Amazon Aurora: design considerations for high throughput cloud-native relational databases Verbitski et al., SIGMOD’17
Werner Vogels recently published a blog post describing Amazon Aurora as their fastest growing service ever. That post provides a high level overview of Aurora and then links to two SIGMOD papers for further details. Also of note is the recent announcement of Aurora serverless. So the plan for this week on The Morning Paper is to cover both of these Aurora papers and then look at Calvin, which underpins FaunaDB.
Say you’re AWS, and the task in hand is to take an existing relational database (MySQL) and retrofit it to work well in a cloud-native environment. Where do you start? What are the key design considerations and how can you accommodate them? These are the questions our first paper digs into. (Note that Aurora supports PostgreSQL as well these days).
Here’s the starting point:
In modern distributed cloud services, resilience and scalability are increasingly achieved by decoupling compute from storage and by replicating storage across multiple nodes. Doing so lets us handle operations such as replacing misbehaving or unreachable hosts, adding replicas, failing over from a writer to a replica, scaling the size of a database instance up or down, etc.
So we’re somehow going to take the backend of MySQL (InnoDB) and introduce a variant that sits on top of a distributed storage subsystem. Once we’ve done that, network I/O becomes the bottleneck, so we also need to rethink how chatty network communications are.
Then there are a few additional requirements for cloud databases:
- SaaS vendors using cloud databases may have numerous customers of their own. Many of these vendors use a schema/database as the unit of tenancy (vs a single schema with tenancy defined on a per-row basis). “As a result, we see many customers with consolidated databases containing a large number of tables. Production instances of over 150,000 tables for small databases are quite common. This puts pressure on components that manage metadata like the dictionary cache.”
- Customer traffic spikes can cause sudden demand, so the database must be able to handle many concurrent connections. “We have several customers that run at over 8000 connections per second.”
- Frequent schema migrations for applications need to be supported (e.g. Rails DB migrations), so Aurora has an efficient online DDL implementation.
- Updates to the database need to be made with zero downtime
The big picture for Aurora looks like this:
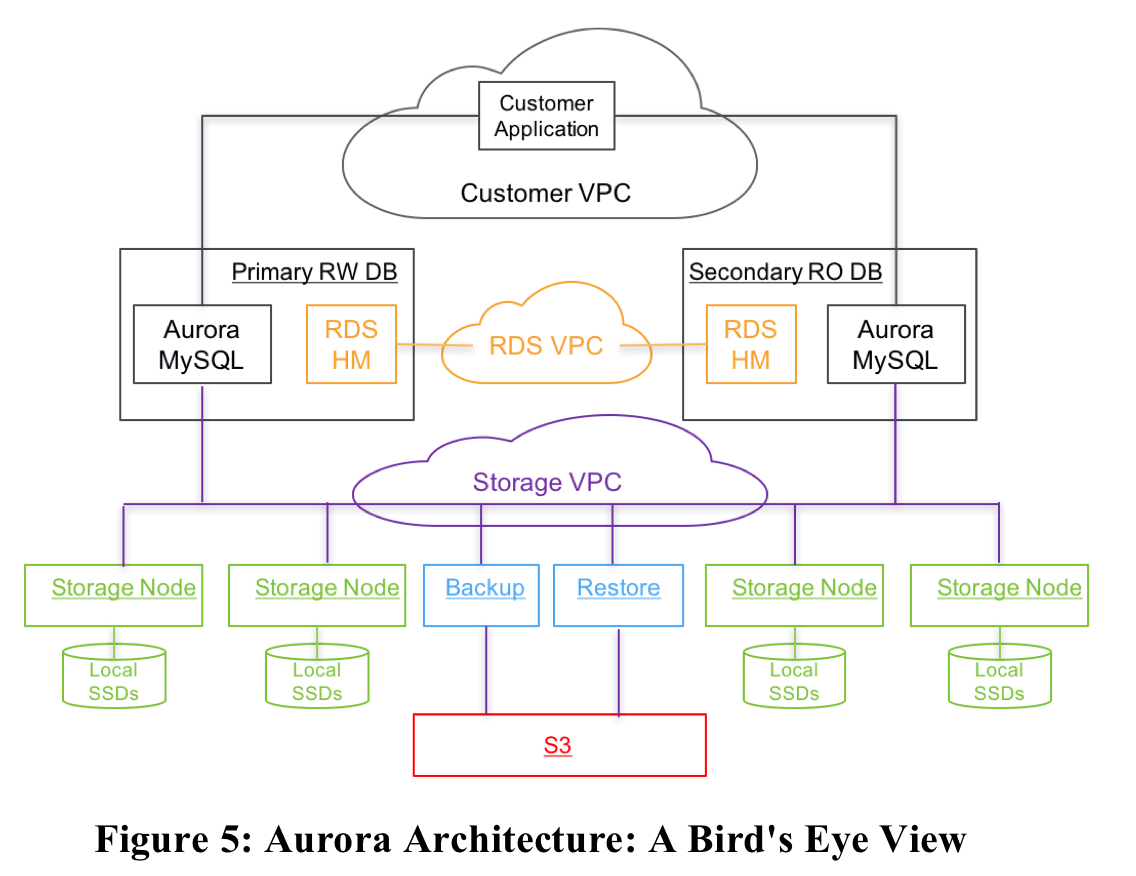
The database engine as a fork of “community” MySQL/InnoDB and diverges primarily in how InnoDB reads and writes data to disk.
