Time protection: the missing OS abstraction Ge et al., EuroSys’19
Ever since the prominent emergence of timing-based microarchitectural attacks (e.g. Spectre, Meltdown, and friends) I’ve been wondering what we can do about them. When a side-channel is based on observing improved performance, a solution that removes the improved performance can work, but is clearly undesirable. In today’s paper choice, for which the authors won a best paper award at EuroSys’19 last month, Ge et al., set out a principled basis for protecting against this class of attacks. Just as today’s systems offer memory protection, they call this time protection. The paper sets out what we can do in software given today’s hardware, and along the way also highlights areas where cooperation from hardware will be needed in the future.
Timing channels, and in particular microarchitectural channels, which exploit timing variations due to shared use of caches and other hardware, remain a fundamental OS security challenge that has eluded a comprehensive solution to date… We argue that it is time to take temporal isolation seriously, and make the OS responsible for time protection, the prevention of temporal inference, just as memory protection prevents spatial inference.
If padding all the things to make execution consistently as slow as the slowest path isn’t a desirable solution, then the other avenue we are left to explore is the elimination of sharing of hardware resources that are the underlying cause of timing channels.
Microarchitectural channels
Microarchitectural timing channels result from competition for hardware resources that are functionally transparent to software… the [ISA] abstraction leaks, as it affects observable execution speed, leading to timing channels.
Microarchitectural state of interest includes data and instruction caches, TLBs, branch predictors, instruction- and data-prefetcher state machines, and DRAM row buffers. There are also stateless interconnects including buses and on-chip networks.
A covert cache-based channel (for example) can be built by the sender modulating its footprint in the cache through its execution, and the receiver probing this footprint by systematically touching cache lines and measuring memory latency and by observing its own execution speed. (Side-channels are similar, but the sender does not actively cooperate).
A covert channel can be built over a stateless interconnect in a similar manner by the sender encoding information in its bandwidth consumption, and the receiver sensing the available bandwidth.
Threat scenarios
The hardware support is not currently available to prevent interconnects being used as covert communication channels, but we can still improve security in many use cases. The paper focuses on two key use cases:
- A confined component running in its own security domain, connected to the rest of the system by explicit (e.g. IPC) input and output channels. “To avoid the interconnect channel, we have to assume the system either runs on a single core (at least while the sensitive code is executing), or co-schedules domains across the core, such that at any time only one domain executes.“
- Preventing side-channel attacks between VMs hosted on public cloud infrastructure. Hyperthreading must either be disabled, or all hyperthreads of a core must belong to the same VM.
These two threats can be mitigated by the introduction of time protection at the OS level:
Time protection: a collection of OS mechanisms which jointly prevent interference between security domains that would make execution speed in one domain dependent on the activities of another.
The five requirements of Time Protection
Enforcement of a system’s security policy must not depend on correct application behaviour. Hence time protection, like memory protection, must be a mandatory (black-box) OS security enforcement mechanism. In particular, only mandatory enforcement can support confinement.
Time protection is based on preventing resource sharing. There are two strategies for this: some classes of resource (e.g. cache) can be partitioned across domains; for those that are instead time-multiplexed, we have to flush them during domain switches. Assuming that a core is not pinned to a single domain, then we have our first requirement:
Requirement 1: When time-sharing a core, the OS must flush on-core microarchitectural state on domain switch, unless the hardware supports partitioning such state.
Spatial partitioning of physical memory frames can be achieved using page colouring. This ensures that a particular page can only ever be resident in a specific section of the cache, referred to as the “colour” of the page. Typically LLC and L2 caches can be coloured this way, but the smaller L1 caches and other on-core state such as the TLP and BP cannot. So these on-core caches must be flushed on a domain switch.
The code and data of the kernel itself can also be used as a timing channel. To protect against this:
Requirement 2: Each domain must have its own private copy of OS text, stack and (as much as possible) global data.
All dynamically allocated kernel memory is provided by userland, and hence will be coloured. This leaves a small amount of global kernel data uncoloured…
Requirement 3: Access to any remaining OS shared data must be sufficiently deterministic to avoid information leakage.
Even when we do flush caches, the latency of flushing can itself be used as a channel! (Since it forces a write-back of all dirty lines).
