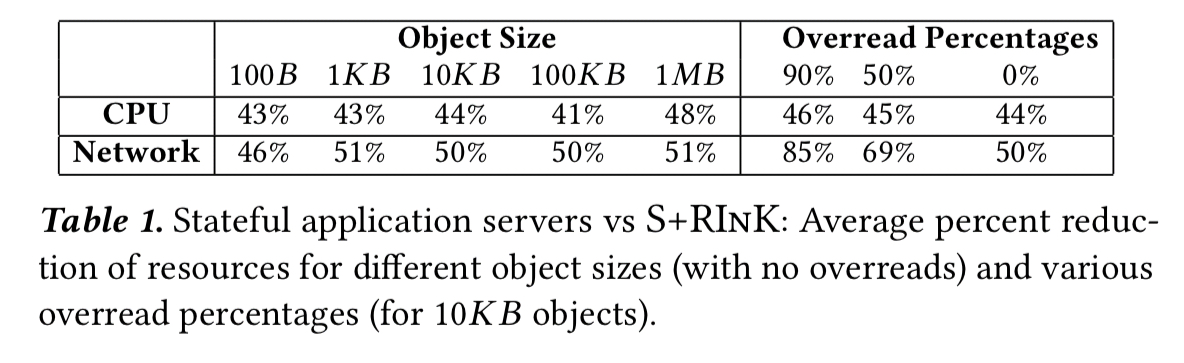
- A high CPU cost due to marshalling data to/from the RInK store formats to the application data format. In ProtoCache (a component of a widely used Google application), 27% of its latency when using a traditional S+RInK design came from marshalling/un-marshalling. (We’ve seen similar high marshalling overheads in big data systems too.)
- Fetching too much data in a single query (i.e., getting the whole value when you supply the key). If you decompose data across multiple keys to avoid this, you then typically run into cross-key atomicity issues. In ProtoCache at the 99th %-ile, only 2% of the size of the total item value is required to answer a common query. You pay a double price for fetching more data than you really need, because you’ll be consuming CPU un-marshalling it too.
- The network latency of fetching data over the network, even considering fast data center networks. Over and above RTT times, the size of the data to be transferred also matters.
Systems such as FaRM and KV-Direct focus on improving the performance of PUT/GET operations, but don’t address the authors’ marshalling and overread concerns.
We argue that RInK stores should not be used when implementing scalable data center services.
A rule that hard and fast seems just as likely to be wrong as a strict interpretation of factor six from the 12-factor app guidelines is. So I’m going to soften it and say the authors see use cases where we shouldn’t just jump to an S+RInK architecture but could consider doing something else instead.
What is that something?
Oh, you mean a cache?
The first part of their proposed alternative is to use a local (in-process) in-memory store instead of a RInK. Yes, a bit like those 2nd-level caches we were talking about earlier, e.g. Ehcache from 2003 onwards. This eliminates marshalling costs to reduce CPU usage, and eliminates network latency. Who knew! ;). Embedded databases such as Apache Derby would also fit here in my mind, although then you still have some marshalling to do. Or how about an in-memory data grid with client-side caching (e.g. Hazelcast’s near-cache support)?
In ProtoCache, replacing the RInK with stateful application servers resulted in a 29-57% median latency improvement and 40%+ reduction in CPU.
As a half-way house you could also design a domain specific service API sitting in front of an in-memory cache. This is useful when you need to share data across application processes:
For example, a calendar service might cache user calendars and expose a
find-free-slotsAPI to find the free timeslots for a particular user on a given day, which would be less expensive than requiring an application to fetch the entirety of a user’s calendar.
Did we just rediscover microservices here??
…a stateful application server or a stateless application server with a domain-specific cache will always offer equal or better latency, efficiency, and scalability than a RInK based approach, since these architectures can trivially mimic it.