There’s a new storage substrate (we’ll look at that next), which you can see in the bottom of the figure, isolated in its own storage VPC network. This is deployed on a cluster of EC2 VMs provisioned across at least 3 AZs in each region. The storage control plane uses Amazon DynamoDB for persistent storage of cluster and storage volume configuration, volume metadata, and S3 backup metadata. S3 itslef is used to store backups.
Amazon RDS is used for the control plane, including the RDS Host Manager (HM) for monitoring cluster health and determining when failover is required.
It’s nice to see Aurora built on many of the same foundational components that are available to us as end users of AWS too.
Durability at scale
The new durable, scalable storage layer is at the heart of Aurora.
If a database system does nothing else, it must satisfy the contract that data, once written, can be read. Not all systems do.
Storage nodes and disks can fail, and at large scale there’s a continuous low level background noise of node, disk, and network path failures. Quorum-based voting protocols can help with fault tolerance. With 






We believe 2/3 quorums are inadequate [even when the three replicas are each in a different AZ]… in a large storage fleet, the background noise of failures implies that, at any given moment in time, some subset of disks or nodes may have failed and are being repaired. These failures may be spread independently across nodes in each of AZ A, B, and C. However, the failure of AZ C, due to a fire, roof failure, flood, etc., will break quorum for any of the replicas that concurrently have failures in AZ A or AZ B.
Aurora is designed to tolerate the loss of an entire AZ plus one additional node without losing data, and an entire AZ without losing the ability to write data. To achieve this data is replicated six ways across 3 AZs, with 2 copies in each AZ. Thus 
Given this foundation, we want to ensure that the probability of double faults is low. Past a certain point, reducing MTTF is hard. But if we can reduce MTTR then we can narrow the ‘unlucky’ window in which an additional fault will trigger a double fault scenario. To reduce MTTR, the database volume is partitioned into small (10GB) fixed size segments. Each segment is replicated 6-ways, and the replica set is called a Protection Group (PG).
A storage volume is a concatenated set of PGs, physically implemented using a large fleet of storage nodes that are provisioned as virtual hosts with attached SSDs using Amazon EC2… Segments are now our unit of independent background noise failure and repair.
Since a 10GB segment can be repaired in 10 seconds on a 10Gbps network link, it takes two such failures in the same 10 second window, plus a failure of an entire AZ not containing either of those two independent failures to lose a quorum. “At our observed failure rates, that’s sufficiently unlikely…”
This ability to tolerate failures leads to operational simplicity:
- hotspot management can be addressed by marking one or more segments on a hot disk or node as bad, and the quorum will quickly be repaired by migrating it to some other (colder) node
- OS and security patching can be handled like a brief unavailability event
- Software upgrades to the storage fleet can be managed in a rolling fashion in the same way.
Combating write amplification
A six-way replicating storage subsystem is great for reliability, availability, and durability, but not so great for performance with MySQL as-is:
Unfortunately, this model results in untenable performance for a traditional database like MySQL that generates many different actual I/Os for each application write. The high I/O volume is amplified by replication.