Requirement 4: State flushing must be padded to its worst-case latency
And finally, since interrupts can also be used for a covert channel:
Requirement 5: When sharing a core, the OS must disable or partition any interrupts other than the preemption timer.
Implementation in seL4
The authors demonstrate how to satisfy these five requirements in an adapted version of seL4. Each domain is given its own copy of the kernel, using a kernel clone mechanism which creates a copy of a kernel image in user-supplied data, including a stack and replicas of almost all kernel data. Two kernels share one the minimum static date required for handing over the processor. The Kernel_SetInt system call allows IRQs to be associated with a kernel, such that kernels cannot trigger interrupts across partition boundaries (see §4.2).
Domain switches happen implicitly on a preemption interrupt. When this happens the stack needs to be switched, and then all on-core microarchitectural state is flushed. The kernel defers returning until a configured time has elapsed (requirement 4). Kernel cloning ensures that kernels share very little data. For what remains, requirement 3 is satisfied by carefully pre-fetching all shared data before returning to userland, by touching each cache line. All interrupts are masked before switching the kernel stack, and after the switch only those associated with the new kernal are unmasked.
Evaluation
The evaluation addresses two main questions: do the time protection mechanisms outlined above actually protect against covert and side channels as intended, and how much performance overhead do they add?
Preventing information leaks
Information leakage is quantified using mutual information as the measure of the size of a channel. Experiments are conducted on both x86 and Arm v7. (Note that in the Arm v8 architecture cores contain architectural state that cannot be scrubbed by architected means and thus contain uncloseable high bandwidth channels).
Compare the top and bottom plots on the figure below. The top graph shows mutual information through an LLC covert channel without protection, and the bottom plot shows the mutual information with the time protection enhancements in place.
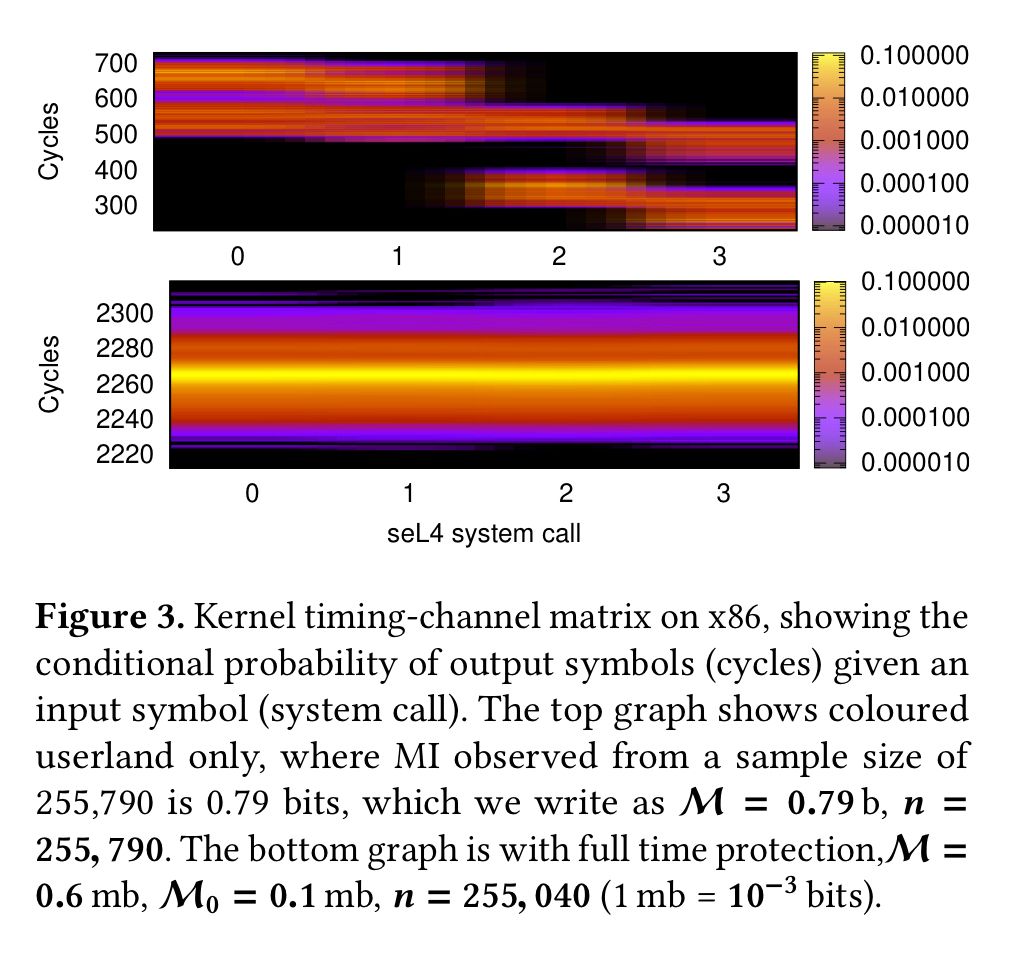
Without protection, the kernel channel can transmit 395 b/s. With protection the channel disappears.
