Keeping master green at scale Ananthanarayanan et al., EuroSys’19
This paper provides a fascinating look at a key part of Uber’s software delivery machine. With a monorepo, and many thousands of engineers concurrently committing changes, keeping the build green, and keeping commit-to-live latencies low, is a major challenge.
This paper introduces a change management system called SubmitQueue that is responsible for continuous integration of changes into the mainline at scale while always keeping the mainline green.
The challenge: build fails at scale
Each individual submitted change will have passed all local tests, but when you put large numbers of concurrent changes together conflicts can still happen. Finding out what’s gone wrong is a tedious and error-prone task often requiring human intervention. Meanwhile, new features are blocked from rolling out.
So the goal is to keep it green:
…the monorepo mainline needs to remain green at all times. A mainline is called green if all build steps (e.g., compilation, unit tests, UI tests) can successfully execute for every commit point in the history. Keeping the mainline green allows developers to (i) instantly release new features from any commit point in the mainline, (ii) roll back to any previously committed change, and not necessarily to the last working version, and (iii) always develop against the most recent and healthy version of the monorepo.
Here’s 9 months of data for the Uber iOS and Android repos, showing the probability of conflicts as the number of concurrent changes increases:

At ‘only’ 16 concurrent and potentially conflicting changes, there’s a 40% chance of a problem. Thus, “despite all efforts to minimize mainline breakages, it is very likely that the mainline experiences daily breakages due to the sheer volume of everyday code changes committed to a big monorepo.”
And that’s exactly what Uber saw. Here’s a one week view of the iOS mainline prior to the introduction of SubmitQueue. The mainline was green only 52% of the time.
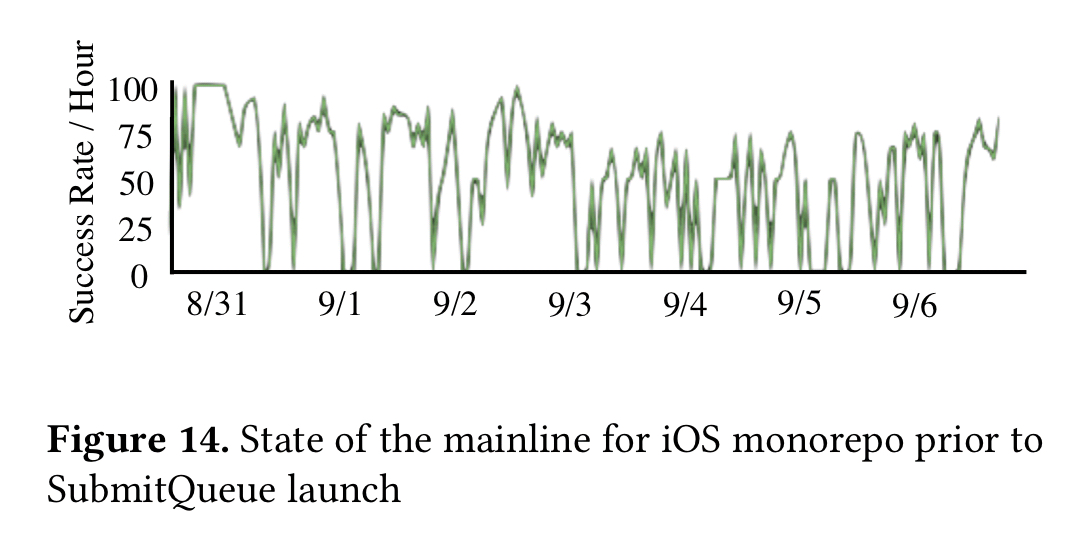
(Since the introduction of SubmitQueue over a year ago, mainlines have remained green at all times).
To keep the mainline green we need to totally order changes and only apply patches to mainline HEAD if all build steps succeed.
The simplest solution to keep the mainline green is to enqueue every change that gets submitted to the system. A change at the head of the queue gets committed into the mainline if its build steps succeed. For instance, the rustproject uses this technique to ensure that the mainline remains healthy all the time. This approach does not scale as the number of changes grows. For instance, with a thousand changes per day, where each change takes 30 minutes to pass all build steps, the turnaround time of the last enqueued change will be over 20 days.
20 day turnarounds clearly is not going to lead to a high performing organisation! One possible solution to reduce the latency is batching changes, but then we’re back at the problem of conflicts and complex manual resolution if we’re not careful. Another tactic is optimistic execution – given enough compute we can start builds in parallel on, with the assumption that all pending changes submitted will succeed. This approach suffers from high failure rates and turnaround times still though as failure of a change can abort many optimistically executing builds.