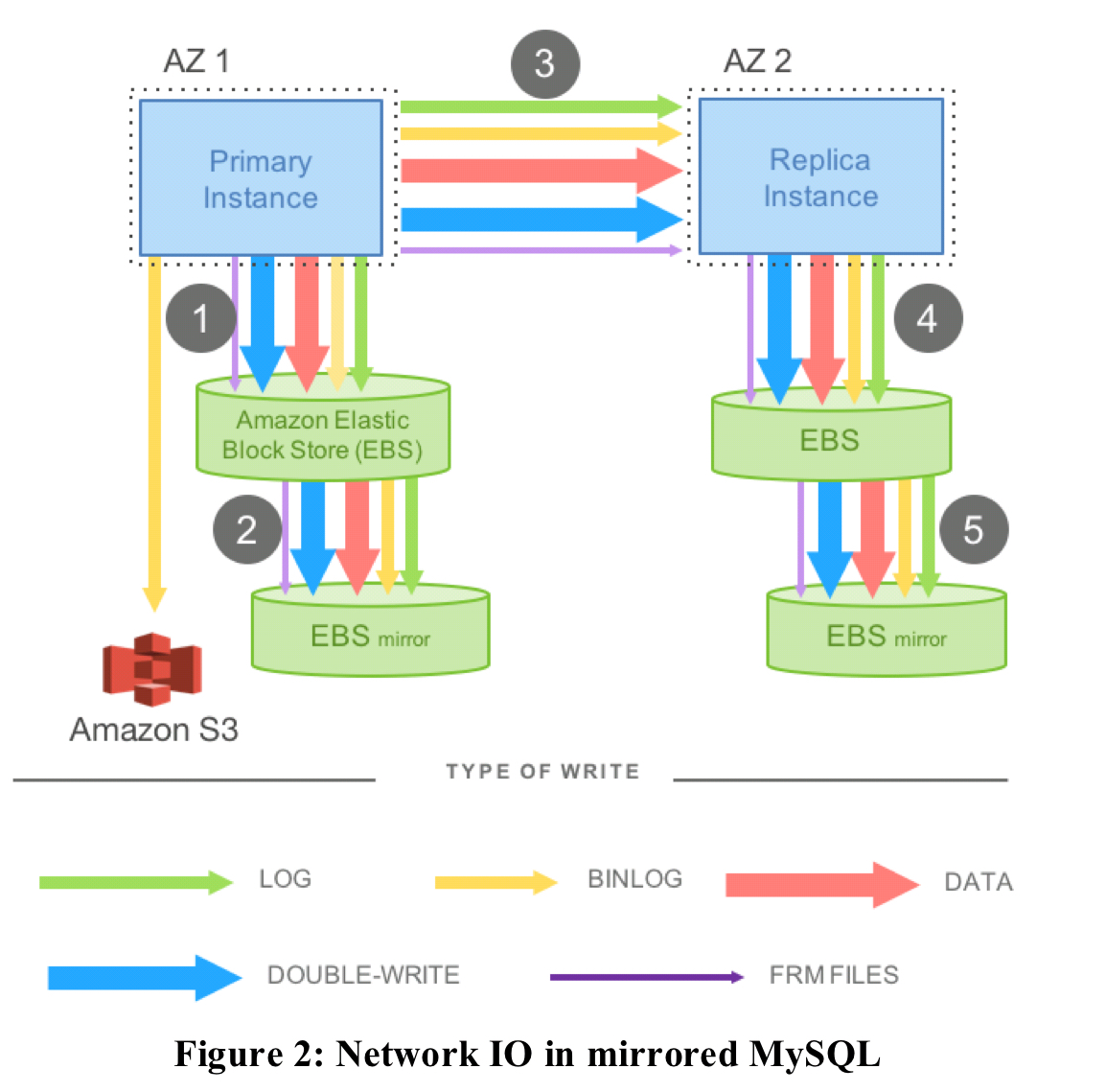
With regular MySQL, there are lots of writes going on as shown in the figure below (see §3.1 in the paper for a description of all the individual parts).