The following table shows the mutual information capacity of raw (unprotected) caches, the results of a full flush, and the results with time protection enabled.
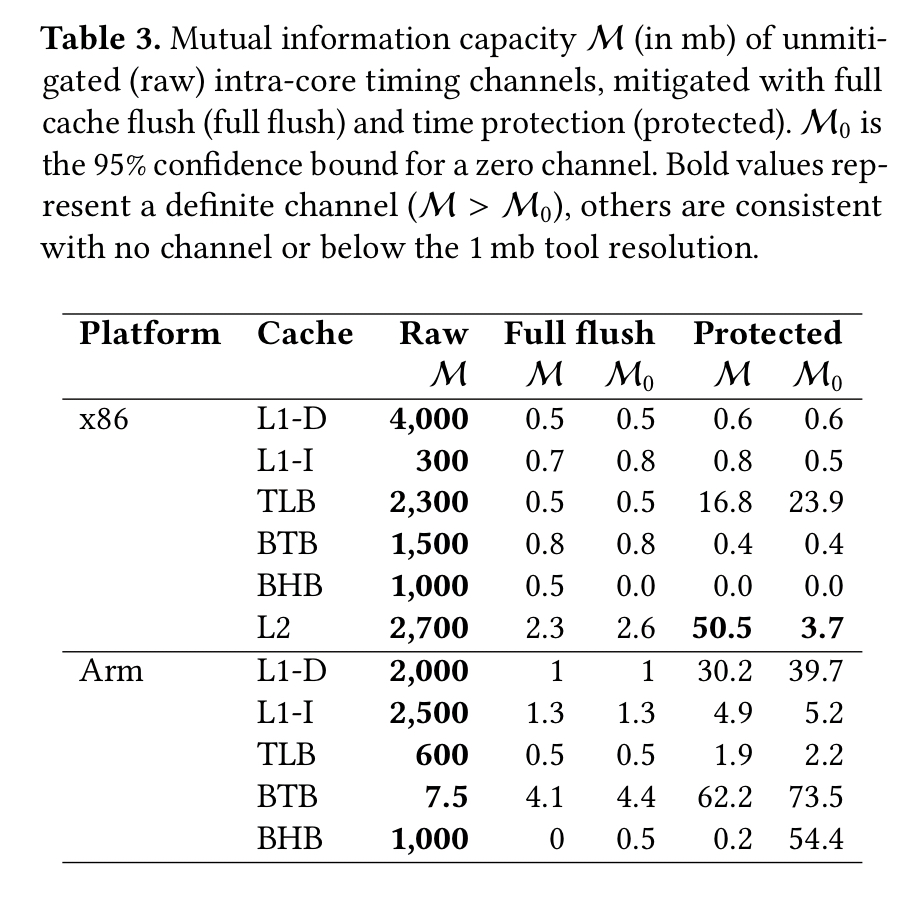
The residual L2 channel on Haswell is closed by a full flush, but not by the time protection mechanisms. Disabling the data prefetcher substantially reduces the channel, the remaining small channel “likely results from the instruction prefetcher, which cannot be disabled.”
Performance overhead
Across a set of IPC microbenchmarks, the overhead of time protection is remarkably small on x86, and within 15% on Arm.