SubmitQueue
Uber’s solution to these challenges is SubmitQueue.
SubmitQueue guarantees an always green mainline by providing the illusion of a single queue where every change gets enqueued, performs all its build steps, and ultimately gets merged with the mainline branch if all build steps succeed.
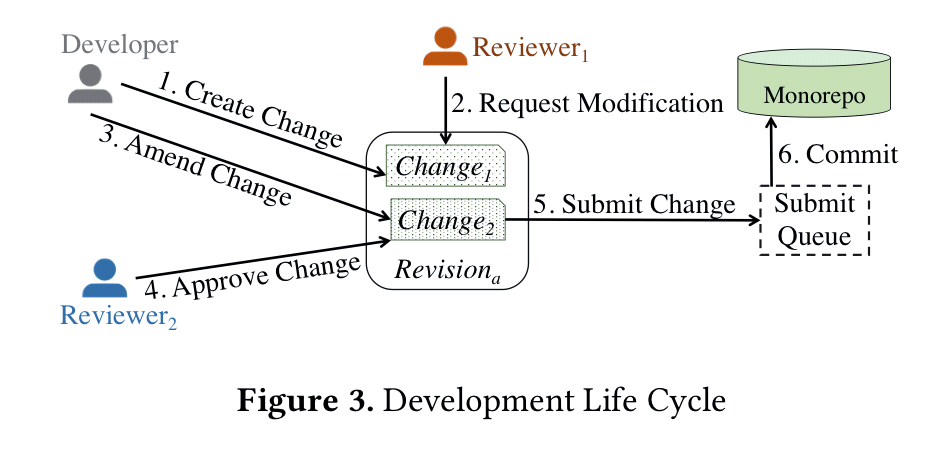
Developers create changes, which pending a review process are packaged into a revision. Revisions are submitted to the SubmitQueue for integration into the monorepo.
SubmitQueue’s planner engine orchestrates executions of ending changes.
In order to scale to thousands of changes per day while ensuring serializability, the planner engine speculates on outcomes of pending changes using a speculation engine, and executes their corresponding builds in parallel by using a build controller.
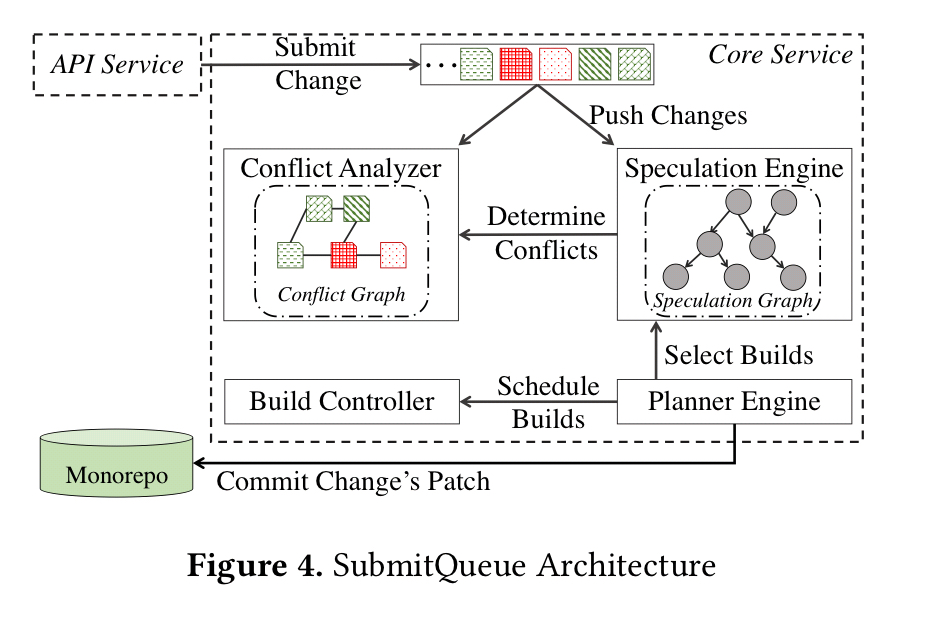
The planner periodically asks the speculation engine for the builds most likely to succeed. The speculation engine in turn uses a probabilistic model to compute the likelihood of a given build passing. At each epoch the planner schedules execution of the selected builds and stops execution of any currently running builds not included in the new schedule. Once it is safe to do so, the planner commits change patches to the monorepo. When distributing work among worker nodes, the planner tries to ensure a uniform distribution. To this end, it keep a history of build steps performed together with their average build durations.
The key challenge is to determine which set of builds we need to run in parallel, in order to improve turnaround time and throughput, while ensuring an always green mainline. To this end, the speculation engine builds a binary decision tree, called a speculation tree, annotated with prediction probabilities for each edge.