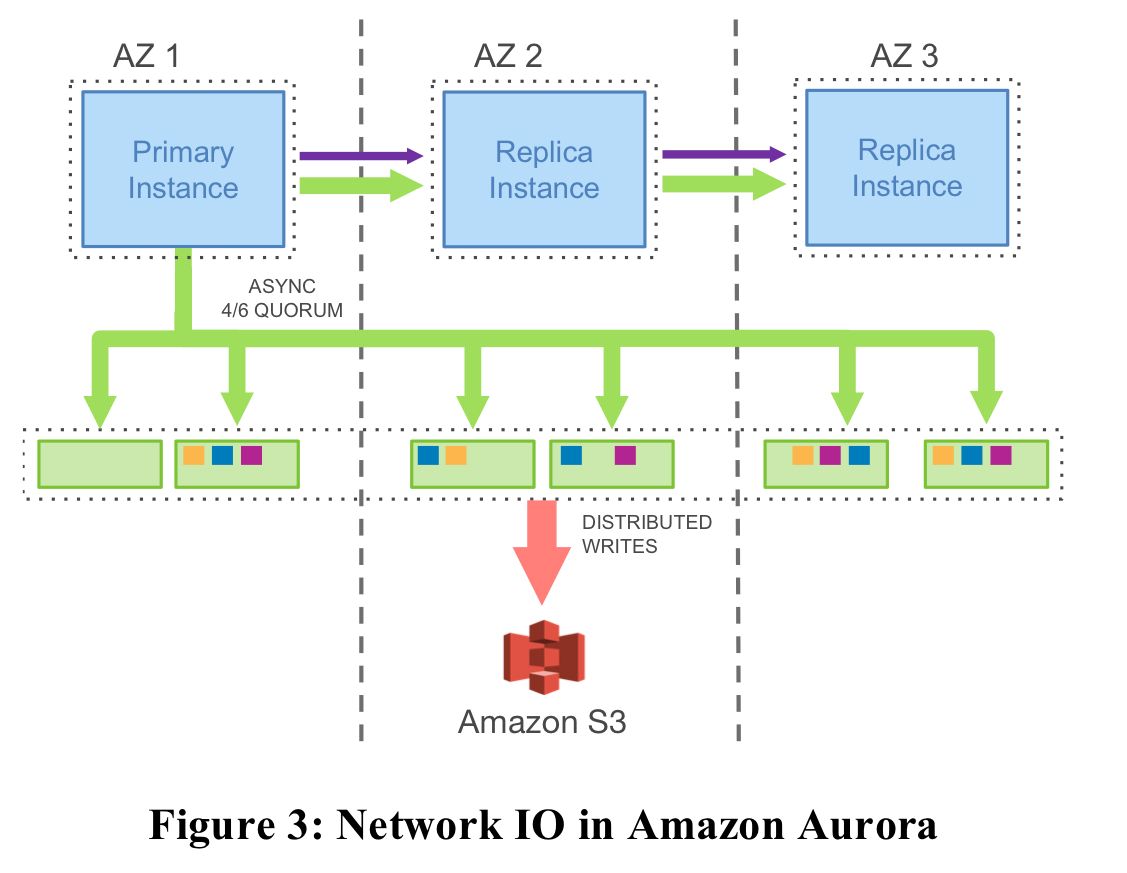
Aurora takes a different approach:
In Aurora, the only writes that cross the network are redo log records. No pages are ever written from the database tier, not for background writes, not for checkpointing, and not for cache eviction. Instead, the log applicator is pushed to the storage tier where it can be used to generate database pages in background or on demand.
Using this approach, a benchmark with a 100GB data set showed that Aurora could complete 35x more transactions than a mirrored vanilla MySQL in a 30 minute test.
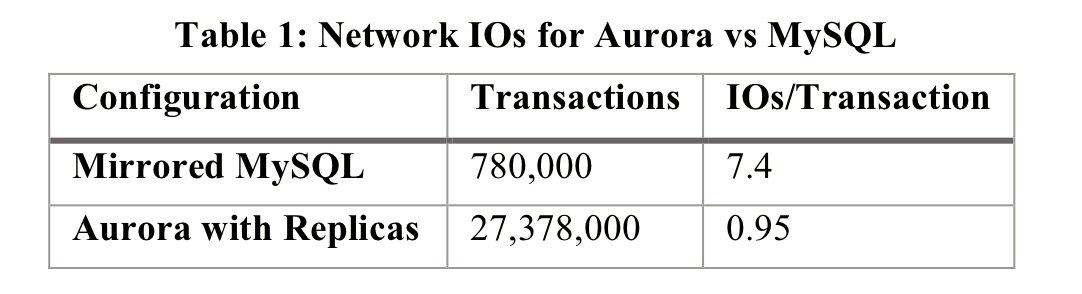
Using redo logs as the unit of replication means that crash recovery comes almost for free!