From RInK to LInK
There’s a missing piece in the proposal to move to stateful application servers so far:
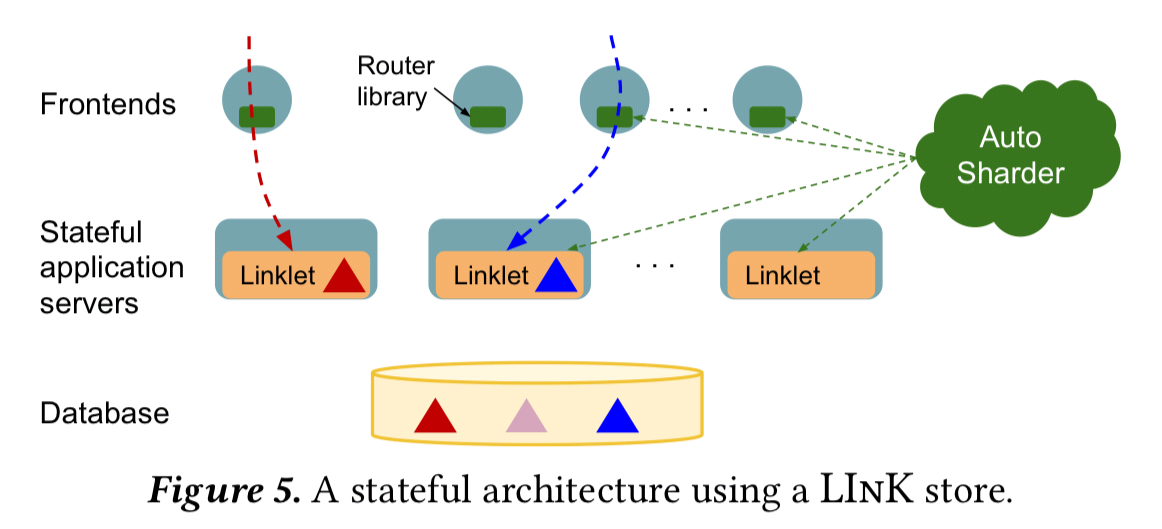
…without the ability to react to server failures and to changes in workload (e.g., hot keys), deploying stateful application servers at scale is not practical.
Google has Slicer, an auto-sharding system, but Slicer on its own still leaves many important problems unsolved: replication, consistency, cache-invalidation and so on. (At this point in the paper, §4, the penny finally drops as to where the authors are coming from… Adya and Myers both worked on Slicer!).
To address these application needs, we propose a new abstraction, which by analogy with RInK we call a LInK store, for linked in-memory key-value store. A LInK store is a high level abstraction over an auto-sharder that provides a distributed, in-memory, key-value map with rich application objects as values, rather than strings or simple data structures…
AFAICT, a LInK store is an in-memory data grid where the nodes of the grid run embedded in application processes, and the stored objects are native application objects. Serialization only occurs if/when the LInK store needs to move/copy an object over the network (e.g. for replication or re-balancing).
OK, but…
A couple of points raised in the paper:
- As soon as you need replication, you’ve re-introduced all of the marshalling and un-marshalling costs you were hoping to avoid. (Unless you go a whole different route and use state-machine replication or a materialized view approach over event sourcing).
- LInKing the state and grid node implementation directly into the application increases resource demands for application nodes, makes supporting multiple applications much harder, and makes it difficult to rollout LInK store bug fixes as every application node needs to be redeployed.
And a few of my own:
- With frequent application deploys, it often makes sense to have cached state separate from the application process to avoid expensive cold starts. E.g., even at a departmental app level, one of my apps uses a RInK store (Redis) to cache rendered page fragments, and I don’t want to lose those on a deploy.
- Rolling out a new version of an app that includes changes to LInK’d objects seems pretty tricky
- Projections allow us to avoid overreads with many data stores (e.g. SELECT in SQL!), or GraphQL as an example at the other end of the spectrum.
- Cap’n Proto or FlatBuffers could help to reduce those marshalling overheads
How to summarise my thoughts here?
- Sometimes it makes sense to use a RInK, but understand why you’re doing it
- For many uses cases, a local in-memory cache sitting in front of the database is just fine. Don’t let the letter of the 12-factor law put you off here. For many web applications, turning this on is mostly just configuration. See e.g. ‘caching data with Spring.’
- If you need more than that, why not try an in-memory data grid that offers client-side cache integration? Yes, Google seem to be custom building their own LInK store (“We have built a prototype, and one production team is currently implementing an application using it…“), but that almost certainly doesn’t make sense for you!
Horses for courses!
There’s a prior HN discussion thread about this paper as well.