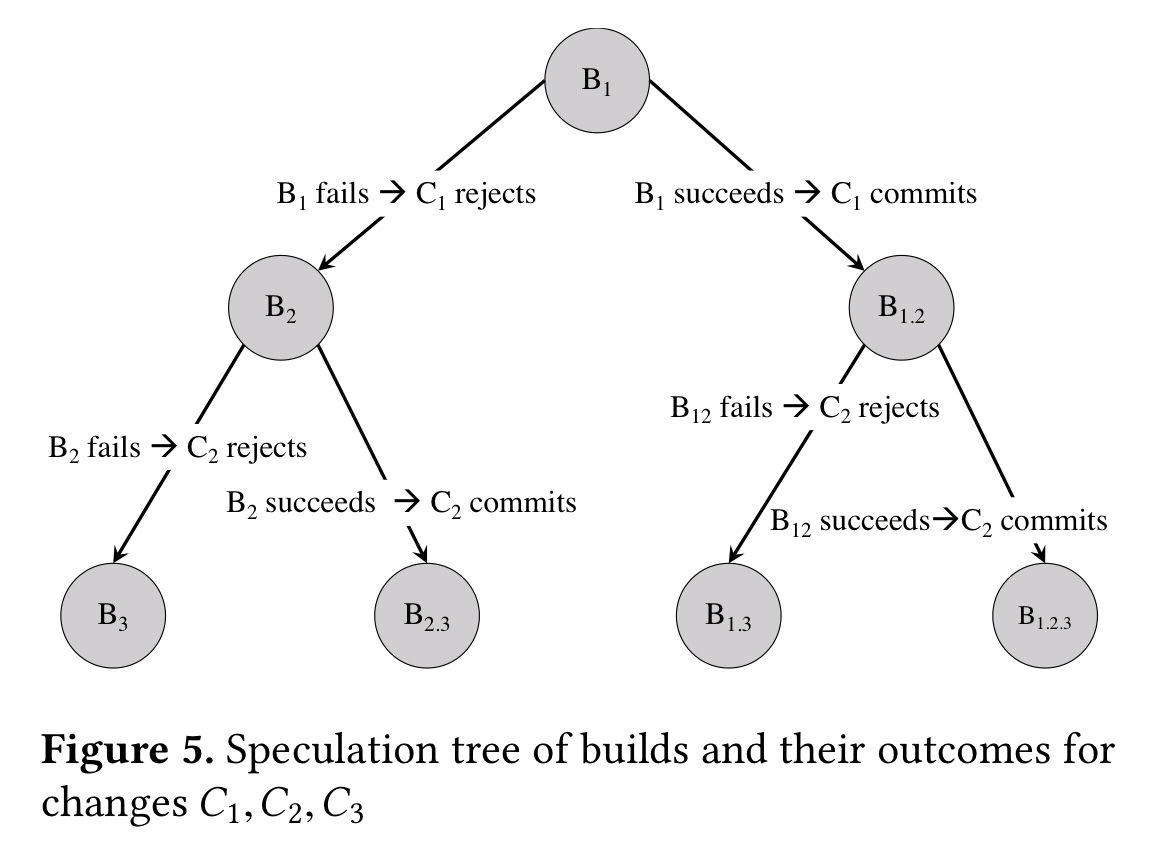
The model selects builds based on their predicted value – which is a combination of likelihood of success and change priority (e.g. , security patches may have higher values). In the current implementation, all builds are given the same priority (benefit) value.
When we include independent changes in the mix, the speculation tree can become a speculation graph. This enables independent changes to be committed in parallel. To determine independence, we need to know if changes conflict with each other.
In order to build a conflict graph among pending changes, the conflict analyzer relies on the build system. A build system partitions the code into smaller entities called targets… Roughly speaking, two changes conflict if they both affect a common set of build targets.
Every build target is associated with a unique target hash that represents its current state (a bit like a Merkle tree, this is the result of combining the hashes of all the inputs to the build of that target).
Predicting success
We trained our success prediction models in a supervised manner using logistic regression. We selected historical changes that went through SubmitQueue along with their final results for this purpose. We then extracted around 100 handpicked features.
The trained model achieved 97% accuracy. The features with the highest positive correlation scores were:
- The number of successful speculations so far
- Revision and revert test plans included as part of the submission
- The number of initial tests that succeeded before submitting a change
The strongest negative correlations were with the number of failed speculations, and the number of times changes were submitted to a revision.
We also note that while developer features such as the developer name had high predictive power, the correlation varied based on different developers.
