The crux of voice (in)security: a brain study of speaker legitimacy detection Neupane et al., NDSS’19
The key results of this paper are easy to understand, but the implications are going to take us a long time to unravel. Speech morphing (voice morphing) is the process of translating a speaker’s voice to sound like a given impersonation target. This capability is now available off-the-shelf —this paper uses the CMU Festvox voice converter— and is getting better all the time. Being able to impersonate someone’s voice takes things like social engineering attacks to a whole new level…
…voice imitation is an emerging class of threats, especially given the advancement in speech synthesis technology seen in a variety of contexts that can harm a victim’s reputation and her security/safety. For instance, the attacker could publish the morphed voice samples on social media, impersonate the victim in phone conversations, leave fake voice messages to the victim’s contacts, and even launch man-in-the-middle attacks against end-to-end encryption technologies that require users to verify the voices of the callers, to name a few instances of such attacks.
So voice should sit alongside images and video as a source we can’t trust in our new post-reality world. (It seems especially powerful when you combine e.g. voice impersonation and video). But that’s something we already knew. It turns out though that voice may be a particularly devastating attack vector because ‘deep down,’ inside our brains, we genuinely can’t tell the difference between a real voice and a morphed voice impersonating it.
Previous studies have investigated brain activity when users are looking at real and fake websites and images, and found that “subconscious neural differences exist when users are subject to real vs. fake artifacts, even though users themselves may not be able to tell the two apart behaviorally.” The work reported in this paper began with the hypothesis that there should be similar neural differences between listening to the original and fake voices of a speaker. Despite trying really hard though, no such difference could be detected!
Our key insight is that there may be no statistically significant differences in the way the human brain processes the legitimate speakers vs synthesized speakers, whereas clear differences are visible when encountering legitimate vs different other human speakers… Overall, our work … reveals user’s susceptibility to voice synthesis attacks at a biological level.
However much we teach people to be on the lookout for voice impersonation, it seems they’re not going to be able to reliably detect it; especially as voice synthesis techniques will continue to improve. So to defend against voice impersonation attacks we’re going to need machine assistance. But if voice synthesis is trained in an adversarial style, will even that be possible?
If there’s a silver lining to be found here then perhaps it’s this: the fact that we can’t tell the difference suggests that current morphing technology may be ready to serve those who have lost their voices.
Analysing neural activity using fNIRS
Neural activity is studied using functional near-infrared spectroscopy (fNIRS). fNIRS is a non-invasive imaging method (using lots of external probes as per the image below) which measures the relative concentration of oxygenated hemoglobin (oxy-Hb) and dexoygenated hemoglobin (deoxy-Hb) in the brain cortex. It provides better temporal resolution than an fMRI —without requiring the subject to be in a supine position in a scanner— and better spatial resolution than an EEG.
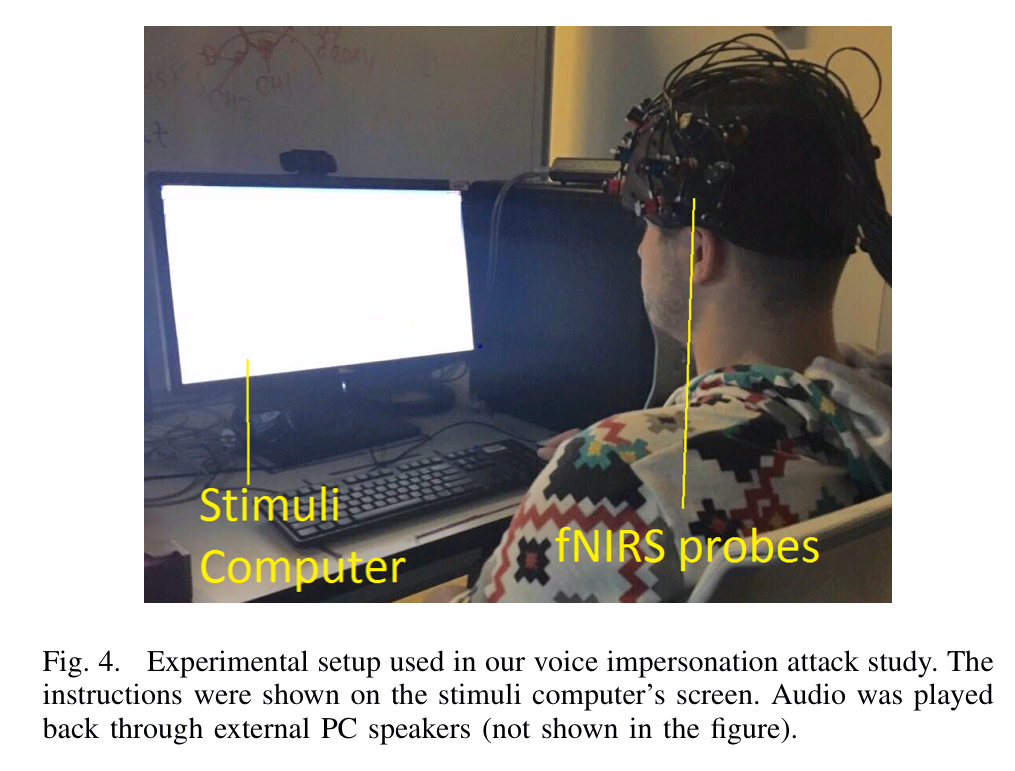
Experiment set-up
Voice samples were collected from the Internet for Oprah Winfrey and Morgan Freeman (both of whom have very distinctive and easily recognisable voices).