In Aurora, durable redo record application happens at the storage tier, continuously, asynchronously, and distributed across the fleet. Any read request for a data page may require some redo records to be applied if the page is not current. As a result, the process of crash recovery is spread across all normal foreground processing. Nothing is required at database startup.
Furthermore, whereas in a regular database more foreground requests also mean more background writes of pages and checkpointing, Aurora can reduce these activities under burst conditions. If a backlog does build up at the storage system then foreground activity can be throttled to prevent a long queue forming.
The complete IO picture looks like this:
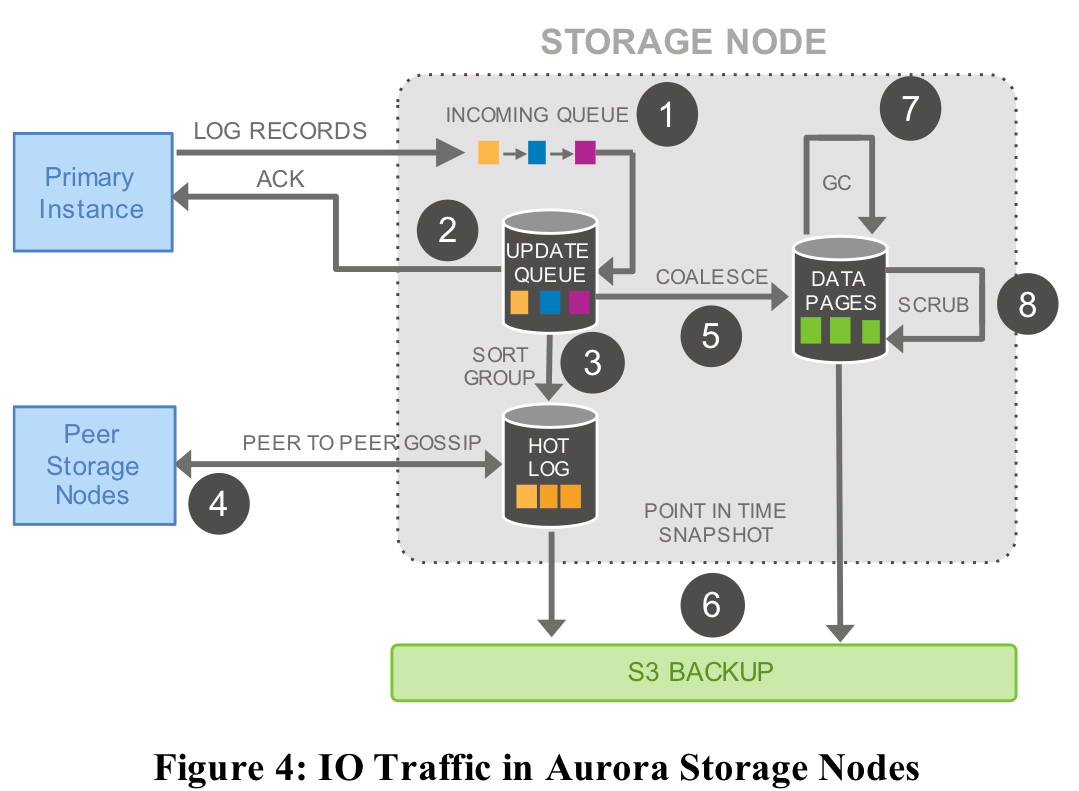
Only steps 1 and 2 above are in the foreground path.
The distributed log
Each log record has an associated Log Sequence Number (LSN) – a monotonically increasing value generated by the database. Storage nodes gossip with other members of their protection group to fill holes in their logs. The storage service maintains a watermark called the VCL (Volume Complete LSN), which is the highest LSN for which it can guarantee availablity of all prior records. The database can also define consistency points through consistency point LSNs (CPLs). A consistency point is always less than the VCL, and defines a durable consistency checkpoint. The most recent consistency point is called the VDL (Volume Durable LSN). This is what we’ll roll back to on recovery.