Evaluation
Taken in isolation, an iOS or Android build at Uber takes around 30-60 minutes:
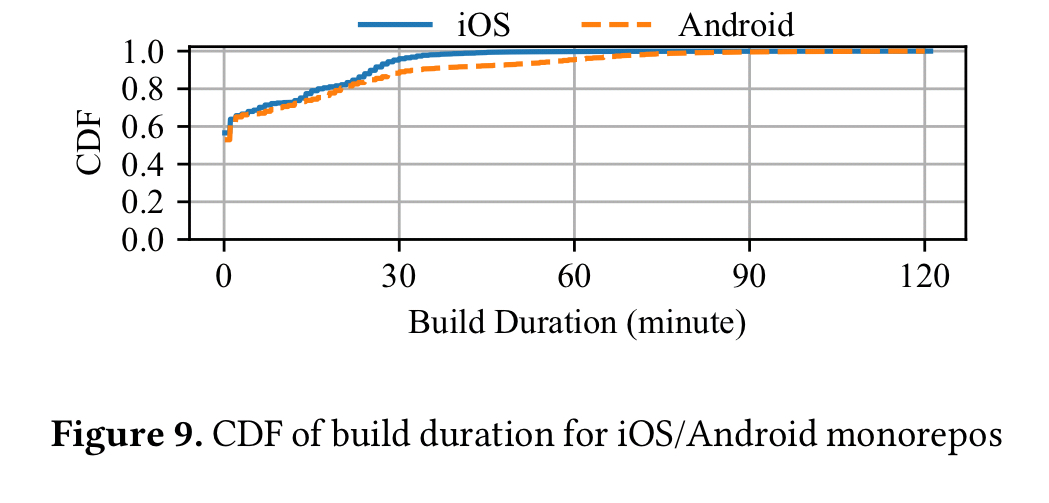
When considering concurrent changes, and given an Oracle able to make perfect predictions, the turnaround times for builds looks like this:
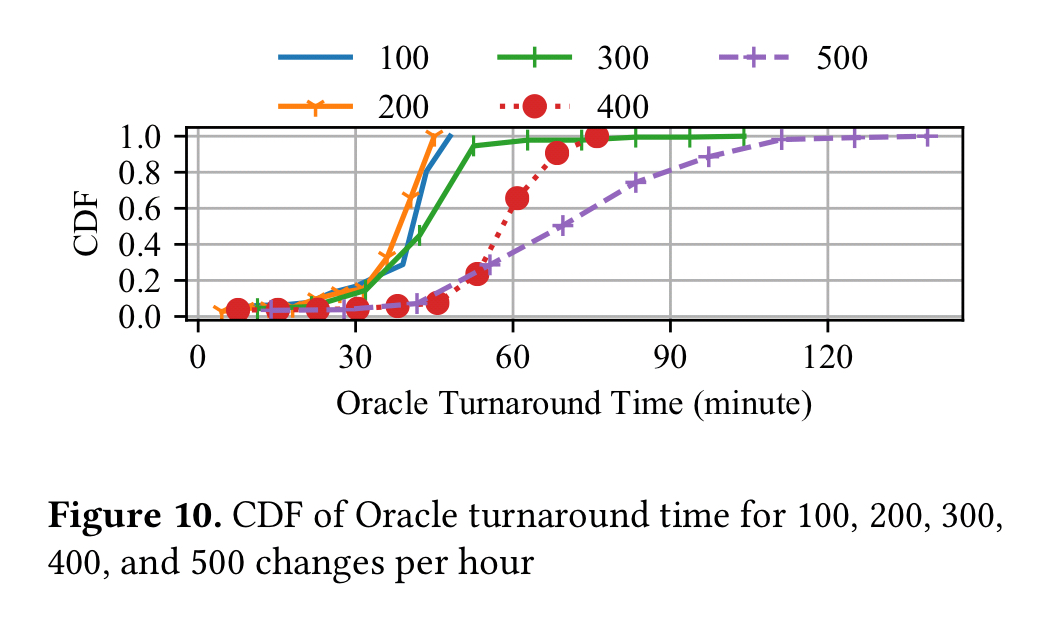
(Each plot line shows a different number of changes per hour coming into the system).
With n changes per hour, and n worker nodes available, SubmitQueue can achieve a turnaround time with 1.2x of the Oracle.
Future work
The current version of SubmitQueue respects the order in which changes are submitted to the system. Thus small changes can be backed up behind larger ones. Future work will include re-ordering of non-independent changes to improve throughput. Another optimisation to be explored is batching independent changes expected to succeed together before running their build steps. This will enable Uber to make trade-offs between cost and turnaround time.