Then twenty American speakers recruited via Amazon Mechanical Turk were recruited to record the speech of these two celebrities in their own voices, imitating as best they could the original speaking style, pace and emotion. One male and one female speaker from among these twenty was then selected (how?), and their speech was fed through the CMU Festvox voice converter to generated morphed versions of the voices of Morgan Freeman and Oprah Winfrey.
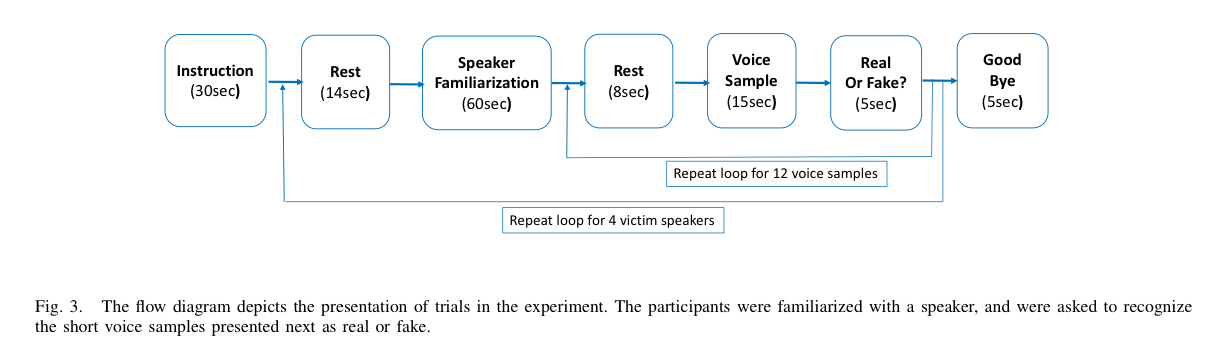
Twenty experiment participants were then recruited: 10 male, and 10 female; all English speaking and in the age range 19-36. Each participant was familiarised with the voice of a victim speaker for 1 minute, and then played 12 randomly selected speech samples: 4 in the original speaker’s voice, 4 in a morphed voice designed to impersonate the original speaker, and 4 in a different speakers voice. The participants were asked to identify the legitimate and fake voices of the victim speakers, but were not explicitly told about voice morphing technology.
The experiment was conducted 4 times for each participant: twice with one of the celebrity voices as the victim, and twice with a voice for which they were ‘briefly familiar’ – i.e., only encountered for the first time during the experiment.
While all this was going on, the fNIRS probe-cap captured brain activity in the following regions of the brain:

Key results
With the original voices, participants were correctly able to identify the speaker as the victim voice 82% of the time. The morphed voices were (incorrectly) identified as the authentic victim’s voice 58% of the time. As a baseline, the different voice impersonating the original speaker was (incorrectly) identified as the authentic victim’s voice 33% of the time.