The database and storage subsystem interact as follows:
- Each database-level transaction is broken up into multiple mini-transactions (MTRs) that are ordered and must be performed atomically
- Each mini-transaction is composed of multiple contiguous log records
- The final log record in a mini-transaction is a CPL
When writing, there is a constraint that no LSN be issued which is more than a configurable limit— the LSN allocation limit— ahead of the current VDL. The limit is currently set to 10 million. It creates a natural form of back-pressure to throttle incoming writes if the storage or network cannot keep up.
Reads are served from pages in a buffer cache and only result in storage I/O requests on a cache miss. The database establishes a read point: the VDL at the time the request was issued. Any storage node that is complete with respect to the read point can be used to serve the request. Pages are reconstructed using the same log application code.
A single writer and up to 15 read replicas can all mount a single shared storage volume. As a result, read replicas add no additional costs in terms of consumed storage or disk write operations.
Aurora in action
The evaluation in section 6 of the paper demonstrates the following:
- Aurora can scale linearly with instance sizes, and on the highest instance size can sustain 5x the writes per second of vanilla MySQL.
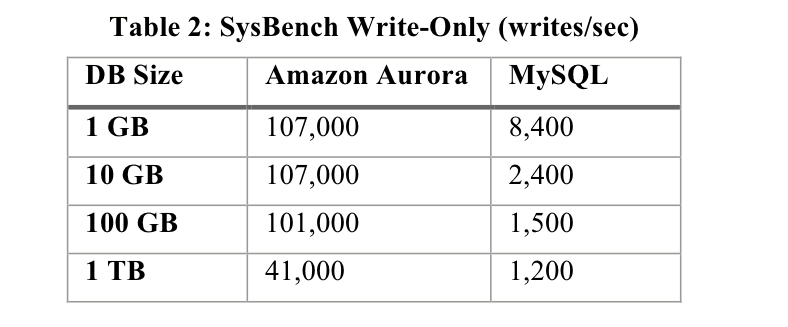
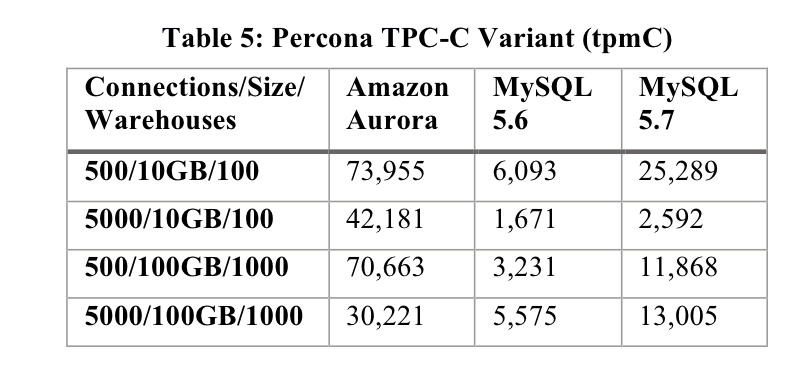
- Throughput in Aurora significantly exceeds MySQL, even with larger data sizes and out-of-cache working sets:
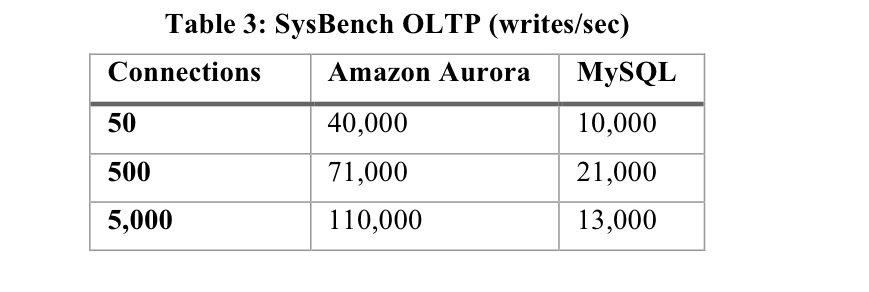
- Throughput in Aurora scales with the number of client connections:
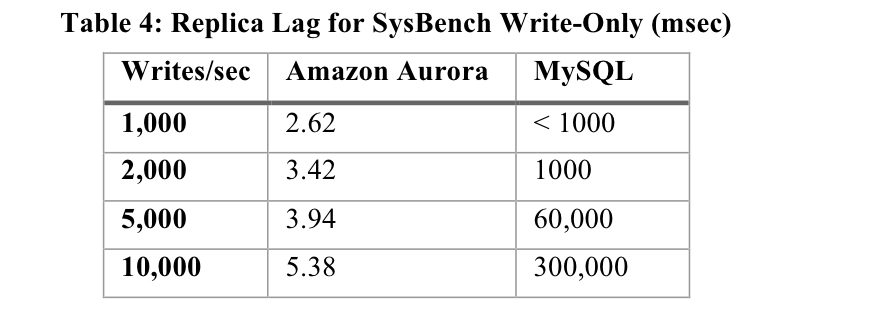
- The lag in an Aurora read replica is significantly lower than that of a MySQL replica, even with more intense workloads:
- Aurora outperforms MySQL on workloads with hot row contention:
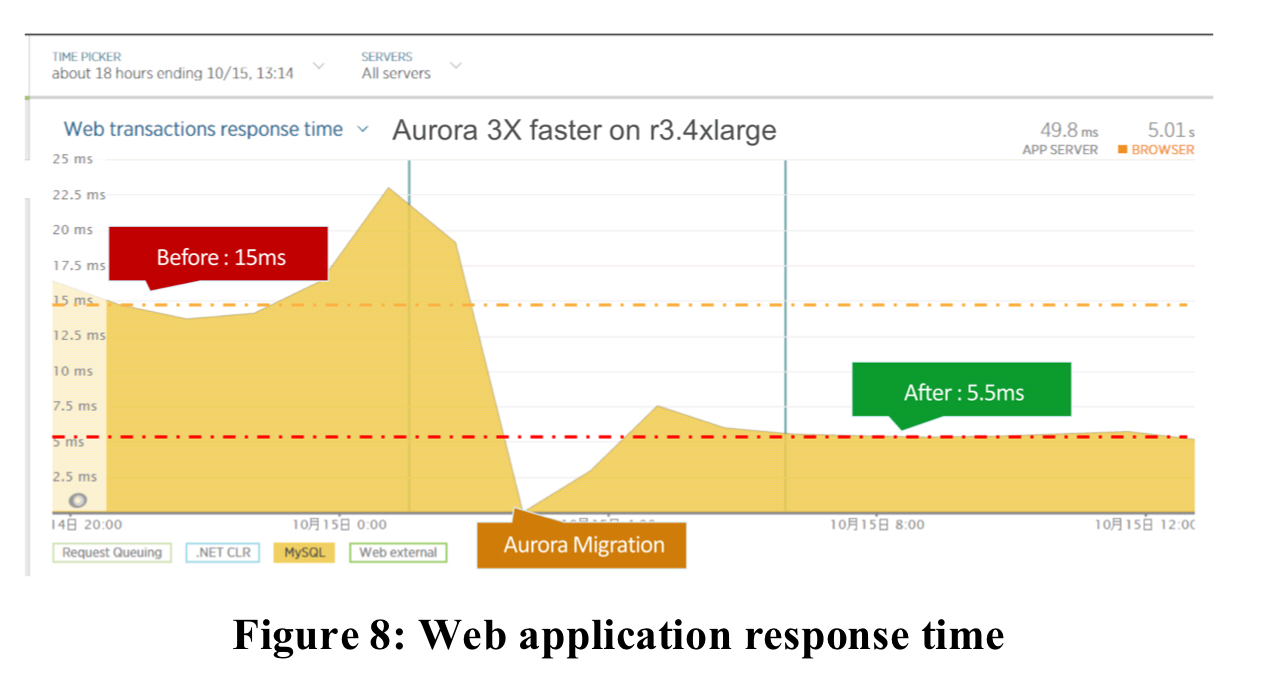
Customers migrating to Aurora see lower latency and practical elimination of replica lag (e.g, from 12 minutes to 20ms).