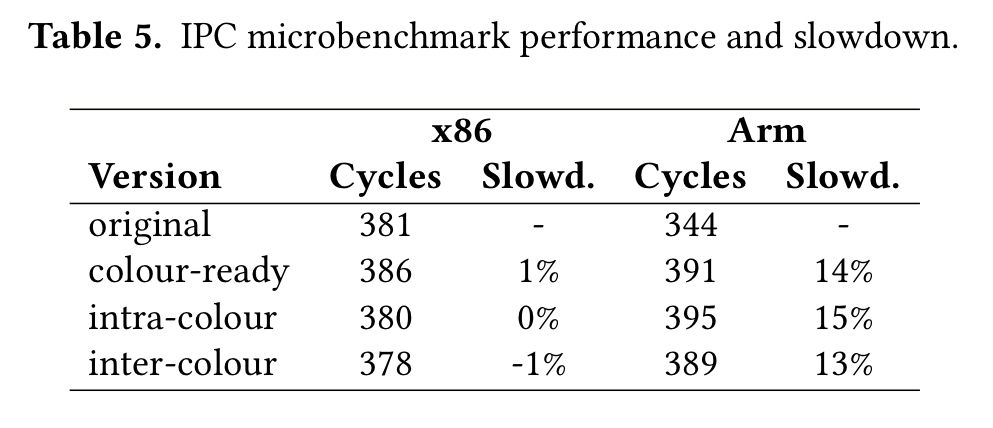
The Arm cost is attributed to kernel clone operations, with the 4-way associativity of Arm v8 cores the expectation is that the overhead will be significantly reduced.
The following table further shows the impact on domain switching:
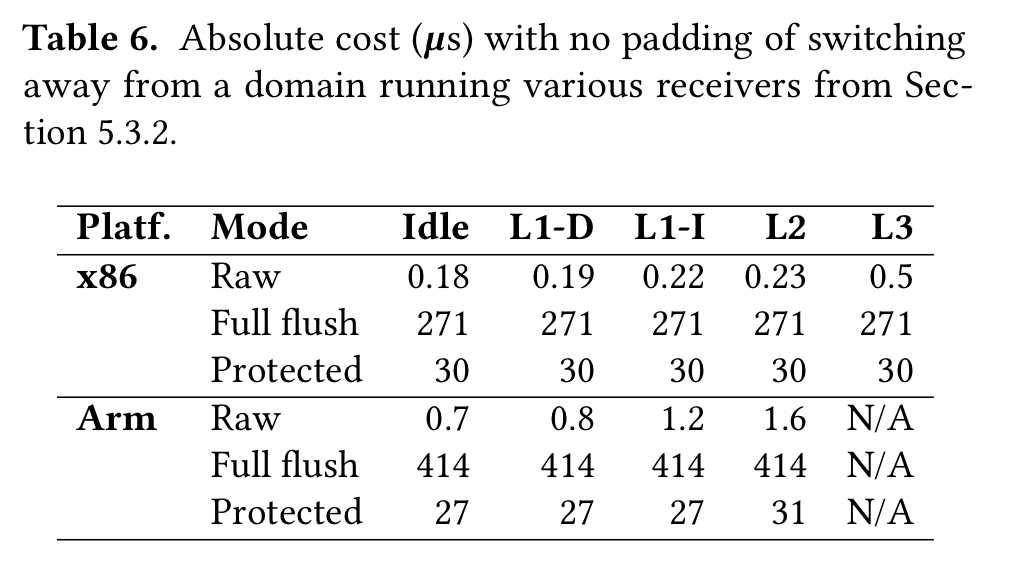
…the results show that our implementation of time protection imposes significantly less overhead than the full flush, despite being as effective in removing timing channels…
The overall cost of cloning is a fraction of the cost of creating a process.
What next?
Time protection is obviously at the mercy of hardware, and not all hardware provides sufficient support for full temporal isolation. We have seen this with the x86 L2 channel in Table 3, which we could not close… The results reinforce the need for a new, security-oriented hardware-software contract…:
- the OS must be able to partition or flush any shared hardware resource
- concurrently-accessed resources must be partitioned
- virtually-addressed state must be flushed
The most obvious weakness of current hardware in this regard is in the interconnects.
The ultimate aim of the authors is to produce a verified seL4 with time protection.