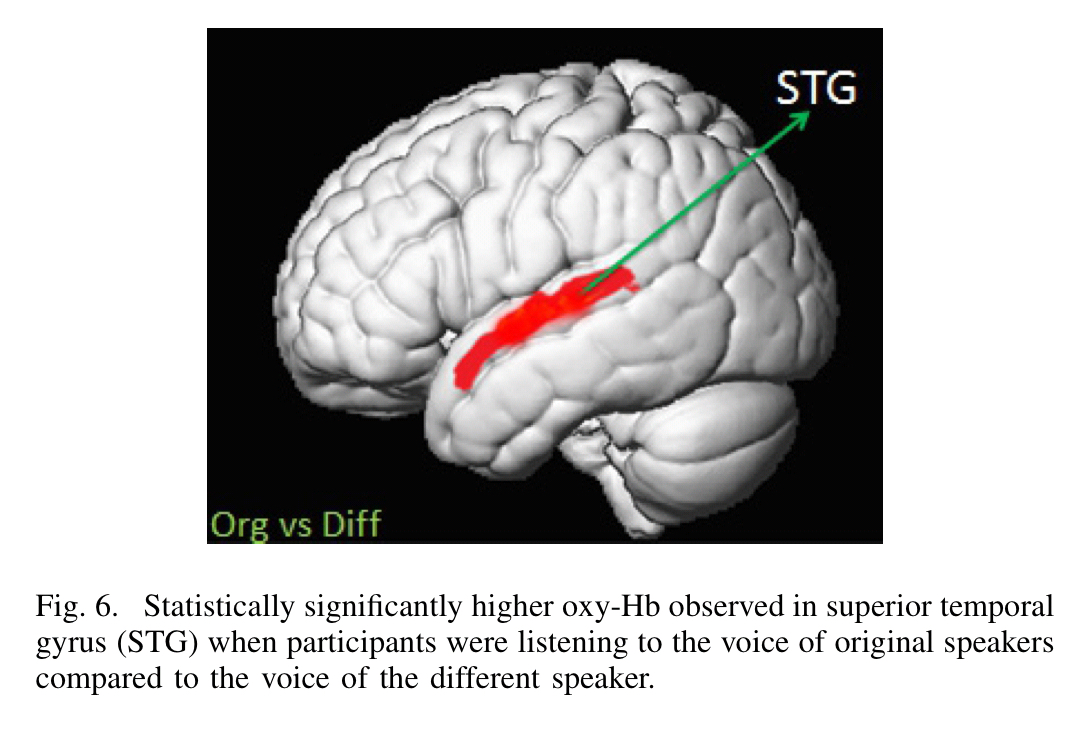
When comparing the neural activation in the brain between original speaker speech samples and the morphed voice impersonating that speaker, no statistically significant differences were observed. At this point you might be thinking “perhaps the experiment just didn’t monitor the part of the brain where the difference shows” (I certainly was). And that’s still a possibility. However, comparing the neural activation between an original speaker speech sample and a different voice impersonating the speaker did show statistically significant differences. I.e., the probes were at least measuring brain activity in some of the areas that matter!
Differences were also observed in brain activation between familiar voices (the celebrities) and the ‘briefly familiar’ voices (those they were exposed to only as part of the experiment). Famous speakers led to higher activation in the frontopolar area and middle temporal gyrus.
Having failed to detect any statistically significant difference in brain activity for real and morphed voices using traditional statistical techniques, the authors then tried training a machine learning classifier on the brain activation data to see if it could learn to distinguish. The best performing model only achieved 53% accuracy. I.e., there genuinely seems to be nothing in the captured brain activity that can tell the difference between the two cases.
A final thought:
Since this potential indistinguishability of real vs. morphed lies at the core of human biology, we posit that the problem is very severe, as the human detection of synthesized attacks may not improve over time with evolution. Further, in our study, we use an off-the-shelf, academic voice morphing tool based on voice conversion, CMU Festvox, whereas with the advancement in the voice synthesizing technologies (e.g., newer voice modeling techniques such as those offered by Lyrebird and Google WaveNet), it might become even more difficult for users to identify such attacks. Also, our study participants are mostly young individuals and with no reported hearing disabilities, while older population samples and/or those having hearing disabilities may be more prone to voice synthesis attacks.
Bear in mind that participants in the study, while not primed on voice morphing technology, were explicitly asked to try to distinguish between real and impersonated voices. In a real-world attack are unlikely to be so attuned to the possibility of impersonation.